Donald E Brown, Suchetha Sharma, James A Jablonski, Arthur Weltman
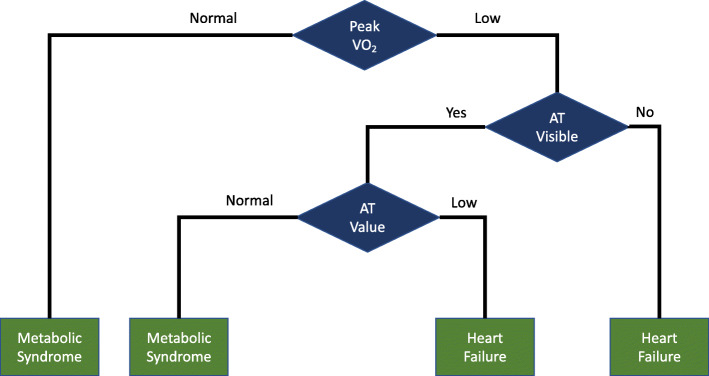
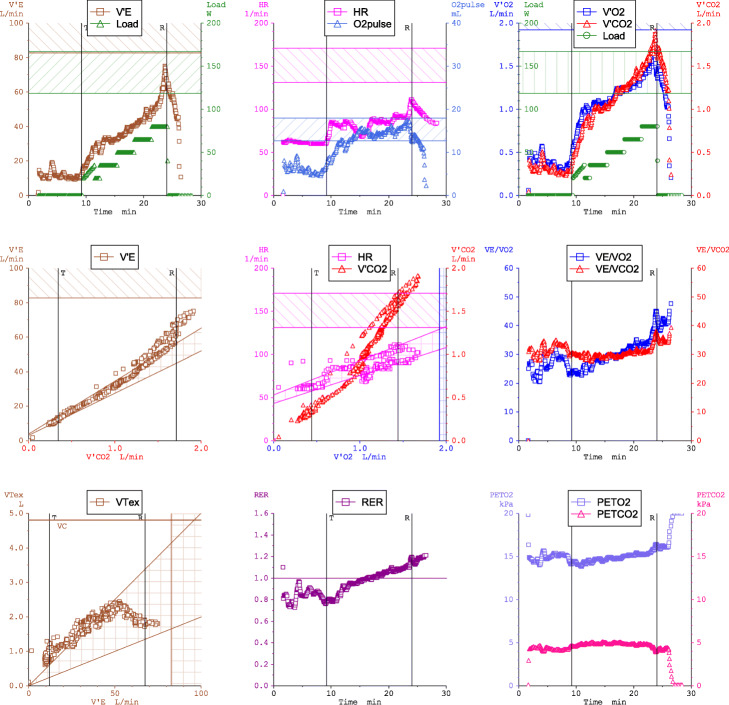
{"title":"Neural network methods for diagnosing patient conditions from cardiopulmonary exercise testing data.","authors":"Donald E Brown, Suchetha Sharma, James A Jablonski, Arthur Weltman","doi":"10.1186/s13040-022-00299-6","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Cardiopulmonary exercise testing (CPET) provides a reliable and reproducible approach to measuring fitness in patients and diagnosing their health problems. However, the data from CPET consist of multiple time series that require training to interpret. Part of this training teaches the use of flow charts or nested decision trees to interpret the CPET results. This paper investigates the use of two machine learning techniques using neural networks to predict patient health conditions with CPET data in contrast to flow charts. The data for this investigation comes from a small sample of patients with known health problems and who had CPET results. The small size of the sample data also allows us to investigate the use and performance of deep learning neural networks on health care problems with limited amounts of labeled training and testing data.</p><p><strong>Methods: </strong>This paper compares the current standard for interpreting and classifying CPET data, flowcharts, to neural network techniques, autoencoders and convolutional neural networks (CNN). The study also investigated the performance of principal component analysis (PCA) with logistic regression to provide an additional baseline of comparison to the neural network techniques.</p><p><strong>Results: </strong>The patients in the sample had two primary diagnoses: heart failure and metabolic syndrome. All model-based testing was done with 5-fold cross-validation and metrics of precision, recall, F1 score, and accuracy. As a baseline for comparison to our models, the highest performing flow chart method achieved an accuracy of 77%. Both PCA regression and CNN achieved an average accuracy of 90% and outperformed the flow chart methods on all metrics. The autoencoder with logistic regression performed the best on each of the metrics and had an average accuracy of 94%.</p><p><strong>Conclusions: </strong>This study suggests that machine learning and neural network techniques, in particular, can provide higher levels of accuracy with CPET data than traditional flowchart methods. Further, the CNN performed well with a small data set showing that these techniques can be designed to perform well on small data problems that are often found in health care and the life sciences. Further testing with larger data sets is needed to continue evaluating the use of machine learning to interpret CPET data.</p>","PeriodicalId":4,"journal":{"name":"ACS Applied Energy Materials","volume":" ","pages":"16"},"PeriodicalIF":5.5000,"publicationDate":"2022-08-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9375280/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"ACS Applied Energy Materials","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-022-00299-6","RegionNum":3,"RegionCategory":"材料科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"CHEMISTRY, PHYSICAL","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Cardiopulmonary exercise testing (CPET) provides a reliable and reproducible approach to measuring fitness in patients and diagnosing their health problems. However, the data from CPET consist of multiple time series that require training to interpret. Part of this training teaches the use of flow charts or nested decision trees to interpret the CPET results. This paper investigates the use of two machine learning techniques using neural networks to predict patient health conditions with CPET data in contrast to flow charts. The data for this investigation comes from a small sample of patients with known health problems and who had CPET results. The small size of the sample data also allows us to investigate the use and performance of deep learning neural networks on health care problems with limited amounts of labeled training and testing data.
Methods: This paper compares the current standard for interpreting and classifying CPET data, flowcharts, to neural network techniques, autoencoders and convolutional neural networks (CNN). The study also investigated the performance of principal component analysis (PCA) with logistic regression to provide an additional baseline of comparison to the neural network techniques.
Results: The patients in the sample had two primary diagnoses: heart failure and metabolic syndrome. All model-based testing was done with 5-fold cross-validation and metrics of precision, recall, F1 score, and accuracy. As a baseline for comparison to our models, the highest performing flow chart method achieved an accuracy of 77%. Both PCA regression and CNN achieved an average accuracy of 90% and outperformed the flow chart methods on all metrics. The autoencoder with logistic regression performed the best on each of the metrics and had an average accuracy of 94%.
Conclusions: This study suggests that machine learning and neural network techniques, in particular, can provide higher levels of accuracy with CPET data than traditional flowchart methods. Further, the CNN performed well with a small data set showing that these techniques can be designed to perform well on small data problems that are often found in health care and the life sciences. Further testing with larger data sets is needed to continue evaluating the use of machine learning to interpret CPET data.
期刊介绍:
ACS Applied Energy Materials is an interdisciplinary journal publishing original research covering all aspects of materials, engineering, chemistry, physics and biology relevant to energy conversion and storage. The journal is devoted to reports of new and original experimental and theoretical research of an applied nature that integrate knowledge in the areas of materials, engineering, physics, bioscience, and chemistry into important energy applications.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
