{"title":"利用分子片段描述子预测致病性单氨基酸取代。","authors":"A Zadorozhny, A Smirnov, D Filimonov, A Lagunin","doi":"10.1093/bioinformatics/btad484","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Next Generation Sequencing technologies make it possible to detect rare genetic variants in individual patients. Currently, more than a dozen software and web services have been created to predict the pathogenicity of variants related with changing of amino acid residues. Despite considerable efforts in this area, at the moment there is no ideal method to classify pathogenic and harmless variants, and the assessment of the pathogenicity is often contradictory. In this article, we propose to use peptides structural formulas of proteins as an amino acid residues substitutions description, rather than a single-letter code. This allowed us to investigate the effectiveness of chemoinformatics approach to assess the pathogenicity of variants associated with amino acid substitutions.</p><p><strong>Results: </strong>The structure-activity relationships analysis relying on protein-specific data and atom centric substructural multilevel neighborhoods of atoms (MNA) descriptors of molecular fragments appeared to be suitable for predicting the pathogenic effect of single amino acid variants. MNA-based Naïve Bayes classifier algorithm, ClinVar and humsavar data were used for the creation of structure-activity relationships models for 10 proteins. The performance of the models was compared with 11 different predicting tools: 8 individual (SIFT 4G, Polyphen2 HDIV, MutationAssessor, PROVEAN, FATHMM, MVP, LIST-S2, MutPred) and 3 consensus (M-CAP, MetaSVM, MetaLR). The accuracy of MNA-based method varies for the proteins (AUC: 0.631-0.993; MCC: 0.191-0.891). It was similar for both the results of comparisons with the other individual predictors and third-party protein-specific predictors. For several proteins (BRCA1, BRCA2, COL1A2, and RYR1), the performance of the MNA-based method was outstanding, capable of capturing the pathogenic effect of structural changes in amino acid substitutions.</p><p><strong>Availability and implementation: </strong>The datasets are available as supplemental data at Bioinformatics online. A python script to convert amino acid and nucleotide sequences from single-letter codes to SD files is available at https://github.com/SmirnygaTotoshka/SequenceToSDF. The authors provide trial licenses for MultiPASS software to interested readers upon request.</p>","PeriodicalId":8903,"journal":{"name":"Bioinformatics","volume":"39 8","pages":""},"PeriodicalIF":4.4000,"publicationDate":"2023-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10435372/pdf/","citationCount":"3","resultStr":"{\"title\":\"Prediction of pathogenic single amino acid substitutions using molecular fragment descriptors.\",\"authors\":\"A Zadorozhny, A Smirnov, D Filimonov, A Lagunin\",\"doi\":\"10.1093/bioinformatics/btad484\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Motivation: </strong>Next Generation Sequencing technologies make it possible to detect rare genetic variants in individual patients. Currently, more than a dozen software and web services have been created to predict the pathogenicity of variants related with changing of amino acid residues. Despite considerable efforts in this area, at the moment there is no ideal method to classify pathogenic and harmless variants, and the assessment of the pathogenicity is often contradictory. In this article, we propose to use peptides structural formulas of proteins as an amino acid residues substitutions description, rather than a single-letter code. This allowed us to investigate the effectiveness of chemoinformatics approach to assess the pathogenicity of variants associated with amino acid substitutions.</p><p><strong>Results: </strong>The structure-activity relationships analysis relying on protein-specific data and atom centric substructural multilevel neighborhoods of atoms (MNA) descriptors of molecular fragments appeared to be suitable for predicting the pathogenic effect of single amino acid variants. MNA-based Naïve Bayes classifier algorithm, ClinVar and humsavar data were used for the creation of structure-activity relationships models for 10 proteins. The performance of the models was compared with 11 different predicting tools: 8 individual (SIFT 4G, Polyphen2 HDIV, MutationAssessor, PROVEAN, FATHMM, MVP, LIST-S2, MutPred) and 3 consensus (M-CAP, MetaSVM, MetaLR). The accuracy of MNA-based method varies for the proteins (AUC: 0.631-0.993; MCC: 0.191-0.891). It was similar for both the results of comparisons with the other individual predictors and third-party protein-specific predictors. For several proteins (BRCA1, BRCA2, COL1A2, and RYR1), the performance of the MNA-based method was outstanding, capable of capturing the pathogenic effect of structural changes in amino acid substitutions.</p><p><strong>Availability and implementation: </strong>The datasets are available as supplemental data at Bioinformatics online. A python script to convert amino acid and nucleotide sequences from single-letter codes to SD files is available at https://github.com/SmirnygaTotoshka/SequenceToSDF. The authors provide trial licenses for MultiPASS software to interested readers upon request.</p>\",\"PeriodicalId\":8903,\"journal\":{\"name\":\"Bioinformatics\",\"volume\":\"39 8\",\"pages\":\"\"},\"PeriodicalIF\":4.4000,\"publicationDate\":\"2023-08-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10435372/pdf/\",\"citationCount\":\"3\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1093/bioinformatics/btad484\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOCHEMICAL RESEARCH METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bioinformatics/btad484","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
Prediction of pathogenic single amino acid substitutions using molecular fragment descriptors.
Motivation: Next Generation Sequencing technologies make it possible to detect rare genetic variants in individual patients. Currently, more than a dozen software and web services have been created to predict the pathogenicity of variants related with changing of amino acid residues. Despite considerable efforts in this area, at the moment there is no ideal method to classify pathogenic and harmless variants, and the assessment of the pathogenicity is often contradictory. In this article, we propose to use peptides structural formulas of proteins as an amino acid residues substitutions description, rather than a single-letter code. This allowed us to investigate the effectiveness of chemoinformatics approach to assess the pathogenicity of variants associated with amino acid substitutions.
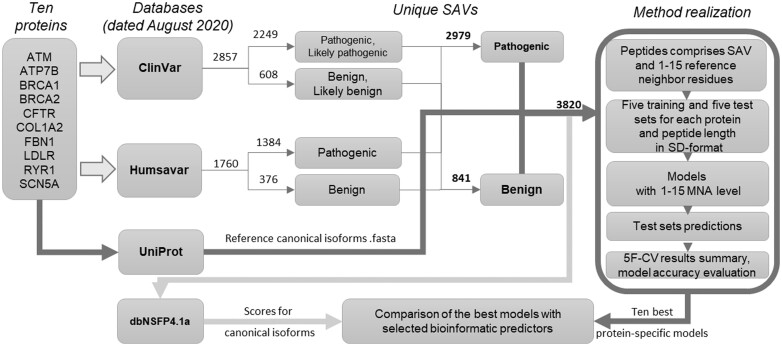
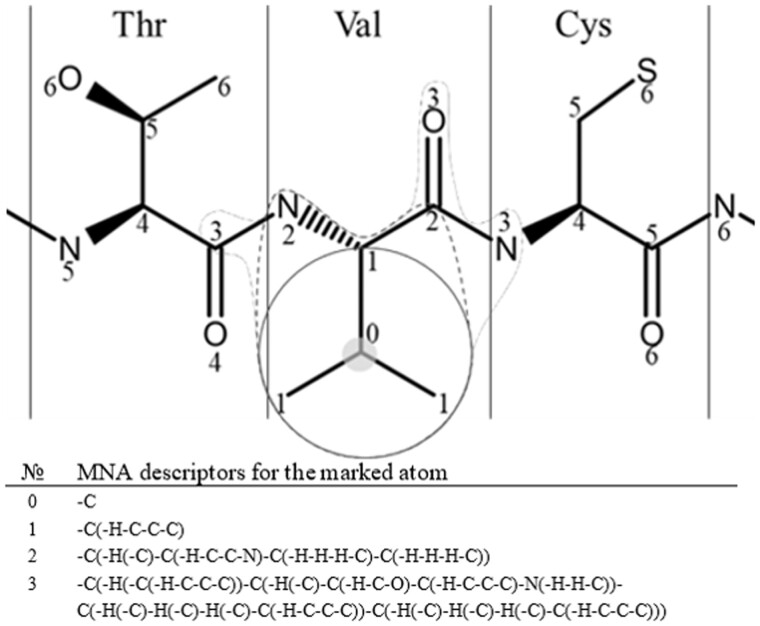
Results: The structure-activity relationships analysis relying on protein-specific data and atom centric substructural multilevel neighborhoods of atoms (MNA) descriptors of molecular fragments appeared to be suitable for predicting the pathogenic effect of single amino acid variants. MNA-based Naïve Bayes classifier algorithm, ClinVar and humsavar data were used for the creation of structure-activity relationships models for 10 proteins. The performance of the models was compared with 11 different predicting tools: 8 individual (SIFT 4G, Polyphen2 HDIV, MutationAssessor, PROVEAN, FATHMM, MVP, LIST-S2, MutPred) and 3 consensus (M-CAP, MetaSVM, MetaLR). The accuracy of MNA-based method varies for the proteins (AUC: 0.631-0.993; MCC: 0.191-0.891). It was similar for both the results of comparisons with the other individual predictors and third-party protein-specific predictors. For several proteins (BRCA1, BRCA2, COL1A2, and RYR1), the performance of the MNA-based method was outstanding, capable of capturing the pathogenic effect of structural changes in amino acid substitutions.
Availability and implementation: The datasets are available as supplemental data at Bioinformatics online. A python script to convert amino acid and nucleotide sequences from single-letter codes to SD files is available at https://github.com/SmirnygaTotoshka/SequenceToSDF. The authors provide trial licenses for MultiPASS software to interested readers upon request.
期刊介绍:
The leading journal in its field, Bioinformatics publishes the highest quality scientific papers and review articles of interest to academic and industrial researchers. Its main focus is on new developments in genome bioinformatics and computational biology. Two distinct sections within the journal - Discovery Notes and Application Notes- focus on shorter papers; the former reporting biologically interesting discoveries using computational methods, the latter exploring the applications used for experiments.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
