{"title":"Cascaded Iterative Transformer for Jointly Predicting Facial Landmark, Occlusion Probability and Head Pose","authors":"Yaokun Li, Guang Tan, Chao Gou","doi":"10.1007/s11263-023-01935-2","DOIUrl":null,"url":null,"abstract":"<p>Landmark detection under large pose with occlusion has been one of the challenging problems in the field of facial analysis. Recently, many works have predicted pose or occlusion together in the multi-task learning (MTL) paradigm, trying to tap into their dependencies and thus alleviate this issue. However, such implicit dependencies are weakly interpretable and inconsistent with the way humans exploit inter-task coupling relations, i.e., accommodating the induced explicit effects. This is one of the essentials that hinders their performance. To this end, in this paper, we propose a Cascaded Iterative Transformer (CIT) to jointly predict facial landmark, occlusion probability, and pose. The proposed CIT, besides implicitly mining task dependencies in a shared encoder, innovatively employs a cost-effective and portability-friendly strategy to pass the decoders’ predictions as prior knowledge to human-like exploit the coupling-induced effects. Moreover, to the best of our knowledge, no dataset contains all these task annotations simultaneously, so we introduce a new dataset termed MERL-RAV-FLOP based on the MERL-RAV dataset. We conduct extensive experiments on several challenging datasets (300W-LP, AFLW2000-3D, BIWI, COFW, and MERL-RAV-FLOP) and achieve remarkable results. The code and dataset can be accessed in https://github.com/Iron-LYK/CIT.</p>","PeriodicalId":13752,"journal":{"name":"International Journal of Computer Vision","volume":"57 16","pages":""},"PeriodicalIF":9.3000,"publicationDate":"2023-11-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11263-023-01935-2","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
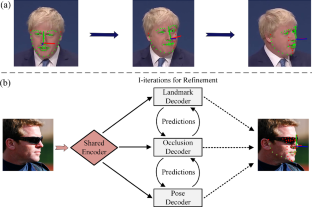
Landmark detection under large pose with occlusion has been one of the challenging problems in the field of facial analysis. Recently, many works have predicted pose or occlusion together in the multi-task learning (MTL) paradigm, trying to tap into their dependencies and thus alleviate this issue. However, such implicit dependencies are weakly interpretable and inconsistent with the way humans exploit inter-task coupling relations, i.e., accommodating the induced explicit effects. This is one of the essentials that hinders their performance. To this end, in this paper, we propose a Cascaded Iterative Transformer (CIT) to jointly predict facial landmark, occlusion probability, and pose. The proposed CIT, besides implicitly mining task dependencies in a shared encoder, innovatively employs a cost-effective and portability-friendly strategy to pass the decoders’ predictions as prior knowledge to human-like exploit the coupling-induced effects. Moreover, to the best of our knowledge, no dataset contains all these task annotations simultaneously, so we introduce a new dataset termed MERL-RAV-FLOP based on the MERL-RAV dataset. We conduct extensive experiments on several challenging datasets (300W-LP, AFLW2000-3D, BIWI, COFW, and MERL-RAV-FLOP) and achieve remarkable results. The code and dataset can be accessed in https://github.com/Iron-LYK/CIT.
期刊介绍:
The International Journal of Computer Vision (IJCV) serves as a platform for sharing new research findings in the rapidly growing field of computer vision. It publishes 12 issues annually and presents high-quality, original contributions to the science and engineering of computer vision. The journal encompasses various types of articles to cater to different research outputs.
Regular articles, which span up to 25 journal pages, focus on significant technical advancements that are of broad interest to the field. These articles showcase substantial progress in computer vision.
Short articles, limited to 10 pages, offer a swift publication path for novel research outcomes. They provide a quicker means for sharing new findings with the computer vision community.
Survey articles, comprising up to 30 pages, offer critical evaluations of the current state of the art in computer vision or offer tutorial presentations of relevant topics. These articles provide comprehensive and insightful overviews of specific subject areas.
In addition to technical articles, the journal also includes book reviews, position papers, and editorials by prominent scientific figures. These contributions serve to complement the technical content and provide valuable perspectives.
The journal encourages authors to include supplementary material online, such as images, video sequences, data sets, and software. This additional material enhances the understanding and reproducibility of the published research.
Overall, the International Journal of Computer Vision is a comprehensive publication that caters to researchers in this rapidly growing field. It covers a range of article types, offers additional online resources, and facilitates the dissemination of impactful research.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
