{"title":"Large Scopus Data Sets and Its Analysis for Decision Making","authors":"Prem Kumar Singh","doi":"10.1007/s40745-022-00435-3","DOIUrl":null,"url":null,"abstract":"<div><p>Recently several authors paid attention towards Scopus Data analysis for intellectual measurement of institutes or authors. It is well known that the SCOPUS contains more than 34,346 peer reviewed Journals from different subjects with 3 lakh conferences. It is difficult to measure the performance or expertise of any institute or author in the given domain for admission, job, and ranking or other decision making process. The reason is several manipulations started in document and citation count via strategic authors or institute which can be measured via average author publications, number of funding, collaborations and retracted papers. It is happening due to rogue editor or business strategic of educationalist for profit. However these types of misconduct impacts lot to real researcher which forces brain drain. To resolve this issue, the current paper provides a way to measure the intellectual achievement of an institute or author based on several metrics. The proposed method is illustrated using the SCOPUS data sets and it’s metric for critical understanding.</p></div>","PeriodicalId":36280,"journal":{"name":"Annals of Data Science","volume":"11 2","pages":"589 - 618"},"PeriodicalIF":0.0000,"publicationDate":"2022-08-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Annals of Data Science","FirstCategoryId":"1085","ListUrlMain":"https://link.springer.com/article/10.1007/s40745-022-00435-3","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Decision Sciences","Score":null,"Total":0}
引用次数: 0
Abstract
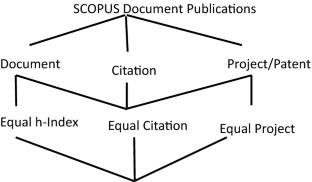
Recently several authors paid attention towards Scopus Data analysis for intellectual measurement of institutes or authors. It is well known that the SCOPUS contains more than 34,346 peer reviewed Journals from different subjects with 3 lakh conferences. It is difficult to measure the performance or expertise of any institute or author in the given domain for admission, job, and ranking or other decision making process. The reason is several manipulations started in document and citation count via strategic authors or institute which can be measured via average author publications, number of funding, collaborations and retracted papers. It is happening due to rogue editor or business strategic of educationalist for profit. However these types of misconduct impacts lot to real researcher which forces brain drain. To resolve this issue, the current paper provides a way to measure the intellectual achievement of an institute or author based on several metrics. The proposed method is illustrated using the SCOPUS data sets and it’s metric for critical understanding.
期刊介绍:
Annals of Data Science (ADS) publishes cutting-edge research findings, experimental results and case studies of data science. Although Data Science is regarded as an interdisciplinary field of using mathematics, statistics, databases, data mining, high-performance computing, knowledge management and virtualization to discover knowledge from Big Data, it should have its own scientific contents, such as axioms, laws and rules, which are fundamentally important for experts in different fields to explore their own interests from Big Data. ADS encourages contributors to address such challenging problems at this exchange platform. At present, how to discover knowledge from heterogeneous data under Big Data environment needs to be addressed. ADS is a series of volumes edited by either the editorial office or guest editors. Guest editors will be responsible for call-for-papers and the review process for high-quality contributions in their volumes.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
