Andrea Mastropietro, Gianluca De Carlo, Aris Anagnostopoulos
{"title":"XGDAG:通过图神经网络解释基因与疾病的关联。","authors":"Andrea Mastropietro, Gianluca De Carlo, Aris Anagnostopoulos","doi":"10.1093/bioinformatics/btad482","DOIUrl":null,"url":null,"abstract":"Abstract Motivation Disease gene prioritization consists in identifying genes that are likely to be involved in the mechanisms of a given disease, providing a ranking of such genes. Recently, the research community has used computational methods to uncover unknown gene–disease associations; these methods range from combinatorial to machine learning-based approaches. In particular, during the last years, approaches based on deep learning have provided superior results compared to more traditional ones. Yet, the problem with these is their inherent black-box structure, which prevents interpretability. Results We propose a new methodology for disease gene discovery, which leverages graph-structured data using graph neural networks (GNNs) along with an explainability phase for determining the ranking of candidate genes and understanding the model’s output. Our approach is based on a positive–unlabeled learning strategy, which outperforms existing gene discovery methods by exploiting GNNs in a non-black-box fashion. Our methodology is effective even in scenarios where a large number of associated genes need to be retrieved, in which gene prioritization methods often tend to lose their reliability. Availability and implementation The source code of XGDAG is available on GitHub at: https://github.com/GiDeCarlo/XGDAG. The data underlying this article are available at: https://www.disgenet.org/, https://thebiogrid.org/, https://doi.org/10.1371/journal.pcbi.1004120.s003, and https://doi.org/10.1371/journal.pcbi.1004120.s004.","PeriodicalId":8903,"journal":{"name":"Bioinformatics","volume":"39 8","pages":""},"PeriodicalIF":5.4000,"publicationDate":"2023-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10421968/pdf/","citationCount":"0","resultStr":"{\"title\":\"XGDAG: explainable gene-disease associations via graph neural networks.\",\"authors\":\"Andrea Mastropietro, Gianluca De Carlo, Aris Anagnostopoulos\",\"doi\":\"10.1093/bioinformatics/btad482\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Abstract Motivation Disease gene prioritization consists in identifying genes that are likely to be involved in the mechanisms of a given disease, providing a ranking of such genes. Recently, the research community has used computational methods to uncover unknown gene–disease associations; these methods range from combinatorial to machine learning-based approaches. In particular, during the last years, approaches based on deep learning have provided superior results compared to more traditional ones. Yet, the problem with these is their inherent black-box structure, which prevents interpretability. Results We propose a new methodology for disease gene discovery, which leverages graph-structured data using graph neural networks (GNNs) along with an explainability phase for determining the ranking of candidate genes and understanding the model’s output. Our approach is based on a positive–unlabeled learning strategy, which outperforms existing gene discovery methods by exploiting GNNs in a non-black-box fashion. Our methodology is effective even in scenarios where a large number of associated genes need to be retrieved, in which gene prioritization methods often tend to lose their reliability. Availability and implementation The source code of XGDAG is available on GitHub at: https://github.com/GiDeCarlo/XGDAG. The data underlying this article are available at: https://www.disgenet.org/, https://thebiogrid.org/, https://doi.org/10.1371/journal.pcbi.1004120.s003, and https://doi.org/10.1371/journal.pcbi.1004120.s004.\",\"PeriodicalId\":8903,\"journal\":{\"name\":\"Bioinformatics\",\"volume\":\"39 8\",\"pages\":\"\"},\"PeriodicalIF\":5.4000,\"publicationDate\":\"2023-08-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10421968/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1093/bioinformatics/btad482\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOCHEMICAL RESEARCH METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bioinformatics/btad482","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
XGDAG: explainable gene-disease associations via graph neural networks.
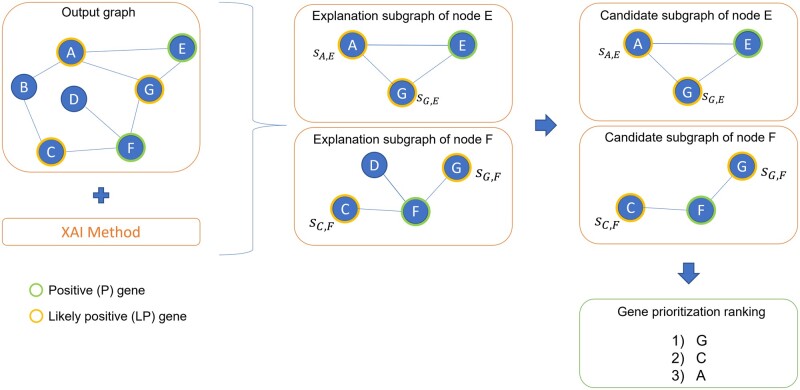
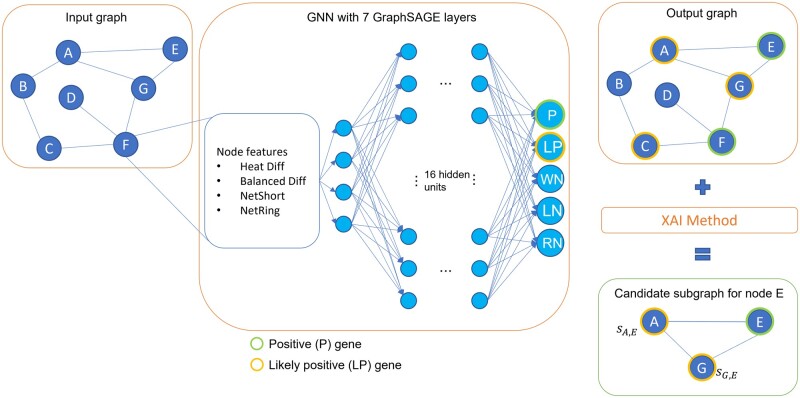
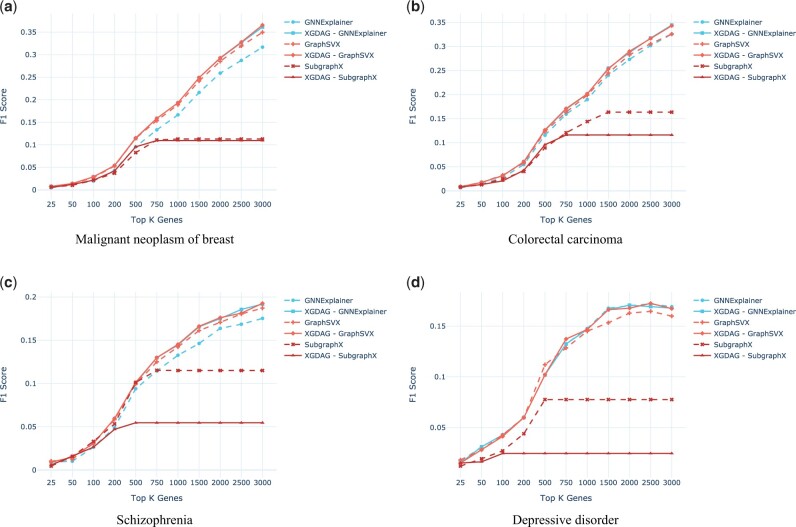
Abstract Motivation Disease gene prioritization consists in identifying genes that are likely to be involved in the mechanisms of a given disease, providing a ranking of such genes. Recently, the research community has used computational methods to uncover unknown gene–disease associations; these methods range from combinatorial to machine learning-based approaches. In particular, during the last years, approaches based on deep learning have provided superior results compared to more traditional ones. Yet, the problem with these is their inherent black-box structure, which prevents interpretability. Results We propose a new methodology for disease gene discovery, which leverages graph-structured data using graph neural networks (GNNs) along with an explainability phase for determining the ranking of candidate genes and understanding the model’s output. Our approach is based on a positive–unlabeled learning strategy, which outperforms existing gene discovery methods by exploiting GNNs in a non-black-box fashion. Our methodology is effective even in scenarios where a large number of associated genes need to be retrieved, in which gene prioritization methods often tend to lose their reliability. Availability and implementation The source code of XGDAG is available on GitHub at: https://github.com/GiDeCarlo/XGDAG. The data underlying this article are available at: https://www.disgenet.org/, https://thebiogrid.org/, https://doi.org/10.1371/journal.pcbi.1004120.s003, and https://doi.org/10.1371/journal.pcbi.1004120.s004.
期刊介绍:
The leading journal in its field, Bioinformatics publishes the highest quality scientific papers and review articles of interest to academic and industrial researchers. Its main focus is on new developments in genome bioinformatics and computational biology. Two distinct sections within the journal - Discovery Notes and Application Notes- focus on shorter papers; the former reporting biologically interesting discoveries using computational methods, the latter exploring the applications used for experiments.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
