{"title":"Towards a Unified Network for Robust Monocular Depth Estimation: Network Architecture, Training Strategy and Dataset","authors":"Mochu Xiang, Yuchao Dai, Feiyu Zhang, Jiawei Shi, Xinyu Tian, Zhensong Zhang","doi":"10.1007/s11263-023-01915-6","DOIUrl":null,"url":null,"abstract":"<p>Robust monocular depth estimation (MDE) aims at learning a <i>unified</i> model that works across diverse real-world scenes, which is an important and active topic in computer vision. In this paper, we present <span>Megatron_RVC</span>, our winning solution for the monocular depth challenge in the Robust Vision Challenge (RVC) 2022, where we tackle the challenging problem from three perspectives: network architecture, training strategy and dataset. In particular, we made three contributions towards robust MDE: (1) we built a neural network with high capacity to enable flexible and accurate monocular depth predictions, which contains dedicated components to provide content-aware embeddings and to improve the richness of the details; (2) we proposed a novel mixing training strategy to handle real-world images with different aspect ratios, resolutions and apply tailored loss functions based on the properties of their depth maps; (3) to train a unified network model that covers diverse real-world scenes, we used over 1 million images from different datasets. As of 3rd October 2022, our unified model ranked consistently first across three benchmarks (KITTI, MPI Sintel, and VIPER) among all participants.</p>","PeriodicalId":13752,"journal":{"name":"International Journal of Computer Vision","volume":"31 48","pages":""},"PeriodicalIF":9.3000,"publicationDate":"2023-10-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11263-023-01915-6","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 1
Abstract
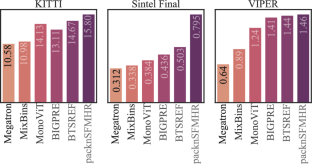
Robust monocular depth estimation (MDE) aims at learning a unified model that works across diverse real-world scenes, which is an important and active topic in computer vision. In this paper, we present Megatron_RVC, our winning solution for the monocular depth challenge in the Robust Vision Challenge (RVC) 2022, where we tackle the challenging problem from three perspectives: network architecture, training strategy and dataset. In particular, we made three contributions towards robust MDE: (1) we built a neural network with high capacity to enable flexible and accurate monocular depth predictions, which contains dedicated components to provide content-aware embeddings and to improve the richness of the details; (2) we proposed a novel mixing training strategy to handle real-world images with different aspect ratios, resolutions and apply tailored loss functions based on the properties of their depth maps; (3) to train a unified network model that covers diverse real-world scenes, we used over 1 million images from different datasets. As of 3rd October 2022, our unified model ranked consistently first across three benchmarks (KITTI, MPI Sintel, and VIPER) among all participants.
期刊介绍:
The International Journal of Computer Vision (IJCV) serves as a platform for sharing new research findings in the rapidly growing field of computer vision. It publishes 12 issues annually and presents high-quality, original contributions to the science and engineering of computer vision. The journal encompasses various types of articles to cater to different research outputs.
Regular articles, which span up to 25 journal pages, focus on significant technical advancements that are of broad interest to the field. These articles showcase substantial progress in computer vision.
Short articles, limited to 10 pages, offer a swift publication path for novel research outcomes. They provide a quicker means for sharing new findings with the computer vision community.
Survey articles, comprising up to 30 pages, offer critical evaluations of the current state of the art in computer vision or offer tutorial presentations of relevant topics. These articles provide comprehensive and insightful overviews of specific subject areas.
In addition to technical articles, the journal also includes book reviews, position papers, and editorials by prominent scientific figures. These contributions serve to complement the technical content and provide valuable perspectives.
The journal encourages authors to include supplementary material online, such as images, video sequences, data sets, and software. This additional material enhances the understanding and reproducibility of the published research.
Overall, the International Journal of Computer Vision is a comprehensive publication that caters to researchers in this rapidly growing field. It covers a range of article types, offers additional online resources, and facilitates the dissemination of impactful research.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
