Naya Nagy, Matthew Stuart-Edwards, Marius Nagy, Liam Mitchell, Athanasios Zovoilis
{"title":"Quantum analysis of squiggle data.","authors":"Naya Nagy, Matthew Stuart-Edwards, Marius Nagy, Liam Mitchell, Athanasios Zovoilis","doi":"10.1186/s13040-023-00343-z","DOIUrl":null,"url":null,"abstract":"<p><p>Squiggle data is the numerical output of DNA and RNA sequencing by the Nanopore next generation sequencing platform. Nanopore sequencing offers expanded applications compared to previous sequencing techniques but produces a large amount of data in the form of current measurements over time. The analysis of these segments of current measurements require more complex and computationally intensive algorithms than previous sequencing technologies. The purpose of this study is to investigate in principle the potential of using quantum computers to speed up Nanopore data analysis. Quantum circuits are designed to extract major features of squiggle current measurements. The circuits are analyzed theoretically in terms of size and performance. Practical experiments on IBM QX show the limitations of the state of the art quantum computer to tackle real life squiggle data problems. Nevertheless, pre-processing of the squiggle data using the inverse wavelet transform, as experimented and analyzed in this paper as well, reduces the dimensionality of the problem in order to fit a reasonable size quantum computer in the hopefully near future.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"16 1","pages":"27"},"PeriodicalIF":6.1000,"publicationDate":"2023-10-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10557310/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-023-00343-z","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
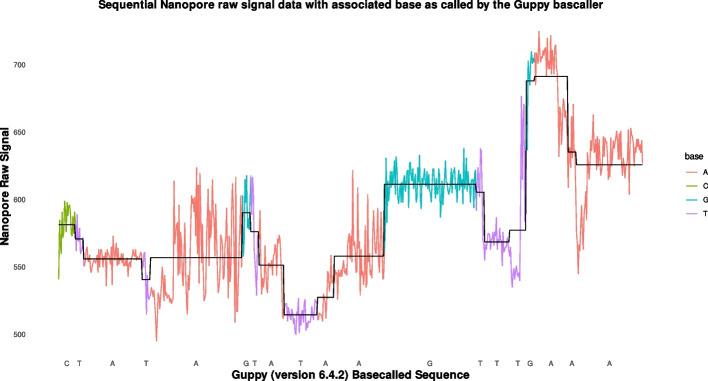
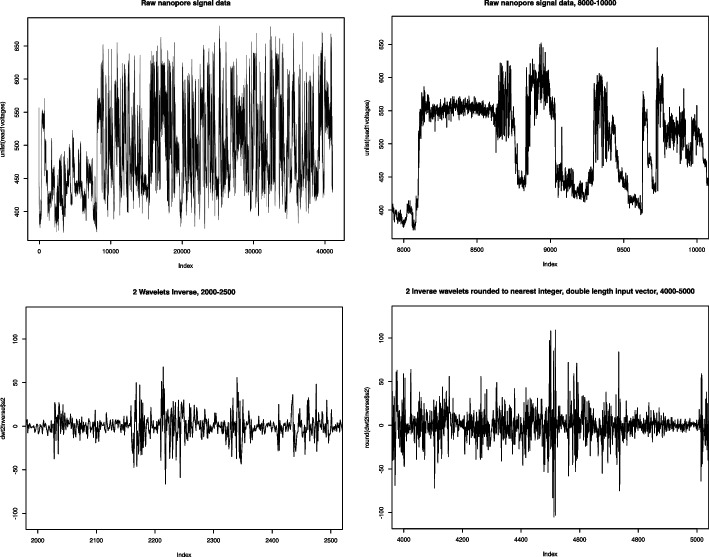
Squiggle data is the numerical output of DNA and RNA sequencing by the Nanopore next generation sequencing platform. Nanopore sequencing offers expanded applications compared to previous sequencing techniques but produces a large amount of data in the form of current measurements over time. The analysis of these segments of current measurements require more complex and computationally intensive algorithms than previous sequencing technologies. The purpose of this study is to investigate in principle the potential of using quantum computers to speed up Nanopore data analysis. Quantum circuits are designed to extract major features of squiggle current measurements. The circuits are analyzed theoretically in terms of size and performance. Practical experiments on IBM QX show the limitations of the state of the art quantum computer to tackle real life squiggle data problems. Nevertheless, pre-processing of the squiggle data using the inverse wavelet transform, as experimented and analyzed in this paper as well, reduces the dimensionality of the problem in order to fit a reasonable size quantum computer in the hopefully near future.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
