David Liben-Nowell, Julia Strand, Alexa Sharp, Tom Wexler, Kevin Woods
{"title":"The Danger of Testing by Selecting Controlled Subsets, with Applications to Spoken-Word Recognition.","authors":"David Liben-Nowell, Julia Strand, Alexa Sharp, Tom Wexler, Kevin Woods","doi":"10.5334/joc.51","DOIUrl":null,"url":null,"abstract":"<p><p>When examining the effects of a continuous variable <i>x</i> on an outcome <i>y</i>, a researcher might choose to dichotomize on <i>x</i>, dividing the population into two sets-low <i>x</i> and high <i>x</i>-and testing whether these two subpopulations differ with respect to <i>y</i>. Dichotomization has long been known to incur a cost in statistical power, but there remain circumstances in which it is appealing: an experimenter might use it to control for confounding covariates through subset selection, by carefully choosing a subpopulation of Low and a corresponding subpopulation of High that are balanced with respect to a list of control variables, and then comparing the subpopulations' <i>y</i> values. This \"divide, select, and test\" approach is used in many papers throughout the psycholinguistics literature, and elsewhere. Here we show that, despite the apparent innocuousness, these methodological choices can lead to erroneous results, in two ways. First, if the balanced subsets of Low and High are selected in certain ways, it is possible to conclude a relationship between <i>x</i> and <i>y</i> not present in the full population. Specifically, we show that previously published conclusions drawn from this methodology-about the effect of a particular lexical property on spoken-word recognition-do not in fact appear to hold. Second, if the balanced subsets of Low and High are selected randomly, this methodology frequently fails to show a relationship between <i>x</i> and <i>y</i> that is present in the full population. Our work uncovers a new facet of an ongoing research effort: to identify and reveal the implicit freedoms of experimental design that can lead to false conclusions.</p>","PeriodicalId":58,"journal":{"name":"The Journal of Physical Chemistry ","volume":"79 13","pages":"2"},"PeriodicalIF":2.7810,"publicationDate":"2019-01-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6634384/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"The Journal of Physical Chemistry ","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.5334/joc.51","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
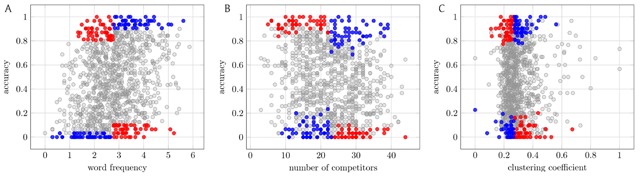
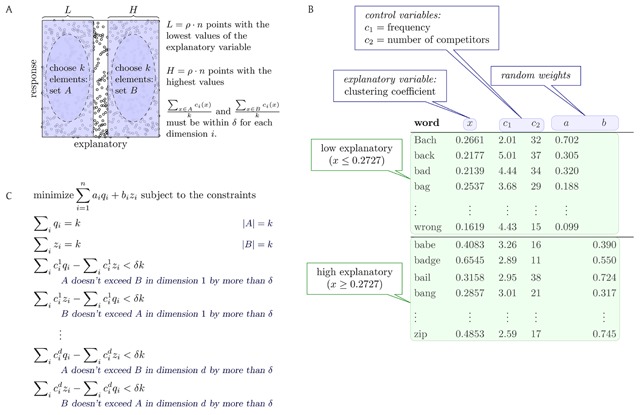
When examining the effects of a continuous variable x on an outcome y, a researcher might choose to dichotomize on x, dividing the population into two sets-low x and high x-and testing whether these two subpopulations differ with respect to y. Dichotomization has long been known to incur a cost in statistical power, but there remain circumstances in which it is appealing: an experimenter might use it to control for confounding covariates through subset selection, by carefully choosing a subpopulation of Low and a corresponding subpopulation of High that are balanced with respect to a list of control variables, and then comparing the subpopulations' y values. This "divide, select, and test" approach is used in many papers throughout the psycholinguistics literature, and elsewhere. Here we show that, despite the apparent innocuousness, these methodological choices can lead to erroneous results, in two ways. First, if the balanced subsets of Low and High are selected in certain ways, it is possible to conclude a relationship between x and y not present in the full population. Specifically, we show that previously published conclusions drawn from this methodology-about the effect of a particular lexical property on spoken-word recognition-do not in fact appear to hold. Second, if the balanced subsets of Low and High are selected randomly, this methodology frequently fails to show a relationship between x and y that is present in the full population. Our work uncovers a new facet of an ongoing research effort: to identify and reveal the implicit freedoms of experimental design that can lead to false conclusions.
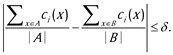


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
