Qiao Jin, Zifeng Wang, Charalampos S Floudas, Fangyuan Chen, Changlin Gong, Dara Bracken-Clarke, Elisabetta Xue, Yifan Yang, Jimeng Sun, Zhiyong Lu
{"title":"用大型语言模型将患者与临床试验相匹配。","authors":"Qiao Jin, Zifeng Wang, Charalampos S Floudas, Fangyuan Chen, Changlin Gong, Dara Bracken-Clarke, Elisabetta Xue, Yifan Yang, Jimeng Sun, Zhiyong Lu","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>Patient recruitment is challenging for clinical trials. We introduce TrialGPT, an end-to-end framework for zero-shot patient-to-trial matching with large language models. TrialGPT comprises three modules: it first performs large-scale filtering to retrieve candidate trials (TrialGPT-Retrieval); then predicts criterion-level patient eligibility (TrialGPT-Matching); and finally generates trial-level scores (TrialGPT-Ranking). We evaluate TrialGPT on three cohorts of 183 synthetic patients with over 75,000 trial annotations. TrialGPT-Retrieval can recall over 90% of relevant trials using less than 6% of the initial collection. Manual evaluations on 1,015 patient-criterion pairs show that TrialGPT-Matching achieves an accuracy of 87.3% with faithful explanations, close to the expert performance. The TrialGPT-Ranking scores are highly correlated with human judgments and outperform the best-competing models by 43.8% in ranking and excluding trials. Furthermore, our user study reveals that TrialGPT can reduce the screening time by 42.6% in patient recruitment. Overall, these results have demonstrated promising opportunities for patient-to-trial matching with TriaGPT.</p>","PeriodicalId":8425,"journal":{"name":"ArXiv","volume":" ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-11-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10418514/pdf/","citationCount":"0","resultStr":"{\"title\":\"Matching Patients to Clinical Trials with Large Language Models.\",\"authors\":\"Qiao Jin, Zifeng Wang, Charalampos S Floudas, Fangyuan Chen, Changlin Gong, Dara Bracken-Clarke, Elisabetta Xue, Yifan Yang, Jimeng Sun, Zhiyong Lu\",\"doi\":\"\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Patient recruitment is challenging for clinical trials. We introduce TrialGPT, an end-to-end framework for zero-shot patient-to-trial matching with large language models. TrialGPT comprises three modules: it first performs large-scale filtering to retrieve candidate trials (TrialGPT-Retrieval); then predicts criterion-level patient eligibility (TrialGPT-Matching); and finally generates trial-level scores (TrialGPT-Ranking). We evaluate TrialGPT on three cohorts of 183 synthetic patients with over 75,000 trial annotations. TrialGPT-Retrieval can recall over 90% of relevant trials using less than 6% of the initial collection. Manual evaluations on 1,015 patient-criterion pairs show that TrialGPT-Matching achieves an accuracy of 87.3% with faithful explanations, close to the expert performance. The TrialGPT-Ranking scores are highly correlated with human judgments and outperform the best-competing models by 43.8% in ranking and excluding trials. Furthermore, our user study reveals that TrialGPT can reduce the screening time by 42.6% in patient recruitment. Overall, these results have demonstrated promising opportunities for patient-to-trial matching with TriaGPT.</p>\",\"PeriodicalId\":8425,\"journal\":{\"name\":\"ArXiv\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-11-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10418514/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"ArXiv\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"ArXiv","FirstCategoryId":"1085","ListUrlMain":"","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Matching Patients to Clinical Trials with Large Language Models.
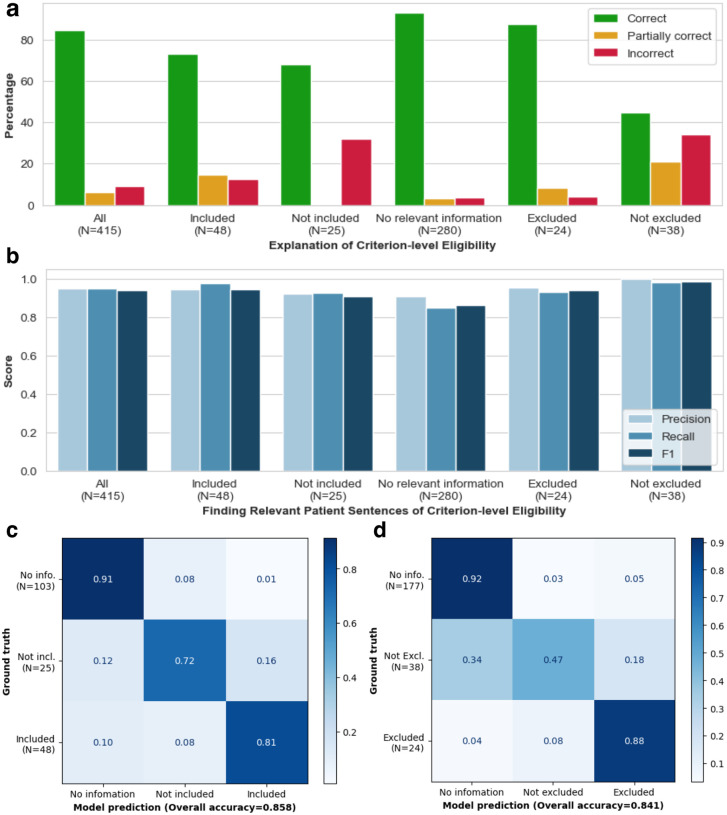
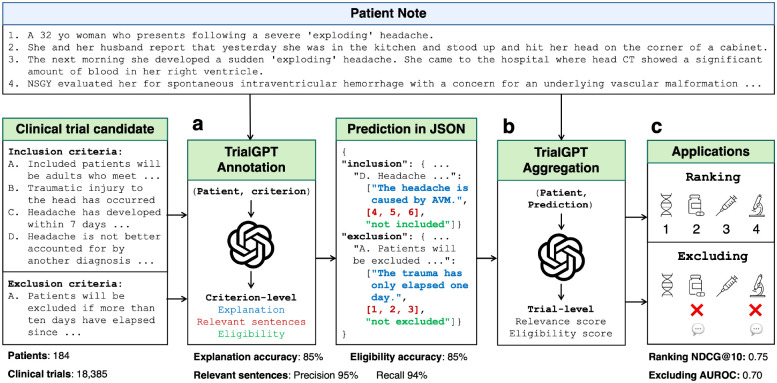
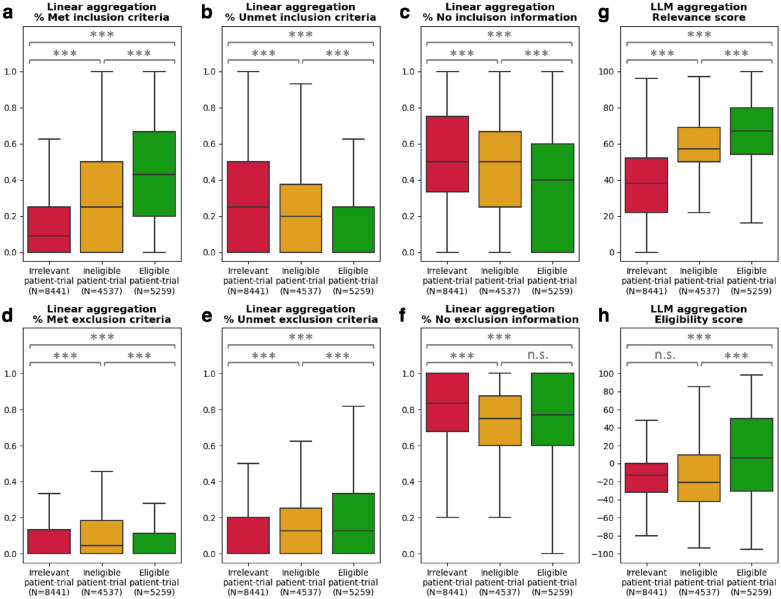
Patient recruitment is challenging for clinical trials. We introduce TrialGPT, an end-to-end framework for zero-shot patient-to-trial matching with large language models. TrialGPT comprises three modules: it first performs large-scale filtering to retrieve candidate trials (TrialGPT-Retrieval); then predicts criterion-level patient eligibility (TrialGPT-Matching); and finally generates trial-level scores (TrialGPT-Ranking). We evaluate TrialGPT on three cohorts of 183 synthetic patients with over 75,000 trial annotations. TrialGPT-Retrieval can recall over 90% of relevant trials using less than 6% of the initial collection. Manual evaluations on 1,015 patient-criterion pairs show that TrialGPT-Matching achieves an accuracy of 87.3% with faithful explanations, close to the expert performance. The TrialGPT-Ranking scores are highly correlated with human judgments and outperform the best-competing models by 43.8% in ranking and excluding trials. Furthermore, our user study reveals that TrialGPT can reduce the screening time by 42.6% in patient recruitment. Overall, these results have demonstrated promising opportunities for patient-to-trial matching with TriaGPT.
 分享
分享




 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
