{"title":"2018 George Lyman Duff Memorial Lecture: Genetics and Genomics of Coronary Artery Disease: A Decade of Progress.","authors":"Ruth McPherson","doi":"10.1161/ATVBAHA.119.311392","DOIUrl":null,"url":null,"abstract":"<p><p>Recent studies have led to a broader understanding of the genetic architecture of coronary artery disease and demonstrate that it largely derives from the cumulative effect of multiple common risk alleles individually of small effect size rather than rare variants with large effects on coronary artery disease risk. The tools applied include genome-wide association studies encompassing over 200 000 individuals complemented by bioinformatic approaches including imputation from whole-genome data sets, expression quantitative trait loci analyses, and interrogation of ENCODE (Encyclopedia of DNA Elements), Roadmap Epigenetic Project, and other data sets. Over 160 genome-wide significant loci associated with coronary artery disease risk have been identified using the genome-wide association studies approach, 90% of which are situated in intergenic regions. Here, I will describe, in part, our research over the last decade performed in collaboration with a series of bright trainees and an extensive number of groups and individuals around the world as it applies to our understanding of the genetic basis of this complex disease. These studies include computational approaches to better understand missing heritability and identify causal pathways, experimental approaches, and progress in understanding at the molecular level the function of the multiple risk loci identified and potential applications of these genomic data in clinical medicine and drug discovery.</p>","PeriodicalId":38174,"journal":{"name":"Communication Booknotes Quarterly","volume":"34 1","pages":"1925-1937"},"PeriodicalIF":0.0000,"publicationDate":"2019-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6766359/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Communication Booknotes Quarterly","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1161/ATVBAHA.119.311392","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2019/8/29 0:00:00","PubModel":"Epub","JCR":"Q4","JCRName":"Social Sciences","Score":null,"Total":0}
引用次数: 0
Abstract
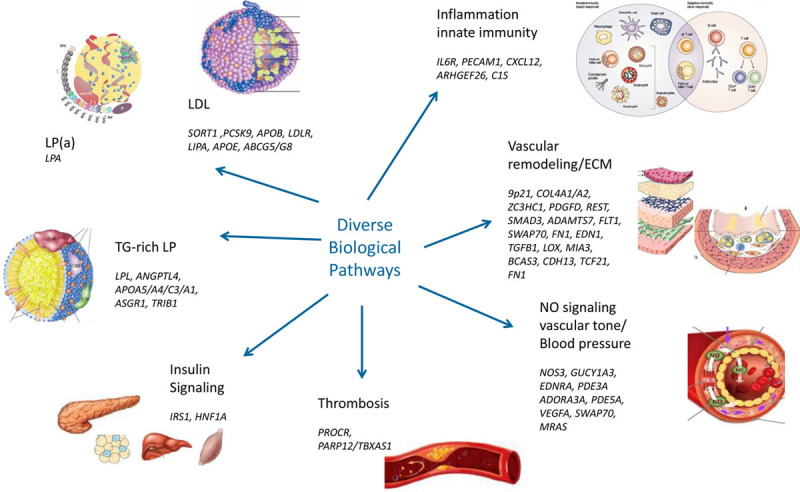
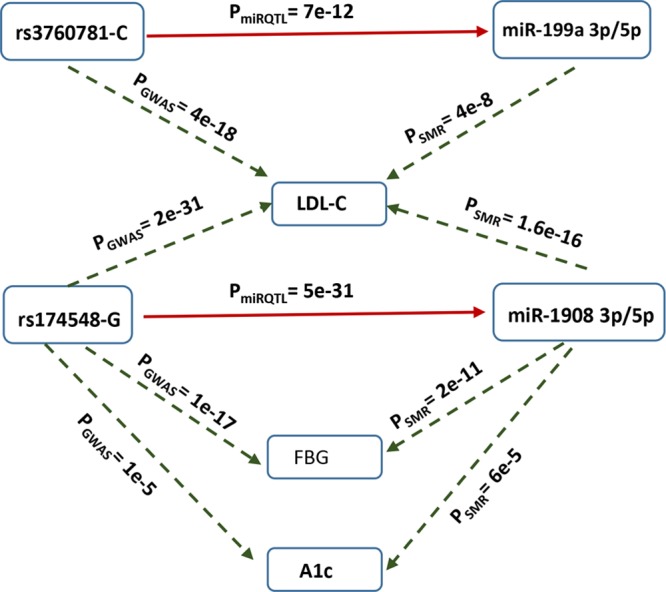
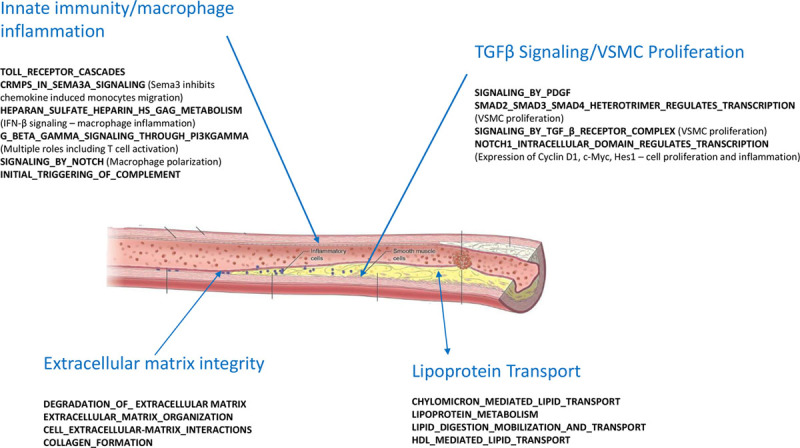
Recent studies have led to a broader understanding of the genetic architecture of coronary artery disease and demonstrate that it largely derives from the cumulative effect of multiple common risk alleles individually of small effect size rather than rare variants with large effects on coronary artery disease risk. The tools applied include genome-wide association studies encompassing over 200 000 individuals complemented by bioinformatic approaches including imputation from whole-genome data sets, expression quantitative trait loci analyses, and interrogation of ENCODE (Encyclopedia of DNA Elements), Roadmap Epigenetic Project, and other data sets. Over 160 genome-wide significant loci associated with coronary artery disease risk have been identified using the genome-wide association studies approach, 90% of which are situated in intergenic regions. Here, I will describe, in part, our research over the last decade performed in collaboration with a series of bright trainees and an extensive number of groups and individuals around the world as it applies to our understanding of the genetic basis of this complex disease. These studies include computational approaches to better understand missing heritability and identify causal pathways, experimental approaches, and progress in understanding at the molecular level the function of the multiple risk loci identified and potential applications of these genomic data in clinical medicine and drug discovery.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
