Jennifer M Vojtech, Claire L Mitchell, Laura Raiff, Joshua C Kline, Gianluca De Luca
{"title":"Prediction of Voice Fundamental Frequency and Intensity from Surface Electromyographic Signals of the Face and Neck.","authors":"Jennifer M Vojtech, Claire L Mitchell, Laura Raiff, Joshua C Kline, Gianluca De Luca","doi":"10.3390/vibration5040041","DOIUrl":null,"url":null,"abstract":"<p><p>Silent speech interfaces (SSIs) enable speech recognition and synthesis in the absence of an acoustic signal. Yet, the archetypal SSI fails to convey the expressive attributes of prosody such as pitch and loudness, leading to lexical ambiguities. The aim of this study was to determine the efficacy of using surface electromyography (sEMG) as an approach for predicting continuous acoustic estimates of prosody. Ten participants performed a series of vocal tasks including sustained vowels, phrases, and monologues while acoustic data was recorded simultaneously with sEMG activity from muscles of the face and neck. A battery of time-, frequency-, and cepstral-domain features extracted from the sEMG signals were used to train deep regression neural networks to predict fundamental frequency and intensity contours from the acoustic signals. We achieved an average accuracy of 0.01 ST and precision of 0.56 ST for the estimation of fundamental frequency, and an average accuracy of 0.21 dB SPL and precision of 3.25 dB SPL for the estimation of intensity. This work highlights the importance of using sEMG as an alternative means of detecting prosody and shows promise for improving SSIs in future development.</p>","PeriodicalId":75301,"journal":{"name":"Vibration","volume":"5 4","pages":"692-710"},"PeriodicalIF":1.9000,"publicationDate":"2022-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9592063/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Vibration","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/vibration5040041","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/10/13 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"ENGINEERING, MECHANICAL","Score":null,"Total":0}
引用次数: 0
Abstract
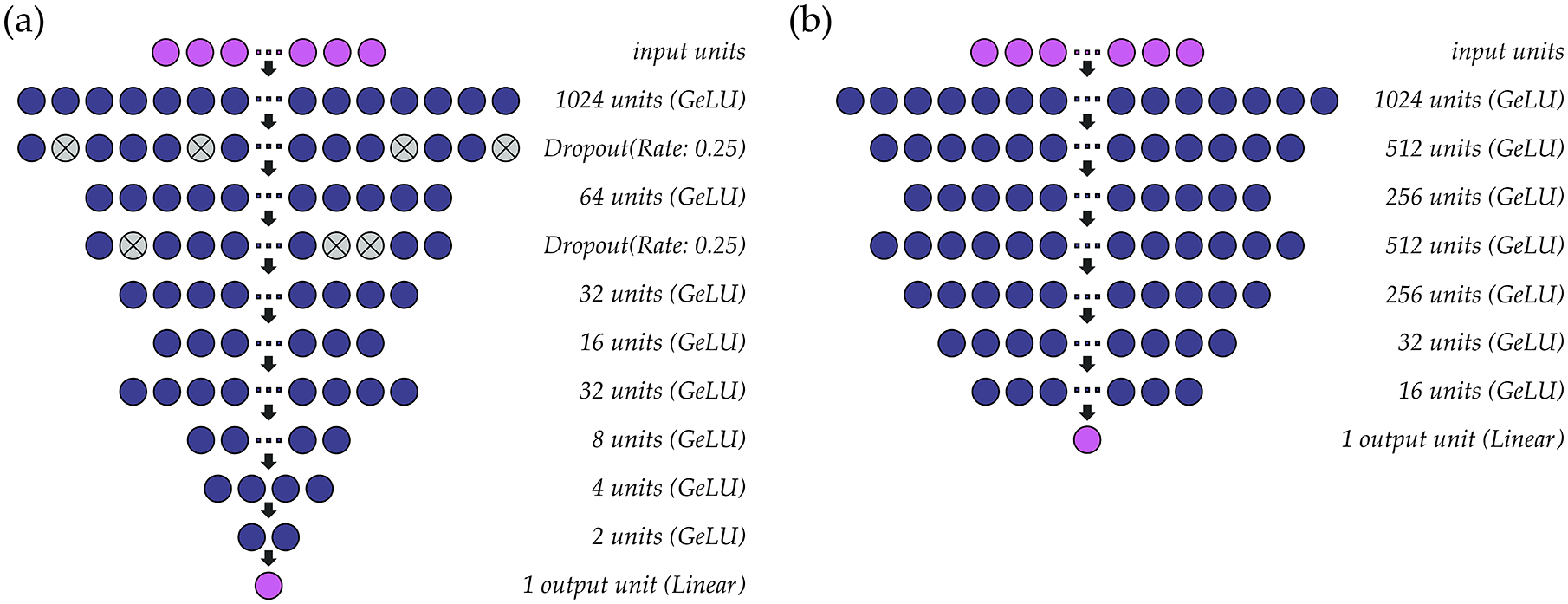
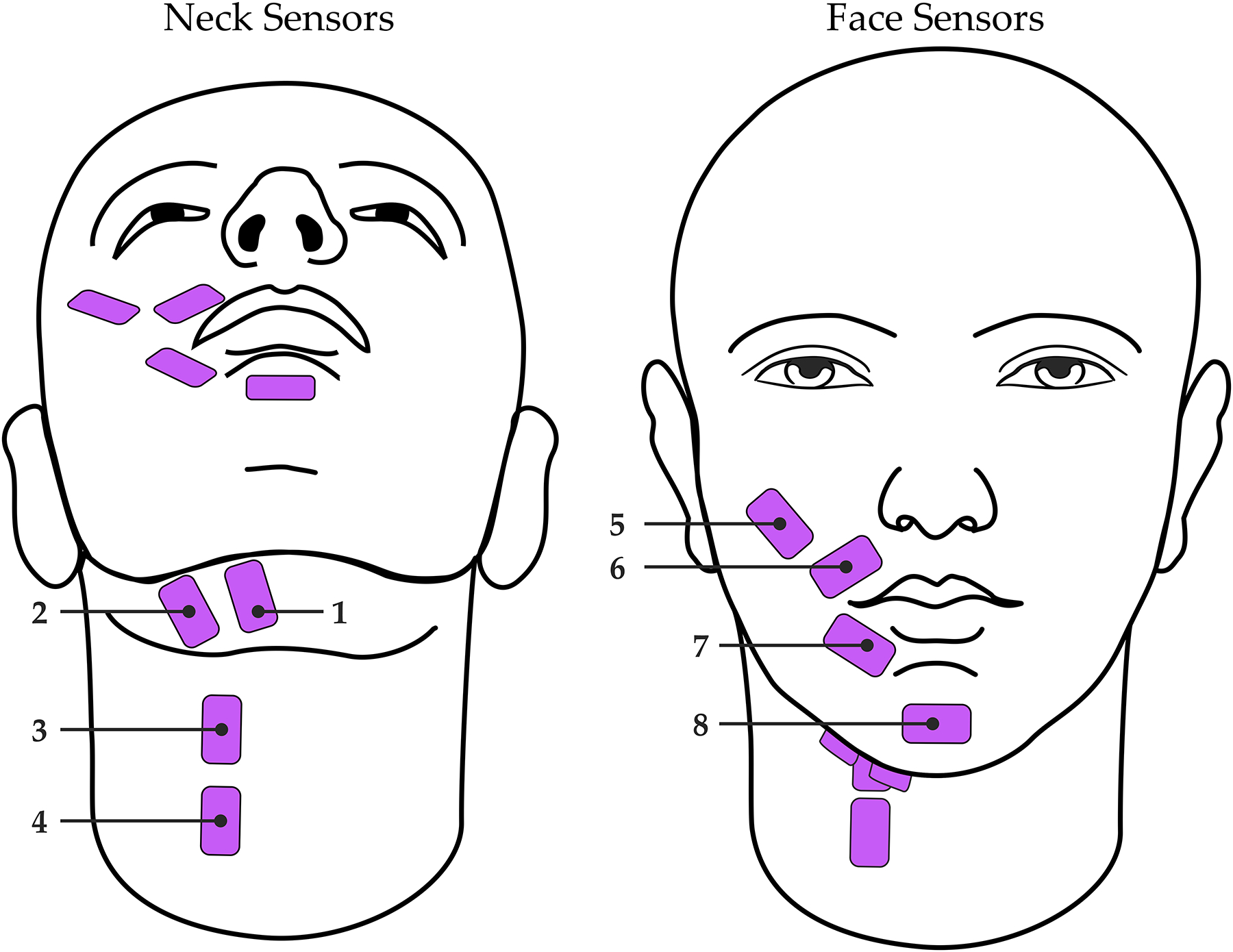
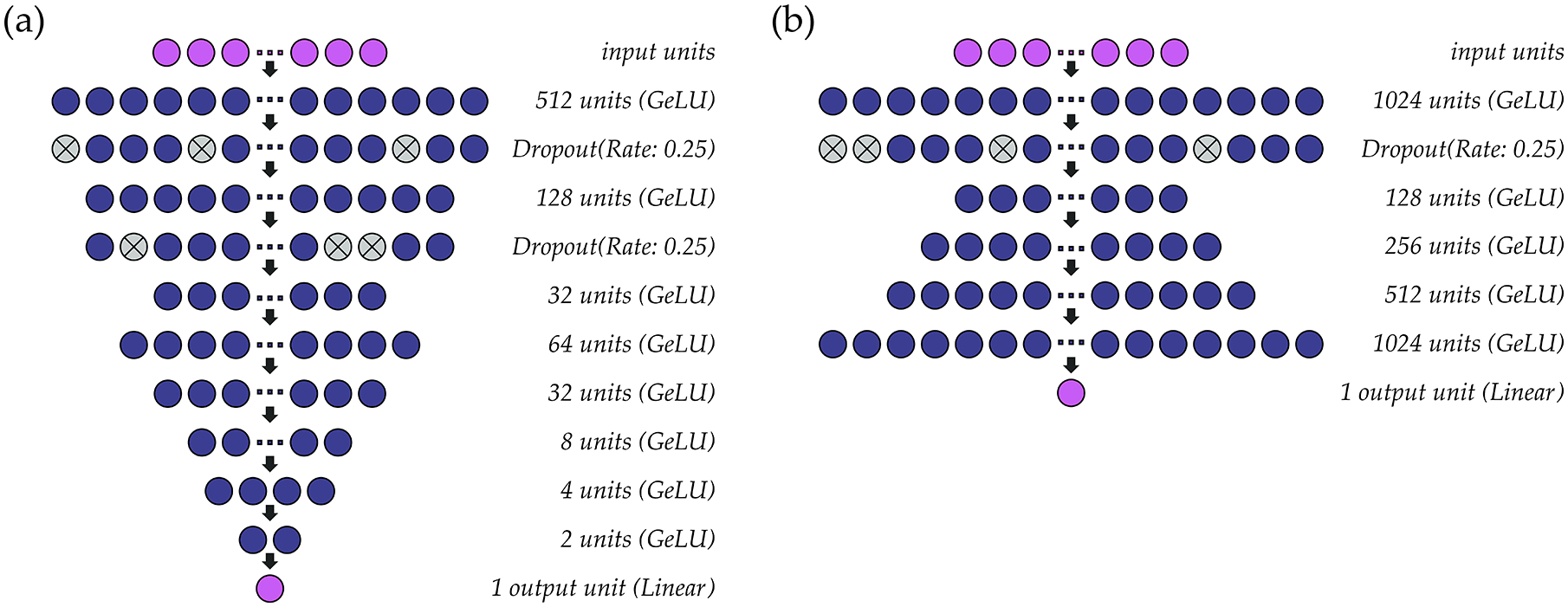
Silent speech interfaces (SSIs) enable speech recognition and synthesis in the absence of an acoustic signal. Yet, the archetypal SSI fails to convey the expressive attributes of prosody such as pitch and loudness, leading to lexical ambiguities. The aim of this study was to determine the efficacy of using surface electromyography (sEMG) as an approach for predicting continuous acoustic estimates of prosody. Ten participants performed a series of vocal tasks including sustained vowels, phrases, and monologues while acoustic data was recorded simultaneously with sEMG activity from muscles of the face and neck. A battery of time-, frequency-, and cepstral-domain features extracted from the sEMG signals were used to train deep regression neural networks to predict fundamental frequency and intensity contours from the acoustic signals. We achieved an average accuracy of 0.01 ST and precision of 0.56 ST for the estimation of fundamental frequency, and an average accuracy of 0.21 dB SPL and precision of 3.25 dB SPL for the estimation of intensity. This work highlights the importance of using sEMG as an alternative means of detecting prosody and shows promise for improving SSIs in future development.
无声语音接口(ssi)在没有声音信号的情况下实现语音识别和合成。然而,原型SSI未能传达韵律的表达属性,如音高和响度,导致词汇歧义。本研究的目的是确定使用表面肌电图(sEMG)作为预测韵律连续声学估计的方法的有效性。10名参与者完成了一系列发声任务,包括持续的元音、短语和独白,同时记录了面部和颈部肌肉的声电信号活动。从表面肌电信号中提取的一系列时间、频率和倒谱域特征用于训练深度回归神经网络,以预测声信号的基频和强度轮廓。基频估计的平均精度为0.01 ST,精密度为0.56 ST,强度估计的平均精度为0.21 dB SPL,精密度为3.25 dB SPL。这项工作强调了使用肌电图作为检测韵律的替代方法的重要性,并显示了在未来发展中改善ssi的希望。


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
