Application of natural language processing to identify social needs from patient medical notes: development and assessment of a scalable, performant, and rule-based model in an integrated healthcare delivery system.
Geoffrey M Gray, Ayah Zirikly, Luis M Ahumada, Masoud Rouhizadeh, Thomas Richards, Christopher Kitchen, Iman Foroughmand, Elham Hatef
{"title":"Application of natural language processing to identify social needs from patient medical notes: development and assessment of a scalable, performant, and rule-based model in an integrated healthcare delivery system.","authors":"Geoffrey M Gray, Ayah Zirikly, Luis M Ahumada, Masoud Rouhizadeh, Thomas Richards, Christopher Kitchen, Iman Foroughmand, Elham Hatef","doi":"10.1093/jamiaopen/ooad085","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>To develop and test a scalable, performant, and rule-based model for identifying 3 major domains of social needs (residential instability, food insecurity, and transportation issues) from the unstructured data in electronic health records (EHRs).</p><p><strong>Materials and methods: </strong>We included patients aged 18 years or older who received care at the Johns Hopkins Health System (JHHS) between July 2016 and June 2021 and had at least 1 unstructured (free-text) note in their EHR during the study period. We used a combination of manual lexicon curation and semiautomated lexicon creation for feature development. We developed an initial rules-based pipeline (Match Pipeline) using 2 keyword sets for each social needs domain. We performed rule-based keyword matching for distinct lexicons and tested the algorithm using an annotated dataset comprising 192 patients. Starting with a set of expert-identified keywords, we tested the adjustments by evaluating false positives and negatives identified in the labeled dataset. We assessed the performance of the algorithm using measures of precision, recall, and <i>F</i>1 score.</p><p><strong>Results: </strong>The algorithm for identifying residential instability had the best overall performance, with a weighted average for precision, recall, and <i>F</i>1 score of 0.92, 0.84, and 0.92 for identifying patients with homelessness and 0.84, 0.82, and 0.79 for identifying patients with housing insecurity. Metrics for the food insecurity algorithm were high but the transportation issues algorithm was the lowest overall performing metric.</p><p><strong>Discussion: </strong>The NLP algorithm in identifying social needs at JHHS performed relatively well and would provide the opportunity for implementation in a healthcare system.</p><p><strong>Conclusion: </strong>The NLP approach developed in this project could be adapted and potentially operationalized in the routine data processes of a healthcare system.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"6 4","pages":"ooad085"},"PeriodicalIF":3.4000,"publicationDate":"2023-10-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/2e/eb/ooad085.PMC10550267.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooad085","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/12/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: To develop and test a scalable, performant, and rule-based model for identifying 3 major domains of social needs (residential instability, food insecurity, and transportation issues) from the unstructured data in electronic health records (EHRs).
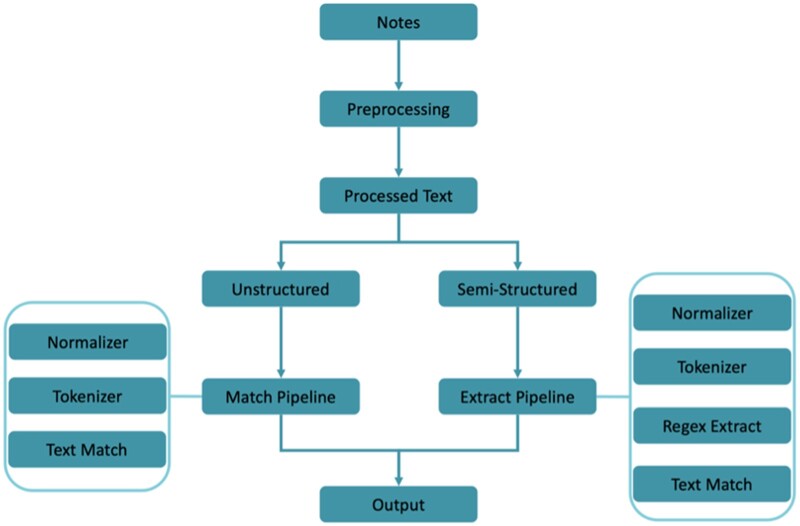
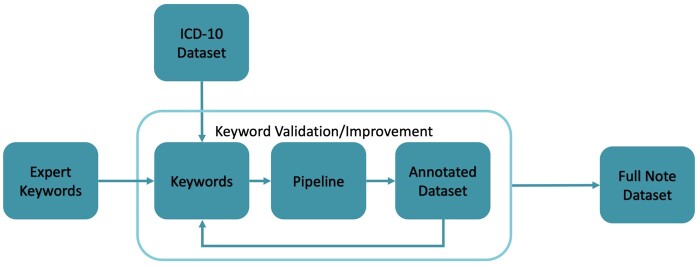
Materials and methods: We included patients aged 18 years or older who received care at the Johns Hopkins Health System (JHHS) between July 2016 and June 2021 and had at least 1 unstructured (free-text) note in their EHR during the study period. We used a combination of manual lexicon curation and semiautomated lexicon creation for feature development. We developed an initial rules-based pipeline (Match Pipeline) using 2 keyword sets for each social needs domain. We performed rule-based keyword matching for distinct lexicons and tested the algorithm using an annotated dataset comprising 192 patients. Starting with a set of expert-identified keywords, we tested the adjustments by evaluating false positives and negatives identified in the labeled dataset. We assessed the performance of the algorithm using measures of precision, recall, and F1 score.
Results: The algorithm for identifying residential instability had the best overall performance, with a weighted average for precision, recall, and F1 score of 0.92, 0.84, and 0.92 for identifying patients with homelessness and 0.84, 0.82, and 0.79 for identifying patients with housing insecurity. Metrics for the food insecurity algorithm were high but the transportation issues algorithm was the lowest overall performing metric.
Discussion: The NLP algorithm in identifying social needs at JHHS performed relatively well and would provide the opportunity for implementation in a healthcare system.
Conclusion: The NLP approach developed in this project could be adapted and potentially operationalized in the routine data processes of a healthcare system.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
