A comparative study of model-centric and data-centric approaches in the development of cardiovascular disease risk prediction models in the UK Biobank.
Mohammad Mamouei, Thomas Fisher, Shishir Rao, Yikuan Li, Ghomalreza Salimi-Khorshidi, Kazem Rahimi
{"title":"A comparative study of model-centric and data-centric approaches in the development of cardiovascular disease risk prediction models in the UK Biobank.","authors":"Mohammad Mamouei, Thomas Fisher, Shishir Rao, Yikuan Li, Ghomalreza Salimi-Khorshidi, Kazem Rahimi","doi":"10.1093/ehjdh/ztad033","DOIUrl":null,"url":null,"abstract":"<p><strong>Aims: </strong>A diverse set of factors influence cardiovascular diseases (CVDs), but a systematic investigation of the interplay between these determinants and the contribution of each to CVD incidence prediction is largely missing from the literature. In this study, we leverage one of the most comprehensive biobanks worldwide, the UK Biobank, to investigate the contribution of different risk factor categories to more accurate incidence predictions in the overall population, by sex, different age groups, and ethnicity.</p><p><strong>Methods and results: </strong>The investigated categories include the history of medical events, behavioural factors, socioeconomic factors, environmental factors, and measurements. We included data from a cohort of 405 257 participants aged 37-73 years and trained various machine learning and deep learning models on different subsets of risk factors to predict CVD incidence. Each of the models was trained on the complete set of predictors and subsets where each category was excluded. The results were benchmarked against QRISK3. The findings highlight that (i) leveraging a more comprehensive medical history substantially improves model performance. Relative to QRISK3, the best performing models improved the discrimination by 3.78% and improved precision by 1.80%. (ii) Both model- and data-centric approaches are necessary to improve predictive performance. The benefits of using a comprehensive history of diseases were far more pronounced when a neural sequence model, BEHRT, was used. This highlights the importance of the temporality of medical events that existing clinical risk models fail to capture. (iii) Besides the history of diseases, socioeconomic factors and measurements had small but significant independent contributions to the predictive performance.</p><p><strong>Conclusion: </strong>These findings emphasize the need for considering broad determinants and novel modelling approaches to enhance CVD incidence prediction.</p>","PeriodicalId":72965,"journal":{"name":"European heart journal. Digital health","volume":"4 4","pages":"337-346"},"PeriodicalIF":4.4000,"publicationDate":"2023-05-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/0e/a6/ztad033.PMC10393888.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"European heart journal. Digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/ehjdh/ztad033","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/8/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"CARDIAC & CARDIOVASCULAR SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
Aims: A diverse set of factors influence cardiovascular diseases (CVDs), but a systematic investigation of the interplay between these determinants and the contribution of each to CVD incidence prediction is largely missing from the literature. In this study, we leverage one of the most comprehensive biobanks worldwide, the UK Biobank, to investigate the contribution of different risk factor categories to more accurate incidence predictions in the overall population, by sex, different age groups, and ethnicity.
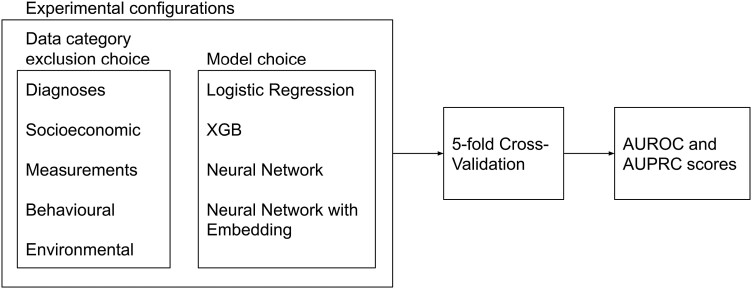
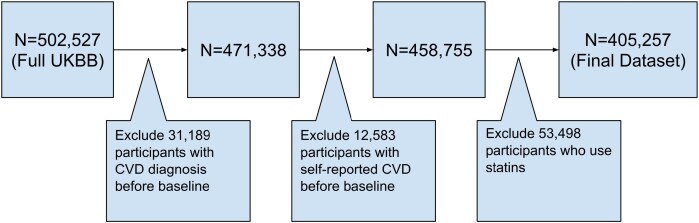
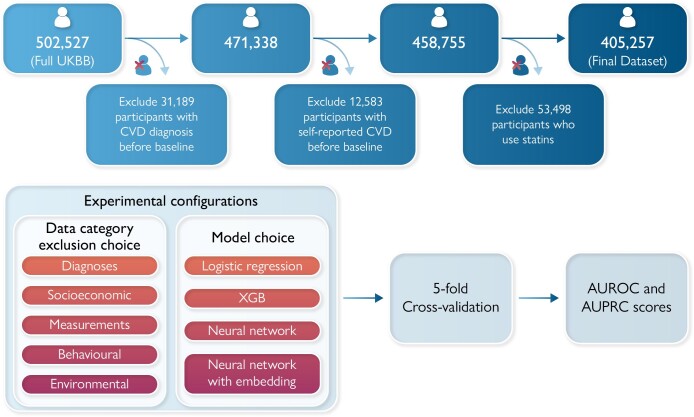
Methods and results: The investigated categories include the history of medical events, behavioural factors, socioeconomic factors, environmental factors, and measurements. We included data from a cohort of 405 257 participants aged 37-73 years and trained various machine learning and deep learning models on different subsets of risk factors to predict CVD incidence. Each of the models was trained on the complete set of predictors and subsets where each category was excluded. The results were benchmarked against QRISK3. The findings highlight that (i) leveraging a more comprehensive medical history substantially improves model performance. Relative to QRISK3, the best performing models improved the discrimination by 3.78% and improved precision by 1.80%. (ii) Both model- and data-centric approaches are necessary to improve predictive performance. The benefits of using a comprehensive history of diseases were far more pronounced when a neural sequence model, BEHRT, was used. This highlights the importance of the temporality of medical events that existing clinical risk models fail to capture. (iii) Besides the history of diseases, socioeconomic factors and measurements had small but significant independent contributions to the predictive performance.
Conclusion: These findings emphasize the need for considering broad determinants and novel modelling approaches to enhance CVD incidence prediction.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
