{"title":"Facial expression recognition in videos using hybrid CNN & ConvLSTM.","authors":"Rajesh Singh, Sumeet Saurav, Tarun Kumar, Ravi Saini, Anil Vohra, Sanjay Singh","doi":"10.1007/s41870-023-01183-0","DOIUrl":null,"url":null,"abstract":"<p><p>The three-dimensional convolutional neural network (3D-CNN) and long short-term memory (LSTM) have consistently outperformed many approaches in video-based facial expression recognition (VFER). The image is unrolled to a one-dimensional vector by the vanilla version of the fully-connected LSTM (FC-LSTM), which leads to the loss of crucial spatial information. Convolutional LSTM (ConvLSTM) overcomes this limitation by performing LSTM operations in convolutions without unrolling, thus retaining useful spatial information. Motivated by this, in this paper, we propose a neural network architecture that consists of a blend of 3D-CNN and ConvLSTM for VFER. The proposed hybrid architecture captures spatiotemporal information from the video sequences of emotions and attains competitive accuracy on three FER datasets open to the public, namely the SAVEE, CK + , and AFEW. The experimental results demonstrate excellent performance without external emotional data with the added advantage of having a simple model with fewer parameters. Moreover, unlike the state-of-the-art deep learning models, our designed FER pipeline improves execution speed by many factors while achieving competitive recognition accuracy. Hence, the proposed FER pipeline is an appropriate candidate for recognizing facial expressions on resource-limited embedded platforms for real-time applications.</p>","PeriodicalId":73455,"journal":{"name":"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management","volume":"15 4","pages":"1819-1830"},"PeriodicalIF":0.0000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10028317/pdf/","citationCount":"5","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s41870-023-01183-0","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/3/21 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 5
Abstract
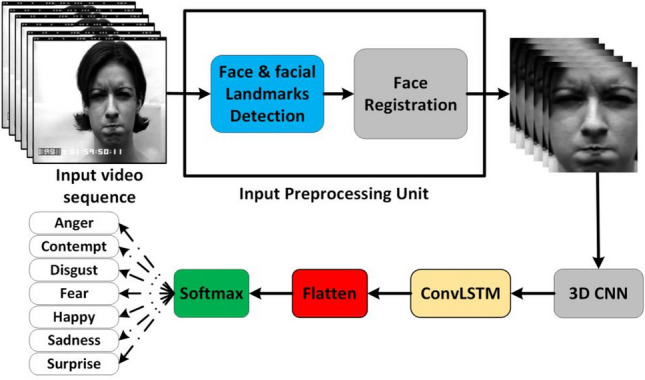
The three-dimensional convolutional neural network (3D-CNN) and long short-term memory (LSTM) have consistently outperformed many approaches in video-based facial expression recognition (VFER). The image is unrolled to a one-dimensional vector by the vanilla version of the fully-connected LSTM (FC-LSTM), which leads to the loss of crucial spatial information. Convolutional LSTM (ConvLSTM) overcomes this limitation by performing LSTM operations in convolutions without unrolling, thus retaining useful spatial information. Motivated by this, in this paper, we propose a neural network architecture that consists of a blend of 3D-CNN and ConvLSTM for VFER. The proposed hybrid architecture captures spatiotemporal information from the video sequences of emotions and attains competitive accuracy on three FER datasets open to the public, namely the SAVEE, CK + , and AFEW. The experimental results demonstrate excellent performance without external emotional data with the added advantage of having a simple model with fewer parameters. Moreover, unlike the state-of-the-art deep learning models, our designed FER pipeline improves execution speed by many factors while achieving competitive recognition accuracy. Hence, the proposed FER pipeline is an appropriate candidate for recognizing facial expressions on resource-limited embedded platforms for real-time applications.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
