{"title":"An efficient and scalable SPARQL query processing framework for big data using MapReduce and hybrid optimum load balancing","authors":"V. Naveen Kumar , Ashok Kumar P.S.","doi":"10.1016/j.datak.2023.102239","DOIUrl":null,"url":null,"abstract":"<div><p>The increasing RDF (Resource Description Framework) data volume requires a Hadoop<span> platform for processing queries over large datasets. In this work, SPARQL (Simple Protocol and Rdf Query Language) queries are evaluated with Hadoop based on the objective of minimizing the number of joins through data partitioning for performing map/reduce jobs. The query evaluation time and the number of cross node joins are minimized with the proposed partitioning techniques. Extended vertical partitioning is proposed for distributed data stores based on objects’ explicit information for splitting predicates. For accessing the RDF data, hybrid monarch butterfly with beetle swarm load balancing optimization with Map-reduce (Hybrid Optimum Load Balancing) is applied. The proposed SPARQL query processing is evaluated over large RDF datasets. The proposed approach’s evaluation results are analyzed with the existing approaches, indicating the proposed framework’s efficiency. By using the proposed approach, an accuracy of 97 % is obtained.</span></p></div>","PeriodicalId":55184,"journal":{"name":"Data & Knowledge Engineering","volume":"148 ","pages":"Article 102239"},"PeriodicalIF":2.7000,"publicationDate":"2023-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Data & Knowledge Engineering","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0169023X2300099X","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/10/21 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
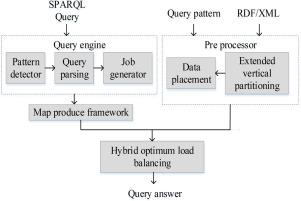
The increasing RDF (Resource Description Framework) data volume requires a Hadoop platform for processing queries over large datasets. In this work, SPARQL (Simple Protocol and Rdf Query Language) queries are evaluated with Hadoop based on the objective of minimizing the number of joins through data partitioning for performing map/reduce jobs. The query evaluation time and the number of cross node joins are minimized with the proposed partitioning techniques. Extended vertical partitioning is proposed for distributed data stores based on objects’ explicit information for splitting predicates. For accessing the RDF data, hybrid monarch butterfly with beetle swarm load balancing optimization with Map-reduce (Hybrid Optimum Load Balancing) is applied. The proposed SPARQL query processing is evaluated over large RDF datasets. The proposed approach’s evaluation results are analyzed with the existing approaches, indicating the proposed framework’s efficiency. By using the proposed approach, an accuracy of 97 % is obtained.
期刊介绍:
Data & Knowledge Engineering (DKE) stimulates the exchange of ideas and interaction between these two related fields of interest. DKE reaches a world-wide audience of researchers, designers, managers and users. The major aim of the journal is to identify, investigate and analyze the underlying principles in the design and effective use of these systems.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
