Paul K Mvula, Paula Branco, Guy-Vincent Jourdan, Herna L Viktor
{"title":"Evaluating Word Embedding Feature Extraction Techniques for Host-Based Intrusion Detection Systems.","authors":"Paul K Mvula, Paula Branco, Guy-Vincent Jourdan, Herna L Viktor","doi":"10.1007/s44248-023-00002-y","DOIUrl":null,"url":null,"abstract":"<p><p>Research into Intrusion and Anomaly Detectors at the Host level typically pays much attention to extracting attributes from system call traces. These include window-based, Hidden Markov Models, and sequence-model-based attributes. Recently, several works have been focusing on sequence-model-based feature extractors, specifically Word2Vec and GloVe, to extract embeddings from the system call traces due to their ability to capture semantic relationships among system calls. However, due to the nature of the data, these extractors introduce inconsistencies in the extracted features, causing the Machine Learning models built on them to yield inaccurate and potentially misleading results. In this paper, we first highlight the research challenges posed by these extractors. Then, we conduct experiments with new feature sets assessing their suitability to address the detected issues. Our experiments show that Word2Vec is prone to introducing more duplicated samples than GloVe. Regarding the solutions proposed, we found that concatenating the embedding vectors generated by Word2Vec and GloVe yields the overall best balanced accuracy. In addition to resolving the challenge of data leakage, this approach enables an improvement in performance relative to other alternatives.</p>","PeriodicalId":72824,"journal":{"name":"Discover data","volume":"1 1","pages":"2"},"PeriodicalIF":0.0000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10077957/pdf/","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Discover data","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s44248-023-00002-y","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 2
Abstract
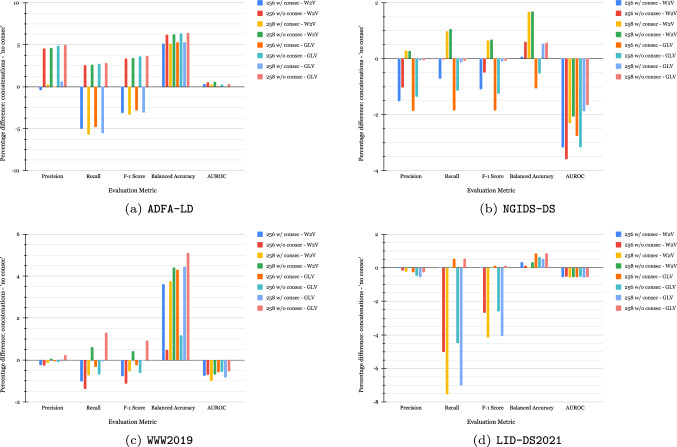
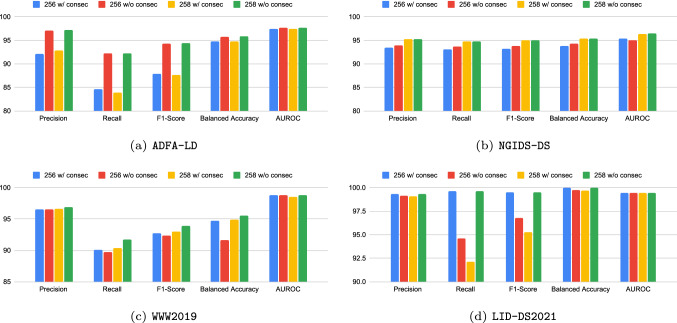
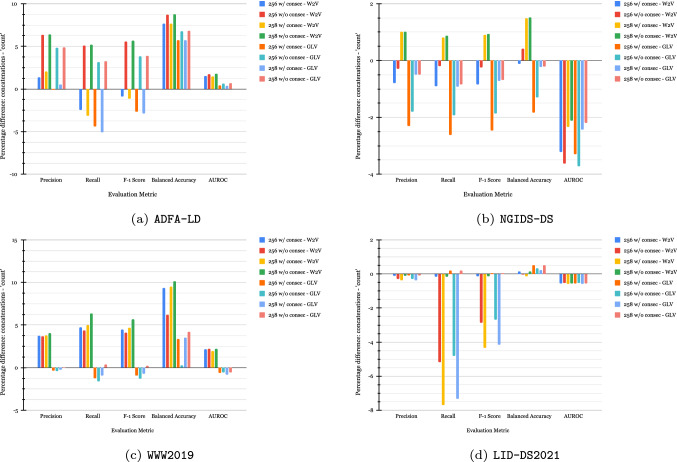
Research into Intrusion and Anomaly Detectors at the Host level typically pays much attention to extracting attributes from system call traces. These include window-based, Hidden Markov Models, and sequence-model-based attributes. Recently, several works have been focusing on sequence-model-based feature extractors, specifically Word2Vec and GloVe, to extract embeddings from the system call traces due to their ability to capture semantic relationships among system calls. However, due to the nature of the data, these extractors introduce inconsistencies in the extracted features, causing the Machine Learning models built on them to yield inaccurate and potentially misleading results. In this paper, we first highlight the research challenges posed by these extractors. Then, we conduct experiments with new feature sets assessing their suitability to address the detected issues. Our experiments show that Word2Vec is prone to introducing more duplicated samples than GloVe. Regarding the solutions proposed, we found that concatenating the embedding vectors generated by Word2Vec and GloVe yields the overall best balanced accuracy. In addition to resolving the challenge of data leakage, this approach enables an improvement in performance relative to other alternatives.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
