{"title":"Detecting and classifying online health misinformation with 'Content Similarity Measure (CSM)' algorithm: an automated fact-checking-based approach.","authors":"Yashoda Barve, Jatinderkumar R Saini","doi":"10.1007/s11227-022-05032-y","DOIUrl":null,"url":null,"abstract":"<p><p>Information dissemination occurs through the 'word of media' in the digital world. Fraudulent and deceitful content, such as misinformation, has detrimental effects on people. An implicit fact-based automated fact-checking technique comprising information retrieval, natural language processing, and machine learning techniques assist in assessing the credibility of content and detecting misinformation. Previous studies focused on linguistic and textual features and similarity measures-based approaches. However, these studies need to gain knowledge of facts, and similarity measures are less accurate when dealing with sparse or zero data. To fill these gaps, we propose a 'Content Similarity Measure (CSM)' algorithm that can perform automated fact-checking of URLs in the healthcare domain. Authors have introduced a novel set of content similarity, domain-specific, and sentiment polarity score features to achieve journalistic fact-checking. An extensive analysis of the proposed algorithm compared with standard similarity measures and machine learning classifiers showed that the 'content similarity score' feature outperformed other features with an accuracy of 88.26%. In the algorithmic approach, CSM showed improved accuracy of 91.06% compared to the Jaccard similarity measure with 74.26% accuracy. Another observation is that the algorithmic approach outperformed the feature-based method. To check the robustness of the algorithms, authors have tested the model on three state-of-the-art datasets, viz. CoAID, FakeHealth, and ReCOVery. With the algorithmic approach, CSM showed the highest accuracy of 87.30%, 89.30%, 85.26%, and 88.83% on CoAID, ReCOVery, FakeHealth (Story), and FakeHealth (Release) datasets, respectively. With a feature-based approach, the proposed CSM showed the highest accuracy of 85.93%, 87.97%, 83.92%, and 86.80%, respectively.</p>","PeriodicalId":50034,"journal":{"name":"Journal of Supercomputing","volume":"79 8","pages":"9127-9156"},"PeriodicalIF":2.7000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9825061/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Supercomputing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11227-022-05032-y","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/7 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
引用次数: 0
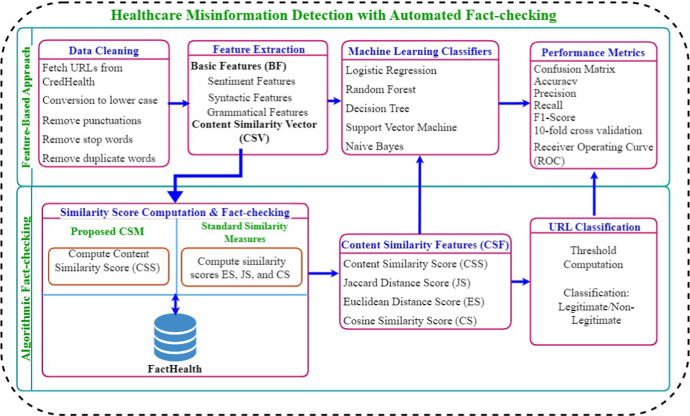
Abstract
Information dissemination occurs through the 'word of media' in the digital world. Fraudulent and deceitful content, such as misinformation, has detrimental effects on people. An implicit fact-based automated fact-checking technique comprising information retrieval, natural language processing, and machine learning techniques assist in assessing the credibility of content and detecting misinformation. Previous studies focused on linguistic and textual features and similarity measures-based approaches. However, these studies need to gain knowledge of facts, and similarity measures are less accurate when dealing with sparse or zero data. To fill these gaps, we propose a 'Content Similarity Measure (CSM)' algorithm that can perform automated fact-checking of URLs in the healthcare domain. Authors have introduced a novel set of content similarity, domain-specific, and sentiment polarity score features to achieve journalistic fact-checking. An extensive analysis of the proposed algorithm compared with standard similarity measures and machine learning classifiers showed that the 'content similarity score' feature outperformed other features with an accuracy of 88.26%. In the algorithmic approach, CSM showed improved accuracy of 91.06% compared to the Jaccard similarity measure with 74.26% accuracy. Another observation is that the algorithmic approach outperformed the feature-based method. To check the robustness of the algorithms, authors have tested the model on three state-of-the-art datasets, viz. CoAID, FakeHealth, and ReCOVery. With the algorithmic approach, CSM showed the highest accuracy of 87.30%, 89.30%, 85.26%, and 88.83% on CoAID, ReCOVery, FakeHealth (Story), and FakeHealth (Release) datasets, respectively. With a feature-based approach, the proposed CSM showed the highest accuracy of 85.93%, 87.97%, 83.92%, and 86.80%, respectively.
期刊介绍:
The Journal of Supercomputing publishes papers on the technology, architecture and systems, algorithms, languages and programs, performance measures and methods, and applications of all aspects of Supercomputing. Tutorial and survey papers are intended for workers and students in the fields associated with and employing advanced computer systems. The journal also publishes letters to the editor, especially in areas relating to policy, succinct statements of paradoxes, intuitively puzzling results, partial results and real needs.
Published theoretical and practical papers are advanced, in-depth treatments describing new developments and new ideas. Each includes an introduction summarizing prior, directly pertinent work that is useful for the reader to understand, in order to appreciate the advances being described.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
