C H Nachappa, N Shobha Rani, Peeta Basa Pati, M Gokulnath
{"title":"Adaptive dewarping of severely warped camera-captured document images based on document map generation.","authors":"C H Nachappa, N Shobha Rani, Peeta Basa Pati, M Gokulnath","doi":"10.1007/s10032-022-00425-4","DOIUrl":null,"url":null,"abstract":"<p><p>Automated dewarping of camera-captured handwritten documents is a challenging research problem in Computer Vision and Pattern Recognition. Most available systems assume the shape of the camera-captured image boundaries to be anywhere between trapezoidal and octahedral, with linear distortion in areas between the boundaries for dewarping. The majority of the state-of-the-art applications successfully dewarp the simple-to-medium range geometrical distortions with partial selection of control points by a user. The proposed work implements a fully automated technique for control point detection from simple-to-complex geometrical distortions in camera-captured document images. The input image is subject to preprocessing, corner point detection, document map generation, and rendering of the de-warped document image. The proposed algorithm has been tested on five different camera-captured document datasets (one internal and four external publicly available) consisting of 958 images. Both quantitative and qualitative evaluations have been performed to test the efficacy of the proposed system. On the quantitative front, an Intersection Over Union (IoU) score of 0.92, 0.88, and 0.80 for document map generation for low-, medium-, and high-complexity datasets, respectively. Additionally, accuracies of the recognized texts, obtained from a market leading OCR engine, are utilized for quantitative comparative analysis on document images before and after the proposed enhancement. Finally, the qualitative analysis visually establishes the system's reliability by demonstrating improved readability even for severely distorted image samples.</p>","PeriodicalId":73486,"journal":{"name":"","volume":"26 2","pages":"149-169"},"PeriodicalIF":0.0,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9838515/pdf/","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10032-022-00425-4","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 2
Abstract
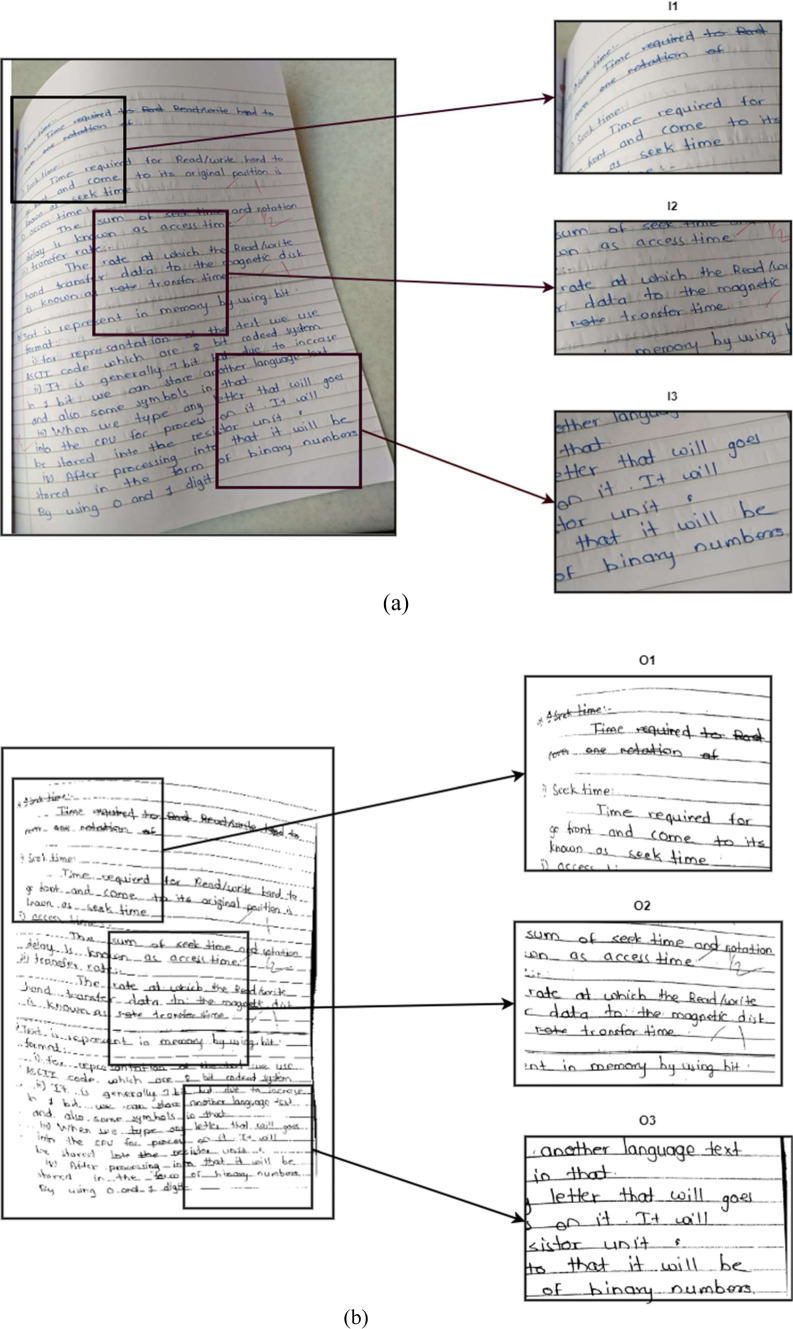
Automated dewarping of camera-captured handwritten documents is a challenging research problem in Computer Vision and Pattern Recognition. Most available systems assume the shape of the camera-captured image boundaries to be anywhere between trapezoidal and octahedral, with linear distortion in areas between the boundaries for dewarping. The majority of the state-of-the-art applications successfully dewarp the simple-to-medium range geometrical distortions with partial selection of control points by a user. The proposed work implements a fully automated technique for control point detection from simple-to-complex geometrical distortions in camera-captured document images. The input image is subject to preprocessing, corner point detection, document map generation, and rendering of the de-warped document image. The proposed algorithm has been tested on five different camera-captured document datasets (one internal and four external publicly available) consisting of 958 images. Both quantitative and qualitative evaluations have been performed to test the efficacy of the proposed system. On the quantitative front, an Intersection Over Union (IoU) score of 0.92, 0.88, and 0.80 for document map generation for low-, medium-, and high-complexity datasets, respectively. Additionally, accuracies of the recognized texts, obtained from a market leading OCR engine, are utilized for quantitative comparative analysis on document images before and after the proposed enhancement. Finally, the qualitative analysis visually establishes the system's reliability by demonstrating improved readability even for severely distorted image samples.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
