{"title":"Benchmarking distance-based partitioning methods for mixed-type data","authors":"Efthymios Costa, Ioanna Papatsouma, Angelos Markos","doi":"10.1007/s11634-022-00521-7","DOIUrl":null,"url":null,"abstract":"<div><p>Clustering mixed-type data, that is, observation by variable data that consist of both continuous and categorical variables poses novel challenges. Foremost among these challenges is the choice of the most appropriate clustering method for the data. This paper presents a benchmarking study comparing eight distance-based partitioning methods for mixed-type data in terms of cluster recovery performance. A series of simulations carried out by a full factorial design are presented that examined the effect of a variety of factors on cluster recovery. The amount of cluster overlap, the percentage of categorical variables in the data set, the number of clusters and the number of observations had the largest effects on cluster recovery and in most of the tested scenarios. KAMILA, K-Prototypes and sequential Factor Analysis and K-Means clustering typically performed better than other methods. The study can be a useful reference for practitioners in the choice of the most appropriate method.</p></div>","PeriodicalId":49270,"journal":{"name":"Advances in Data Analysis and Classification","volume":"17 3","pages":"701 - 724"},"PeriodicalIF":1.3000,"publicationDate":"2022-09-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s11634-022-00521-7.pdf","citationCount":"3","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in Data Analysis and Classification","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s11634-022-00521-7","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
引用次数: 3
Abstract
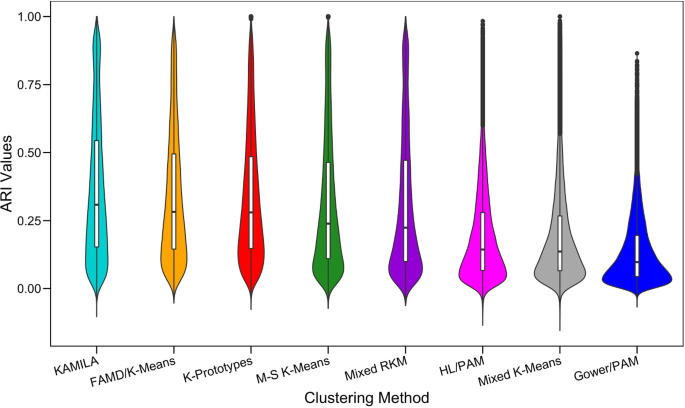
Clustering mixed-type data, that is, observation by variable data that consist of both continuous and categorical variables poses novel challenges. Foremost among these challenges is the choice of the most appropriate clustering method for the data. This paper presents a benchmarking study comparing eight distance-based partitioning methods for mixed-type data in terms of cluster recovery performance. A series of simulations carried out by a full factorial design are presented that examined the effect of a variety of factors on cluster recovery. The amount of cluster overlap, the percentage of categorical variables in the data set, the number of clusters and the number of observations had the largest effects on cluster recovery and in most of the tested scenarios. KAMILA, K-Prototypes and sequential Factor Analysis and K-Means clustering typically performed better than other methods. The study can be a useful reference for practitioners in the choice of the most appropriate method.
期刊介绍:
The international journal Advances in Data Analysis and Classification (ADAC) is designed as a forum for high standard publications on research and applications concerning the extraction of knowable aspects from many types of data. It publishes articles on such topics as structural, quantitative, or statistical approaches for the analysis of data; advances in classification, clustering, and pattern recognition methods; strategies for modeling complex data and mining large data sets; methods for the extraction of knowledge from data, and applications of advanced methods in specific domains of practice. Articles illustrate how new domain-specific knowledge can be made available from data by skillful use of data analysis methods. The journal also publishes survey papers that outline, and illuminate the basic ideas and techniques of special approaches.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
