Multiple sampling schemes and deep learning improve active learning performance in drug-drug interaction information retrieval analysis from the literature.
{"title":"Multiple sampling schemes and deep learning improve active learning performance in drug-drug interaction information retrieval analysis from the literature.","authors":"Weixin Xie, Kunjie Fan, Shijun Zhang, Lang Li","doi":"10.1186/s13326-023-00287-7","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Drug-drug interaction (DDI) information retrieval (IR) is an important natural language process (NLP) task from the PubMed literature. For the first time, active learning (AL) is studied in DDI IR analysis. DDI IR analysis from PubMed abstracts faces the challenges of relatively small positive DDI samples among overwhelmingly large negative samples. Random negative sampling and positive sampling are purposely designed to improve the efficiency of AL analysis. The consistency of random negative sampling and positive sampling is shown in the paper.</p><p><strong>Results: </strong>PubMed abstracts are divided into two pools. Screened pool contains all abstracts that pass the DDI keywords query in PubMed, while unscreened pool includes all the other abstracts. At a prespecified recall rate of 0.95, DDI IR analysis precision is evaluated and compared. In screened pool IR analysis using supporting vector machine (SVM), similarity sampling plus uncertainty sampling improves the precision over uncertainty sampling, from 0.89 to 0.92 respectively. In the unscreened pool IR analysis, the integrated random negative sampling, positive sampling, and similarity sampling improve the precision over uncertainty sampling along, from 0.72 to 0.81 respectively. When we change the SVM to a deep learning method, all sampling schemes consistently improve DDI AL analysis in both screened pool and unscreened pool. Deep learning has significant improvement of precision over SVM, 0.96 vs. 0.92 in screened pool, and 0.90 vs. 0.81 in the unscreened pool, respectively.</p><p><strong>Conclusions: </strong>By integrating various sampling schemes and deep learning algorithms into AL, the DDI IR analysis from literature is significantly improved. The random negative sampling and positive sampling are highly effective methods in improving AL analysis where the positive and negative samples are extremely imbalanced.</p>","PeriodicalId":15055,"journal":{"name":"Journal of Biomedical Semantics","volume":"14 1","pages":"5"},"PeriodicalIF":2.0000,"publicationDate":"2023-05-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10228061/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Semantics","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1186/s13326-023-00287-7","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
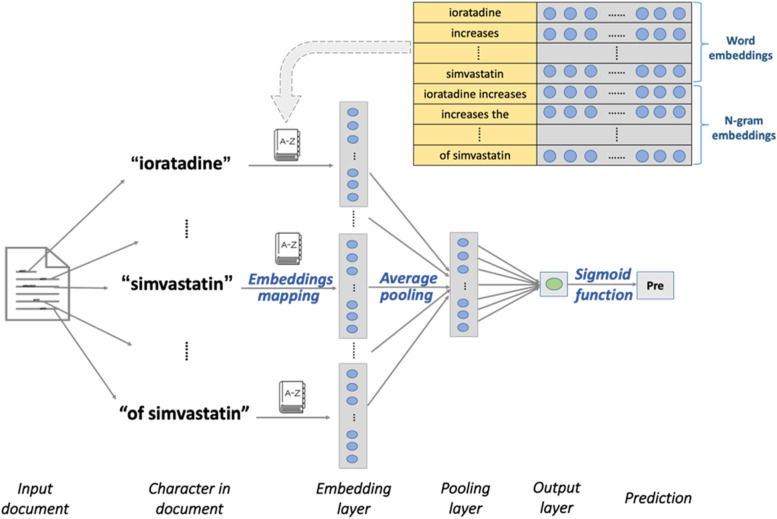
Background: Drug-drug interaction (DDI) information retrieval (IR) is an important natural language process (NLP) task from the PubMed literature. For the first time, active learning (AL) is studied in DDI IR analysis. DDI IR analysis from PubMed abstracts faces the challenges of relatively small positive DDI samples among overwhelmingly large negative samples. Random negative sampling and positive sampling are purposely designed to improve the efficiency of AL analysis. The consistency of random negative sampling and positive sampling is shown in the paper.
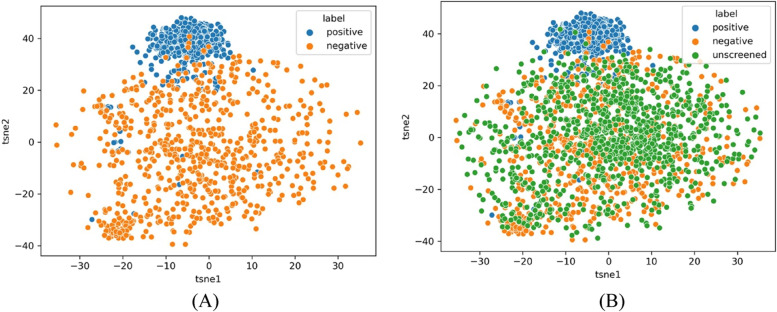
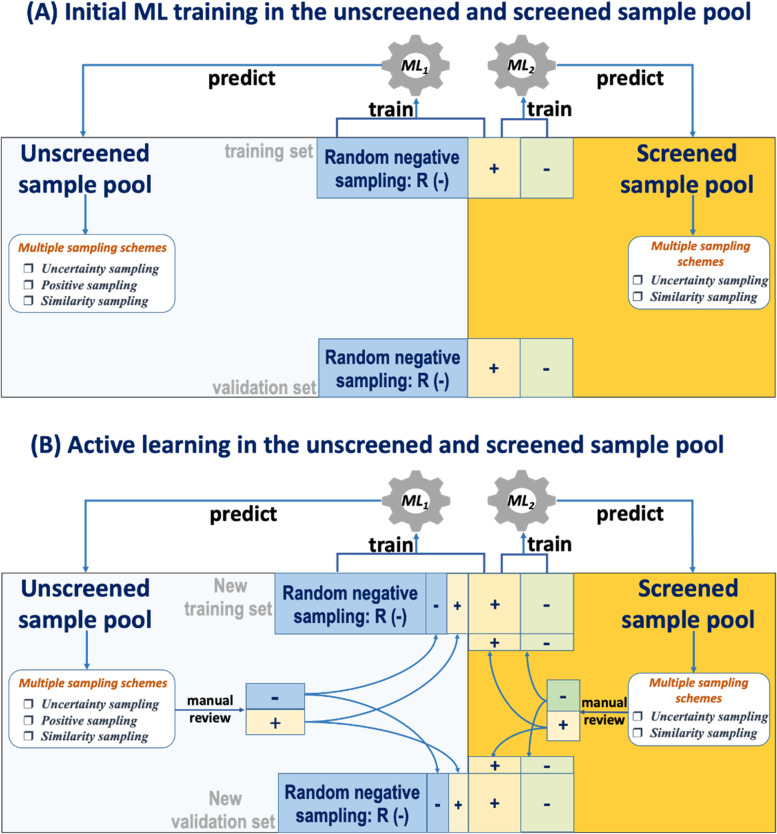
Results: PubMed abstracts are divided into two pools. Screened pool contains all abstracts that pass the DDI keywords query in PubMed, while unscreened pool includes all the other abstracts. At a prespecified recall rate of 0.95, DDI IR analysis precision is evaluated and compared. In screened pool IR analysis using supporting vector machine (SVM), similarity sampling plus uncertainty sampling improves the precision over uncertainty sampling, from 0.89 to 0.92 respectively. In the unscreened pool IR analysis, the integrated random negative sampling, positive sampling, and similarity sampling improve the precision over uncertainty sampling along, from 0.72 to 0.81 respectively. When we change the SVM to a deep learning method, all sampling schemes consistently improve DDI AL analysis in both screened pool and unscreened pool. Deep learning has significant improvement of precision over SVM, 0.96 vs. 0.92 in screened pool, and 0.90 vs. 0.81 in the unscreened pool, respectively.
Conclusions: By integrating various sampling schemes and deep learning algorithms into AL, the DDI IR analysis from literature is significantly improved. The random negative sampling and positive sampling are highly effective methods in improving AL analysis where the positive and negative samples are extremely imbalanced.
期刊介绍:
Journal of Biomedical Semantics addresses issues of semantic enrichment and semantic processing in the biomedical domain. The scope of the journal covers two main areas:
Infrastructure for biomedical semantics: focusing on semantic resources and repositories, meta-data management and resource description, knowledge representation and semantic frameworks, the Biomedical Semantic Web, and semantic interoperability.
Semantic mining, annotation, and analysis: focusing on approaches and applications of semantic resources; and tools for investigation, reasoning, prediction, and discoveries in biomedicine.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
