Marco Berrettini, Giuliano Galimberti, Saverio Ranciati
{"title":"Semiparametric finite mixture of regression models with Bayesian P-splines","authors":"Marco Berrettini, Giuliano Galimberti, Saverio Ranciati","doi":"10.1007/s11634-022-00523-5","DOIUrl":null,"url":null,"abstract":"<div><p>Mixture models provide a useful tool to account for unobserved heterogeneity and are at the basis of many model-based clustering methods. To gain additional flexibility, some model parameters can be expressed as functions of concomitant covariates. In this Paper, a semiparametric finite mixture of regression models is defined, with concomitant information assumed to influence both the component weights and the conditional means. In particular, linear predictors are replaced with smooth functions of the covariate considered by resorting to cubic splines. An estimation procedure within the Bayesian paradigm is suggested, where smoothness of the covariate effects is controlled by suitable choices for the prior distributions of the spline coefficients. A data augmentation scheme based on difference random utility models is exploited to describe the mixture weights as functions of the covariate. The performance of the proposed methodology is investigated via simulation experiments and two real-world datasets, one about baseball salaries and the other concerning nitrogen oxide in engine exhaust.</p></div>","PeriodicalId":49270,"journal":{"name":"Advances in Data Analysis and Classification","volume":"17 3","pages":"745 - 775"},"PeriodicalIF":1.3000,"publicationDate":"2022-10-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s11634-022-00523-5.pdf","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in Data Analysis and Classification","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s11634-022-00523-5","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
引用次数: 1
Abstract
Mixture models provide a useful tool to account for unobserved heterogeneity and are at the basis of many model-based clustering methods. To gain additional flexibility, some model parameters can be expressed as functions of concomitant covariates. In this Paper, a semiparametric finite mixture of regression models is defined, with concomitant information assumed to influence both the component weights and the conditional means. In particular, linear predictors are replaced with smooth functions of the covariate considered by resorting to cubic splines. An estimation procedure within the Bayesian paradigm is suggested, where smoothness of the covariate effects is controlled by suitable choices for the prior distributions of the spline coefficients. A data augmentation scheme based on difference random utility models is exploited to describe the mixture weights as functions of the covariate. The performance of the proposed methodology is investigated via simulation experiments and two real-world datasets, one about baseball salaries and the other concerning nitrogen oxide in engine exhaust.
期刊介绍:
The international journal Advances in Data Analysis and Classification (ADAC) is designed as a forum for high standard publications on research and applications concerning the extraction of knowable aspects from many types of data. It publishes articles on such topics as structural, quantitative, or statistical approaches for the analysis of data; advances in classification, clustering, and pattern recognition methods; strategies for modeling complex data and mining large data sets; methods for the extraction of knowledge from data, and applications of advanced methods in specific domains of practice. Articles illustrate how new domain-specific knowledge can be made available from data by skillful use of data analysis methods. The journal also publishes survey papers that outline, and illuminate the basic ideas and techniques of special approaches.
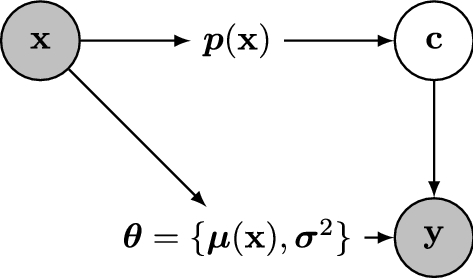



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
