{"title":"An unsupervised image segmentation algorithm for coronary angiography.","authors":"Zong-Xian Yin, Hong-Ming Xu","doi":"10.1186/s13040-022-00313-x","DOIUrl":null,"url":null,"abstract":"<p><p>Computer visual systems can rapidly obtain a large amount of data and automatically process them with ease. These characteristics constitute advantages for the application of such systems in the automatic analysis of medical images, as well as in processing technology. The precision of image segmentation, which plays a critical role in computer visual systems, directly affects the quality of processing results. Coronary angiographs feature various background colors, complex patterns, and blurry edges. The image areas containing blood vessels cannot be precisely segmented through regular methods. Therefore, this study proposed an unsupervised learning algorithm that uses regional parameter expansion (RPE). This method was derived from the flood fill algorithm, which can effectively segment image areas containing blood vessels despite a complex background or uneven light and shadow. An optimal cover tree (OCT) algorithm was proposed for the establishment of coronary arteries and the estimation of vessel diameter. Through the region growing method, spanning trees were used to record the cover length of adjacent connections, thereby establishing vessel paths, and the length can be used to track changes in vessel diameter.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":" ","pages":"27"},"PeriodicalIF":6.1000,"publicationDate":"2022-10-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9587570/pdf/","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-022-00313-x","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 2
Abstract
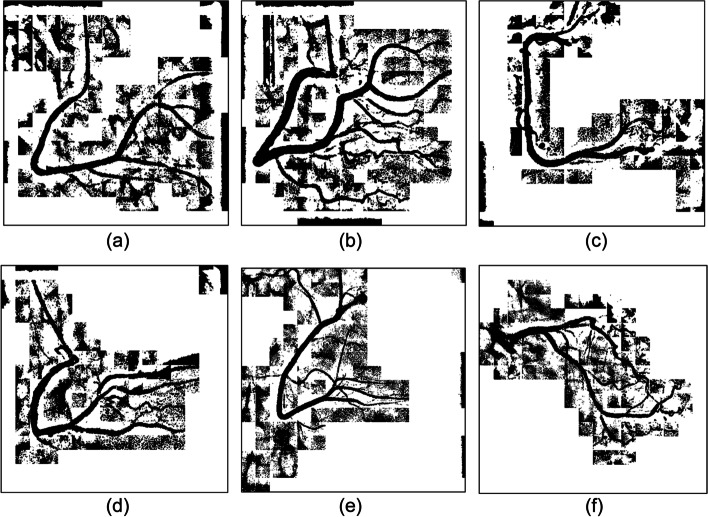
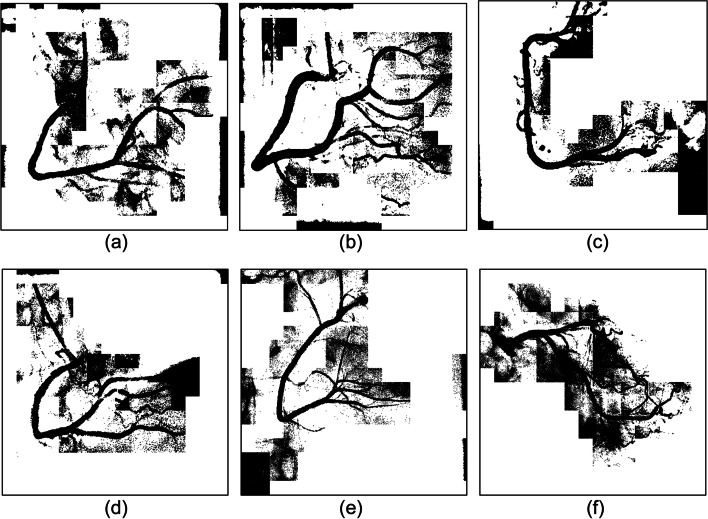
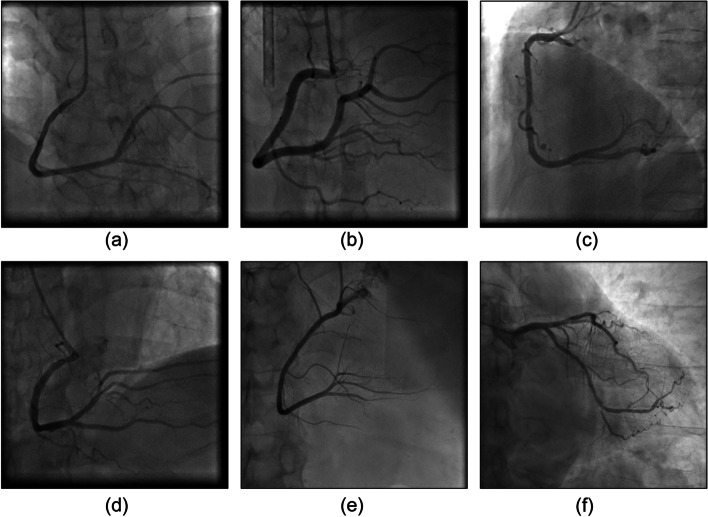
Computer visual systems can rapidly obtain a large amount of data and automatically process them with ease. These characteristics constitute advantages for the application of such systems in the automatic analysis of medical images, as well as in processing technology. The precision of image segmentation, which plays a critical role in computer visual systems, directly affects the quality of processing results. Coronary angiographs feature various background colors, complex patterns, and blurry edges. The image areas containing blood vessels cannot be precisely segmented through regular methods. Therefore, this study proposed an unsupervised learning algorithm that uses regional parameter expansion (RPE). This method was derived from the flood fill algorithm, which can effectively segment image areas containing blood vessels despite a complex background or uneven light and shadow. An optimal cover tree (OCT) algorithm was proposed for the establishment of coronary arteries and the estimation of vessel diameter. Through the region growing method, spanning trees were used to record the cover length of adjacent connections, thereby establishing vessel paths, and the length can be used to track changes in vessel diameter.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
