{"title":"Quantifying the genericness of trademarks using natural language processing: an introduction with suggested metrics","authors":"Cameron Shackell, Lance De Vine","doi":"10.1007/s10506-021-09291-7","DOIUrl":null,"url":null,"abstract":"<div><p>If a trademark (“mark”) becomes a generic term, it may be cancelled under trademark law, a process known as genericide. Typically, in genericide cases, consumer surveys are brought into evidence to establish a mark’s semantic status as generic or distinctive. Some drawbacks of surveys are cost, delay, small sample size, lack of reproducibility, and observer bias. Today, however, much discourse involving marks is online. As a potential complement to consumer surveys, therefore, we explore an artificial intelligence approach based chiefly on word embeddings: mathematical models of meaning based on distributional semantics that can be trained on texts selected for jurisdictional and temporal relevance. After identifying two main factors in mark genericness, we first offer a simple screening metric based on the ngram frequency of uncapitalized variants of a mark. We then add two word embedding metrics: one addressing contextual similarity of uncapitalized variants, and one comparing the neighborhood density of marks and known generic terms in a category. For clarity and validation, we illustrate our metrics with examples of genericized, somewhat generic, and distinctive marks such as, respectively, DUMPSTER, DOBRO, and ROLEX.</p></div>","PeriodicalId":51336,"journal":{"name":"Artificial Intelligence and Law","volume":"30 2","pages":"199 - 220"},"PeriodicalIF":3.1000,"publicationDate":"2021-06-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1007/s10506-021-09291-7","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Artificial Intelligence and Law","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s10506-021-09291-7","RegionNum":2,"RegionCategory":"社会学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 1
Abstract
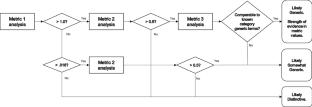
If a trademark (“mark”) becomes a generic term, it may be cancelled under trademark law, a process known as genericide. Typically, in genericide cases, consumer surveys are brought into evidence to establish a mark’s semantic status as generic or distinctive. Some drawbacks of surveys are cost, delay, small sample size, lack of reproducibility, and observer bias. Today, however, much discourse involving marks is online. As a potential complement to consumer surveys, therefore, we explore an artificial intelligence approach based chiefly on word embeddings: mathematical models of meaning based on distributional semantics that can be trained on texts selected for jurisdictional and temporal relevance. After identifying two main factors in mark genericness, we first offer a simple screening metric based on the ngram frequency of uncapitalized variants of a mark. We then add two word embedding metrics: one addressing contextual similarity of uncapitalized variants, and one comparing the neighborhood density of marks and known generic terms in a category. For clarity and validation, we illustrate our metrics with examples of genericized, somewhat generic, and distinctive marks such as, respectively, DUMPSTER, DOBRO, and ROLEX.
期刊介绍:
Artificial Intelligence and Law is an international forum for the dissemination of original interdisciplinary research in the following areas: Theoretical or empirical studies in artificial intelligence (AI), cognitive psychology, jurisprudence, linguistics, or philosophy which address the development of formal or computational models of legal knowledge, reasoning, and decision making. In-depth studies of innovative artificial intelligence systems that are being used in the legal domain. Studies which address the legal, ethical and social implications of the field of Artificial Intelligence and Law.
Topics of interest include, but are not limited to, the following: Computational models of legal reasoning and decision making; judgmental reasoning, adversarial reasoning, case-based reasoning, deontic reasoning, and normative reasoning. Formal representation of legal knowledge: deontic notions, normative
modalities, rights, factors, values, rules. Jurisprudential theories of legal reasoning. Specialized logics for law. Psychological and linguistic studies concerning legal reasoning. Legal expert systems; statutory systems, legal practice systems, predictive systems, and normative systems. AI and law support for legislative drafting, judicial decision-making, and
public administration. Intelligent processing of legal documents; conceptual retrieval of cases and statutes, automatic text understanding, intelligent document assembly systems, hypertext, and semantic markup of legal documents. Intelligent processing of legal information on the World Wide Web, legal ontologies, automated intelligent legal agents, electronic legal institutions, computational models of legal texts. Ramifications for AI and Law in e-Commerce, automatic contracting and negotiation, digital rights management, and automated dispute resolution. Ramifications for AI and Law in e-governance, e-government, e-Democracy, and knowledge-based systems supporting public services, public dialogue and mediation. Intelligent computer-assisted instructional systems in law or ethics. Evaluation and auditing techniques for legal AI systems. Systemic problems in the construction and delivery of legal AI systems. Impact of AI on the law and legal institutions. Ethical issues concerning legal AI systems. In addition to original research contributions, the Journal will include a Book Review section, a series of Technology Reports describing existing and emerging products, applications and technologies, and a Research Notes section of occasional essays posing interesting and timely research challenges for the field of Artificial Intelligence and Law. Financial support for the Journal of Artificial Intelligence and Law is provided by the University of Pittsburgh School of Law.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
