{"title":"Natural products subsets: Generation and characterization","authors":"Ana L. Chávez-Hernández, José L. Medina-Franco","doi":"10.1016/j.ailsci.2023.100066","DOIUrl":null,"url":null,"abstract":"<div><p>Natural products are attractive for drug discovery applications because of their distinctive chemical structures, such as an overall large fraction of sp<sup>3</sup> carbon atoms, chiral centers (both features associated with structural complexity), large chemical scaffolds, and diversity of functional groups. Furthermore, natural products are used in <em>de novo</em> design and have inspired the development of pseudo-natural products using generative models. Public databases such as the Collection of Open NatUral ProdUcTs and the Universal Natural Product database (UNPD) are rich sources of structures to be used in generative models and other applications. In this work, we report the selection and characterization of the most diverse compounds of natural products from the UNPD using the MaxMin algorithm. The subsets generated with 14,994, 7,497, and 4,998 compounds are publicly available at <span>https://github.com/DIFACQUIM/Natural-products-subsets-generation</span><svg><path></path></svg>. We anticipate that the subsets will be particularly useful in building generative models based on natural products by research groups, particularly those with limited access to extensive supercomputer resources.</p></div>","PeriodicalId":72304,"journal":{"name":"Artificial intelligence in the life sciences","volume":"3 ","pages":"Article 100066"},"PeriodicalIF":5.4000,"publicationDate":"2023-02-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Artificial intelligence in the life sciences","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2667318523000107","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 2
Abstract
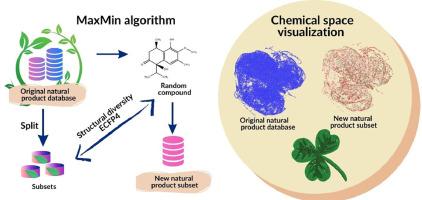
Natural products are attractive for drug discovery applications because of their distinctive chemical structures, such as an overall large fraction of sp3 carbon atoms, chiral centers (both features associated with structural complexity), large chemical scaffolds, and diversity of functional groups. Furthermore, natural products are used in de novo design and have inspired the development of pseudo-natural products using generative models. Public databases such as the Collection of Open NatUral ProdUcTs and the Universal Natural Product database (UNPD) are rich sources of structures to be used in generative models and other applications. In this work, we report the selection and characterization of the most diverse compounds of natural products from the UNPD using the MaxMin algorithm. The subsets generated with 14,994, 7,497, and 4,998 compounds are publicly available at https://github.com/DIFACQUIM/Natural-products-subsets-generation. We anticipate that the subsets will be particularly useful in building generative models based on natural products by research groups, particularly those with limited access to extensive supercomputer resources.
Artificial intelligence in the life sciencesPharmacology, Biochemistry, Genetics and Molecular Biology (General), Computer Science Applications, Health Informatics, Drug Discovery, Veterinary Science and Veterinary Medicine (General)



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
