Abeed Sarker, Sahithi Lakamana, Yuting Guo, Yao Ge, Abimbola Leslie, Omolola Okunromade, Elena Gonzalez-Polledo, Jeanmarie Perrone, Anne Marie McKenzie-Brown
{"title":"#ChronicPain: Automated Building of a Chronic Pain Cohort from Twitter Using Machine Learning.","authors":"Abeed Sarker, Sahithi Lakamana, Yuting Guo, Yao Ge, Abimbola Leslie, Omolola Okunromade, Elena Gonzalez-Polledo, Jeanmarie Perrone, Anne Marie McKenzie-Brown","doi":"10.34133/hds.0078","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Due to the high burden of chronic pain, and the detrimental public health consequences of its treatment with opioids, there is a high-priority need to identify effective alternative therapies. Social media is a potentially valuable resource for knowledge about self-reported therapies by chronic pain sufferers.</p><p><strong>Methods: </strong>We attempted to (a) verify the presence of large-scale chronic pain-related chatter on Twitter, (b) develop natural language processing and machine learning methods for automatically detecting self-disclosures, (c) collect longitudinal data posted by them, and (d) semiautomatically analyze the types of chronic pain-related information reported by them. We collected data using chronic pain-related hashtags and keywords and manually annotated 4,998 posts to indicate if they were self-reports of chronic pain experiences. We trained and evaluated several state-of-the-art supervised text classification models and deployed the best-performing classifier. We collected all publicly available posts from detected cohort members and conducted manual and natural language processing-driven descriptive analyses.</p><p><strong>Results: </strong>Interannotator agreement for the binary annotation was 0.82 (Cohen's kappa). The RoBERTa model performed best (F<sub>1</sub> score: 0.84; 95% confidence interval: 0.80 to 0.89), and we used this model to classify all collected unlabeled posts. We discovered 22,795 self-reported chronic pain sufferers and collected over 3 million of their past posts. Further analyses revealed information about, but not limited to, alternative treatments, patient sentiments about treatments, side effects, and self-management strategies.</p><p><strong>Conclusion: </strong>Our social media based approach will result in an automatically growing large cohort over time, and the data can be leveraged to identify effective opioid-alternative therapies for diverse chronic pain types.</p>","PeriodicalId":73207,"journal":{"name":"Health data science","volume":" ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10852024/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Health data science","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.34133/hds.0078","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/7/4 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Due to the high burden of chronic pain, and the detrimental public health consequences of its treatment with opioids, there is a high-priority need to identify effective alternative therapies. Social media is a potentially valuable resource for knowledge about self-reported therapies by chronic pain sufferers.
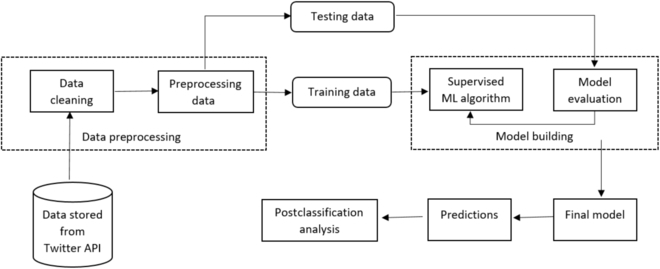
Methods: We attempted to (a) verify the presence of large-scale chronic pain-related chatter on Twitter, (b) develop natural language processing and machine learning methods for automatically detecting self-disclosures, (c) collect longitudinal data posted by them, and (d) semiautomatically analyze the types of chronic pain-related information reported by them. We collected data using chronic pain-related hashtags and keywords and manually annotated 4,998 posts to indicate if they were self-reports of chronic pain experiences. We trained and evaluated several state-of-the-art supervised text classification models and deployed the best-performing classifier. We collected all publicly available posts from detected cohort members and conducted manual and natural language processing-driven descriptive analyses.
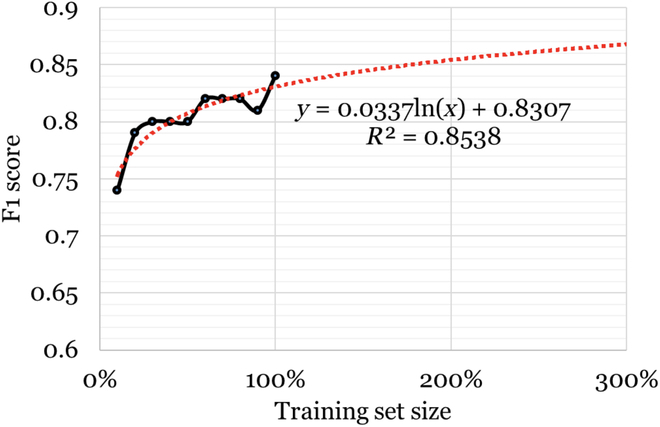
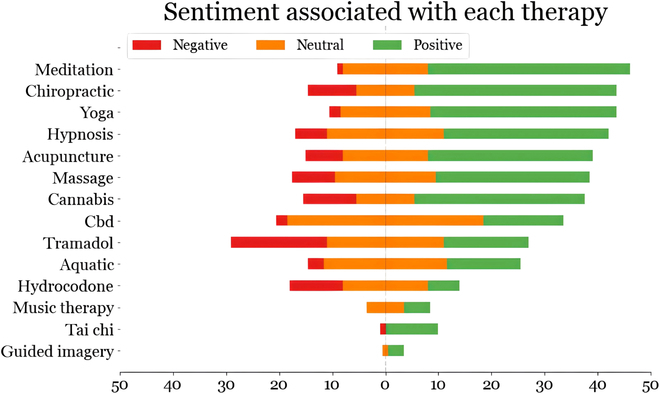
Results: Interannotator agreement for the binary annotation was 0.82 (Cohen's kappa). The RoBERTa model performed best (F1 score: 0.84; 95% confidence interval: 0.80 to 0.89), and we used this model to classify all collected unlabeled posts. We discovered 22,795 self-reported chronic pain sufferers and collected over 3 million of their past posts. Further analyses revealed information about, but not limited to, alternative treatments, patient sentiments about treatments, side effects, and self-management strategies.
Conclusion: Our social media based approach will result in an automatically growing large cohort over time, and the data can be leveraged to identify effective opioid-alternative therapies for diverse chronic pain types.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
