David Chushig-Muzo, Cristina Soguero-Ruiz, Pablo de Miguel Bohoyo, Inmaculada Mora-Jiménez
{"title":"Learning and visualizing chronic latent representations using electronic health records.","authors":"David Chushig-Muzo, Cristina Soguero-Ruiz, Pablo de Miguel Bohoyo, Inmaculada Mora-Jiménez","doi":"10.1186/s13040-022-00303-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Nowadays, patients with chronic diseases such as diabetes and hypertension have reached alarming numbers worldwide. These diseases increase the risk of developing acute complications and involve a substantial economic burden and demand for health resources. The widespread adoption of Electronic Health Records (EHRs) is opening great opportunities for supporting decision-making. Nevertheless, data extracted from EHRs are complex (heterogeneous, high-dimensional and usually noisy), hampering the knowledge extraction with conventional approaches.</p><p><strong>Methods: </strong>We propose the use of the Denoising Autoencoder (DAE), a Machine Learning (ML) technique allowing to transform high-dimensional data into latent representations (LRs), thus addressing the main challenges with clinical data. We explore in this work how the combination of LRs with a visualization method can be used to map the patient data in a two-dimensional space, gaining knowledge about the distribution of patients with different chronic conditions. Furthermore, this representation can be also used to characterize the patient's health status evolution, which is of paramount importance in the clinical setting.</p><p><strong>Results: </strong>To obtain clinical LRs, we considered real-world data extracted from EHRs linked to the University Hospital of Fuenlabrada in Spain. Experimental results showed the great potential of DAEs to identify patients with clinical patterns linked to hypertension, diabetes and multimorbidity. The procedure allowed us to find patients with the same main chronic disease but different clinical characteristics. Thus, we identified two kinds of diabetic patients with differences in their drug therapy (insulin and non-insulin dependant), and also a group of women affected by hypertension and gestational diabetes. We also present a proof of concept for mapping the health status evolution of synthetic patients when considering the most significant diagnoses and drugs associated with chronic patients.</p><p><strong>Conclusion: </strong>Our results highlighted the value of ML techniques to extract clinical knowledge, supporting the identification of patients with certain chronic conditions. Furthermore, the patient's health status progression on the two-dimensional space might be used as a tool for clinicians aiming to characterize health conditions and identify their more relevant clinical codes.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":" ","pages":"18"},"PeriodicalIF":6.1000,"publicationDate":"2022-09-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9446539/pdf/","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-022-00303-z","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 1
Abstract
Background: Nowadays, patients with chronic diseases such as diabetes and hypertension have reached alarming numbers worldwide. These diseases increase the risk of developing acute complications and involve a substantial economic burden and demand for health resources. The widespread adoption of Electronic Health Records (EHRs) is opening great opportunities for supporting decision-making. Nevertheless, data extracted from EHRs are complex (heterogeneous, high-dimensional and usually noisy), hampering the knowledge extraction with conventional approaches.
Methods: We propose the use of the Denoising Autoencoder (DAE), a Machine Learning (ML) technique allowing to transform high-dimensional data into latent representations (LRs), thus addressing the main challenges with clinical data. We explore in this work how the combination of LRs with a visualization method can be used to map the patient data in a two-dimensional space, gaining knowledge about the distribution of patients with different chronic conditions. Furthermore, this representation can be also used to characterize the patient's health status evolution, which is of paramount importance in the clinical setting.
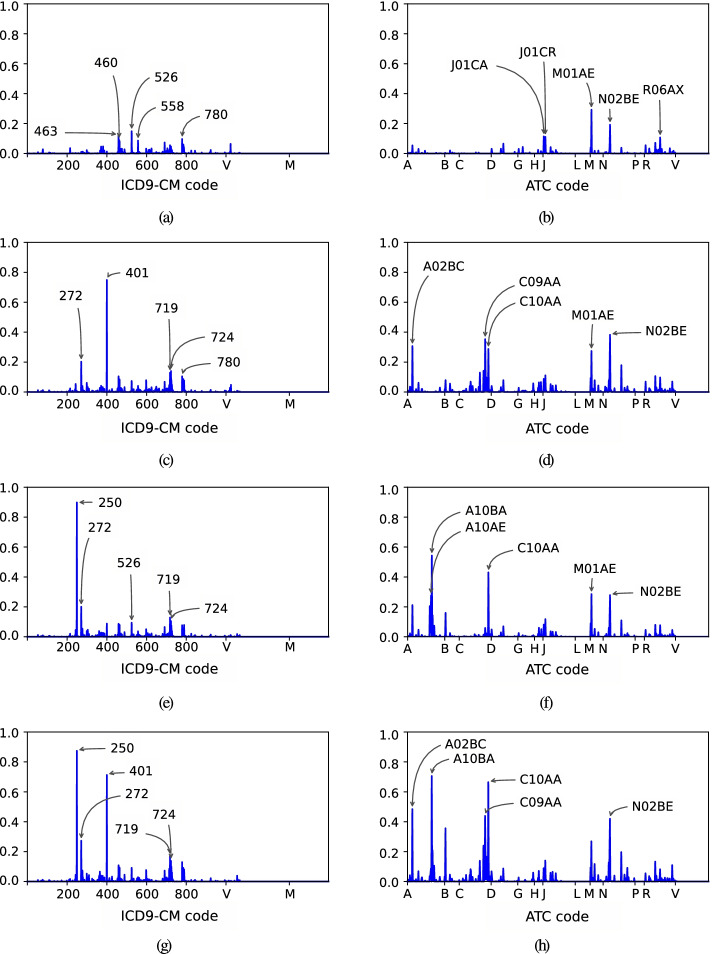
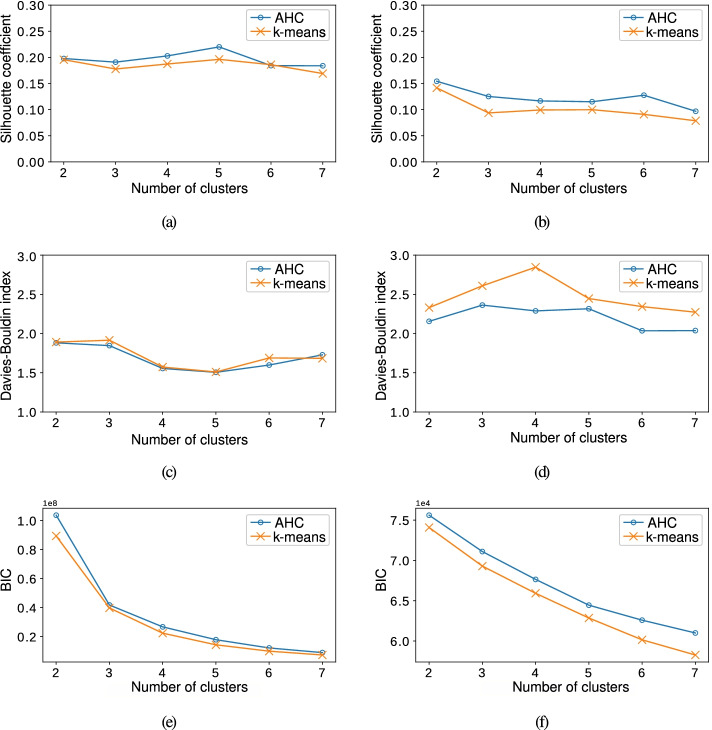
Results: To obtain clinical LRs, we considered real-world data extracted from EHRs linked to the University Hospital of Fuenlabrada in Spain. Experimental results showed the great potential of DAEs to identify patients with clinical patterns linked to hypertension, diabetes and multimorbidity. The procedure allowed us to find patients with the same main chronic disease but different clinical characteristics. Thus, we identified two kinds of diabetic patients with differences in their drug therapy (insulin and non-insulin dependant), and also a group of women affected by hypertension and gestational diabetes. We also present a proof of concept for mapping the health status evolution of synthetic patients when considering the most significant diagnoses and drugs associated with chronic patients.
Conclusion: Our results highlighted the value of ML techniques to extract clinical knowledge, supporting the identification of patients with certain chronic conditions. Furthermore, the patient's health status progression on the two-dimensional space might be used as a tool for clinicians aiming to characterize health conditions and identify their more relevant clinical codes.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
