Hyunsuk Kim, Taesung Park, Jinyoung Jang, Seungyeoun Lee
{"title":"Comparison of survival prediction models for pancreatic cancer: Cox model versus machine learning models.","authors":"Hyunsuk Kim, Taesung Park, Jinyoung Jang, Seungyeoun Lee","doi":"10.5808/gi.22036","DOIUrl":null,"url":null,"abstract":"<p><p>A survival prediction model has recently been developed to evaluate the prognosis of resected nonmetastatic pancreatic ductal adenocarcinoma based on a Cox model using two nationwide databases: Surveillance, Epidemiology and End Results (SEER) and Korea Tumor Registry System-Biliary Pancreas (KOTUS-BP). In this study, we applied two machine learning methods-random survival forests (RSF) and support vector machines (SVM)-for survival analysis and compared their prediction performance using the SEER and KOTUS-BP datasets. Three schemes were used for model development and evaluation. First, we utilized data from SEER for model development and used data from KOTUS-BP for external evaluation. Second, these two datasets were swapped by taking data from KOTUS-BP for model development and data from SEER for external evaluation. Finally, we mixed these two datasets half and half and utilized the mixed datasets for model development and validation. We used 9,624 patients from SEER and 3,281 patients from KOTUS-BP to construct a prediction model with seven covariates: age, sex, histologic differentiation, adjuvant treatment, resection margin status, and the American Joint Committee on Cancer 8th edition T-stage and N-stage. Comparing the three schemes, the performance of the Cox model, RSF, and SVM was better when using the mixed datasets than when using the unmixed datasets. When using the mixed datasets, the C-index, 1-year, 2-year, and 3-year time-dependent areas under the curve for the Cox model were 0.644, 0.698, 0.680, and 0.687, respectively. The Cox model performed slightly better than RSF and SVM.</p>","PeriodicalId":36591,"journal":{"name":"Genomics and Informatics","volume":"20 2","pages":"e23"},"PeriodicalIF":0.0000,"publicationDate":"2022-06-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9299568/pdf/","citationCount":"4","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Genomics and Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.5808/gi.22036","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/6/30 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"Agricultural and Biological Sciences","Score":null,"Total":0}
引用次数: 4
Abstract
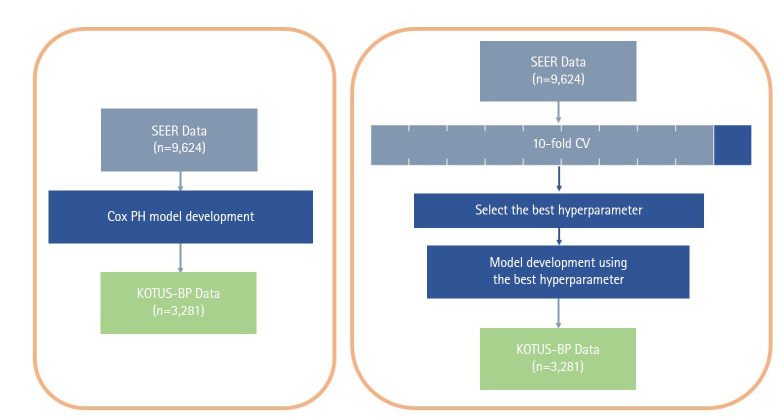
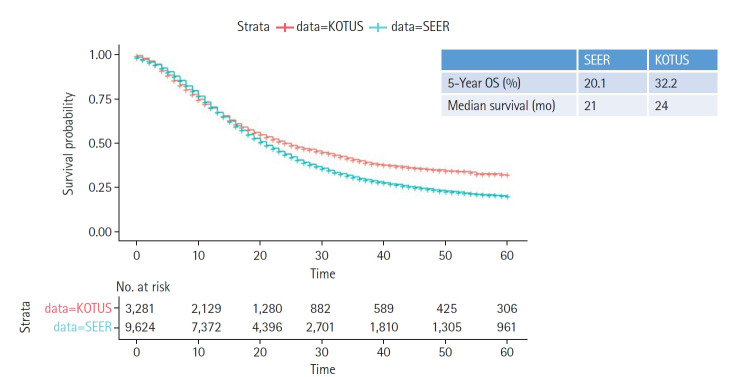
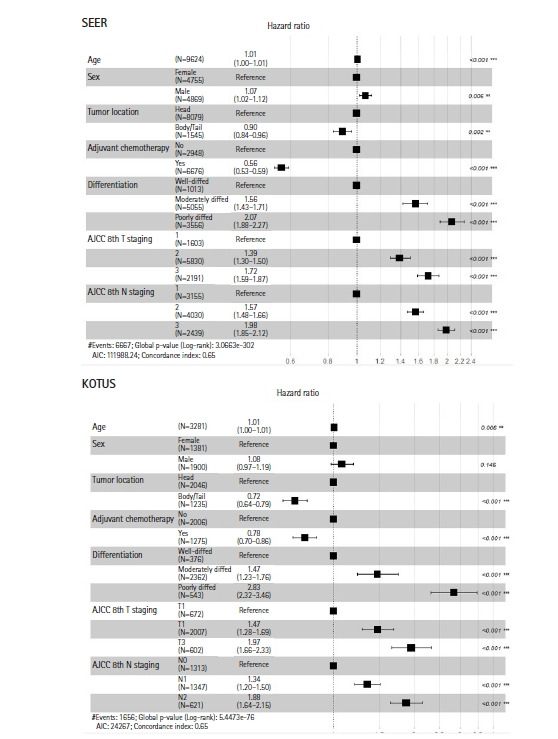
A survival prediction model has recently been developed to evaluate the prognosis of resected nonmetastatic pancreatic ductal adenocarcinoma based on a Cox model using two nationwide databases: Surveillance, Epidemiology and End Results (SEER) and Korea Tumor Registry System-Biliary Pancreas (KOTUS-BP). In this study, we applied two machine learning methods-random survival forests (RSF) and support vector machines (SVM)-for survival analysis and compared their prediction performance using the SEER and KOTUS-BP datasets. Three schemes were used for model development and evaluation. First, we utilized data from SEER for model development and used data from KOTUS-BP for external evaluation. Second, these two datasets were swapped by taking data from KOTUS-BP for model development and data from SEER for external evaluation. Finally, we mixed these two datasets half and half and utilized the mixed datasets for model development and validation. We used 9,624 patients from SEER and 3,281 patients from KOTUS-BP to construct a prediction model with seven covariates: age, sex, histologic differentiation, adjuvant treatment, resection margin status, and the American Joint Committee on Cancer 8th edition T-stage and N-stage. Comparing the three schemes, the performance of the Cox model, RSF, and SVM was better when using the mixed datasets than when using the unmixed datasets. When using the mixed datasets, the C-index, 1-year, 2-year, and 3-year time-dependent areas under the curve for the Cox model were 0.644, 0.698, 0.680, and 0.687, respectively. The Cox model performed slightly better than RSF and SVM.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
