Bingmiao Gao, Yu Huang, Chao Peng, Bo Lin, Yanling Liao, Chao Bian, Jiaan Yang, Qiong Shi
{"title":"High-Throughput Prediction and Design of Novel Conopeptides for Biomedical Research and Development.","authors":"Bingmiao Gao, Yu Huang, Chao Peng, Bo Lin, Yanling Liao, Chao Bian, Jiaan Yang, Qiong Shi","doi":"10.34133/2022/9895270","DOIUrl":null,"url":null,"abstract":"<p><p>Cone snail venoms have been considered a valuable treasure for international scientists and businessmen, mainly due to their pharmacological applications in development of marine drugs for treatment of various human diseases. To date, around 800 <i>Conus</i> species are recorded, and each of them produces over 1,000 venom peptides (termed as conopeptides or conotoxins). This reflects the high diversity and complexity of cone snails, although most of their venoms are still uncharacterized. Advanced multiomics (such as genomics, transcriptomics, and proteomics) approaches have been recently developed to mine diverse <i>Conus</i> venom samples, with the main aim to predict and identify potentially interesting conopeptides in an efficient way. Some bioinformatics techniques have been applied to predict and design novel conopeptide sequences, related targets, and their binding modes. This review provides an overview of current knowledge on the high diversity of conopeptides and multiomics advances in high-throughput prediction of novel conopeptide sequences, as well as molecular modeling and design of potential drugs based on the predicted or validated interactions between these toxins and their molecular targets.</p>","PeriodicalId":56832,"journal":{"name":"生物设计研究(英文)","volume":"2022 ","pages":"9895270"},"PeriodicalIF":4.7000,"publicationDate":"2022-11-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10521759/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"生物设计研究(英文)","FirstCategoryId":"1087","ListUrlMain":"https://doi.org/10.34133/2022/9895270","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"Agricultural and Biological Sciences","Score":null,"Total":0}
引用次数: 0
Abstract
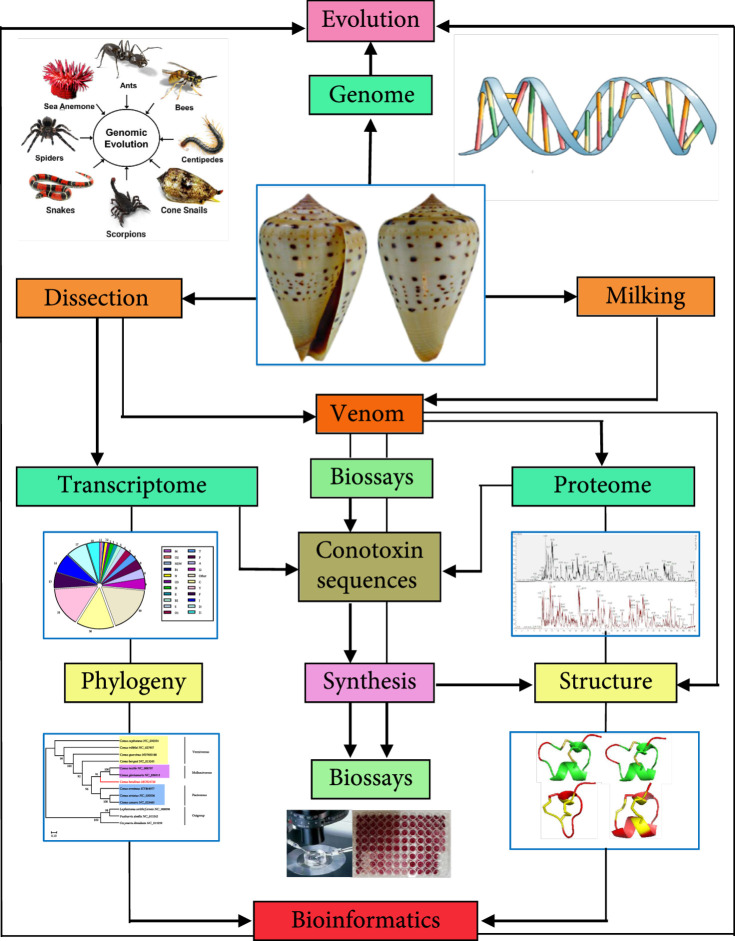
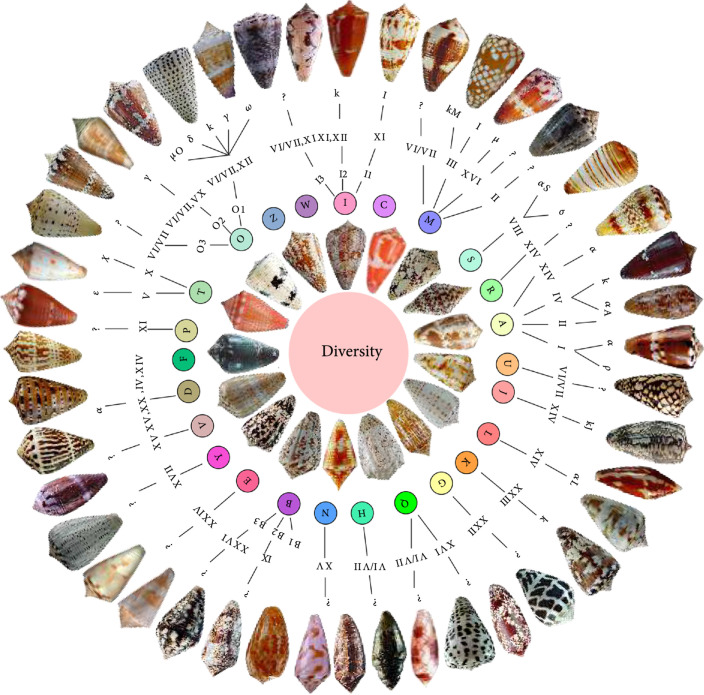
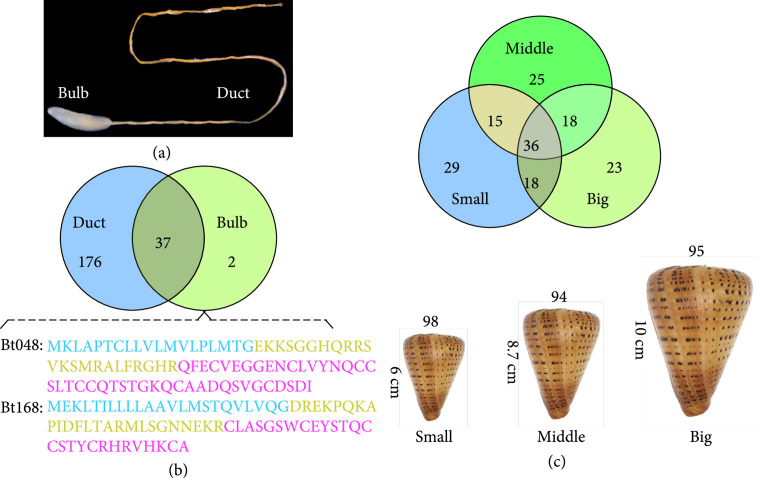
Cone snail venoms have been considered a valuable treasure for international scientists and businessmen, mainly due to their pharmacological applications in development of marine drugs for treatment of various human diseases. To date, around 800 Conus species are recorded, and each of them produces over 1,000 venom peptides (termed as conopeptides or conotoxins). This reflects the high diversity and complexity of cone snails, although most of their venoms are still uncharacterized. Advanced multiomics (such as genomics, transcriptomics, and proteomics) approaches have been recently developed to mine diverse Conus venom samples, with the main aim to predict and identify potentially interesting conopeptides in an efficient way. Some bioinformatics techniques have been applied to predict and design novel conopeptide sequences, related targets, and their binding modes. This review provides an overview of current knowledge on the high diversity of conopeptides and multiomics advances in high-throughput prediction of novel conopeptide sequences, as well as molecular modeling and design of potential drugs based on the predicted or validated interactions between these toxins and their molecular targets.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
