{"title":"防漏PDBBind:蛋白质配体复合物的重组数据集,用于更通用的结合亲和力预测。","authors":"Jie Li, Xingyi Guan, Oufan Zhang, Kunyang Sun, Yingze Wang, Dorian Bagni, Teresa Head-Gordon","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>Many physics-based and machine-learned scoring functions (SFs) used to predict protein-ligand binding free energies have been trained on the PDBBind dataset. However, it is controversial as to whether new SFs are actually improving since the general, refined, and core datasets of PDBBind are cross-contaminated with proteins and ligands with high similarity, and hence they may not perform comparably well in binding prediction of new protein-ligand complexes. In this work we have carefully prepared a cleaned PDBBind data set of non-covalent binders that are split into training, validation, and test datasets to control for data leakage, defined as proteins and ligands with high sequence and structural similarity. The resulting leak-proof (LP)-PDBBind data is used to retrain four popular SFs: AutoDock Vina, Random Forest (RF)-Score, InteractionGraphNet (IGN), and DeepDTA, to better test their capabilities when applied to new protein-ligand complexes. In particular we have formulated a new independent data set, BDB2020+, by matching high quality binding free energies from BindingDB with co-crystalized ligand-protein complexes from the PDB that have been deposited since 2020. Based on all the benchmark results, the retrained models using LP-PDBBind consistently perform better, with IGN especially being recommended for scoring and ranking applications for new protein-ligand systems.</p>","PeriodicalId":8425,"journal":{"name":"ArXiv","volume":" ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-05-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10462179/pdf/","citationCount":"0","resultStr":"{\"title\":\"Leak Proof PDBBind: A Reorganized Dataset of Protein-Ligand Complexes for More Generalizable Binding Affinity Prediction.\",\"authors\":\"Jie Li, Xingyi Guan, Oufan Zhang, Kunyang Sun, Yingze Wang, Dorian Bagni, Teresa Head-Gordon\",\"doi\":\"\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Many physics-based and machine-learned scoring functions (SFs) used to predict protein-ligand binding free energies have been trained on the PDBBind dataset. However, it is controversial as to whether new SFs are actually improving since the general, refined, and core datasets of PDBBind are cross-contaminated with proteins and ligands with high similarity, and hence they may not perform comparably well in binding prediction of new protein-ligand complexes. In this work we have carefully prepared a cleaned PDBBind data set of non-covalent binders that are split into training, validation, and test datasets to control for data leakage, defined as proteins and ligands with high sequence and structural similarity. The resulting leak-proof (LP)-PDBBind data is used to retrain four popular SFs: AutoDock Vina, Random Forest (RF)-Score, InteractionGraphNet (IGN), and DeepDTA, to better test their capabilities when applied to new protein-ligand complexes. In particular we have formulated a new independent data set, BDB2020+, by matching high quality binding free energies from BindingDB with co-crystalized ligand-protein complexes from the PDB that have been deposited since 2020. Based on all the benchmark results, the retrained models using LP-PDBBind consistently perform better, with IGN especially being recommended for scoring and ranking applications for new protein-ligand systems.</p>\",\"PeriodicalId\":8425,\"journal\":{\"name\":\"ArXiv\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-05-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10462179/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"ArXiv\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"ArXiv","FirstCategoryId":"1085","ListUrlMain":"","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Leak Proof PDBBind: A Reorganized Dataset of Protein-Ligand Complexes for More Generalizable Binding Affinity Prediction.
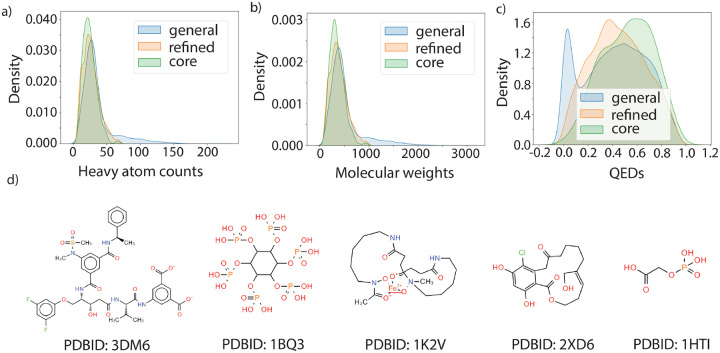
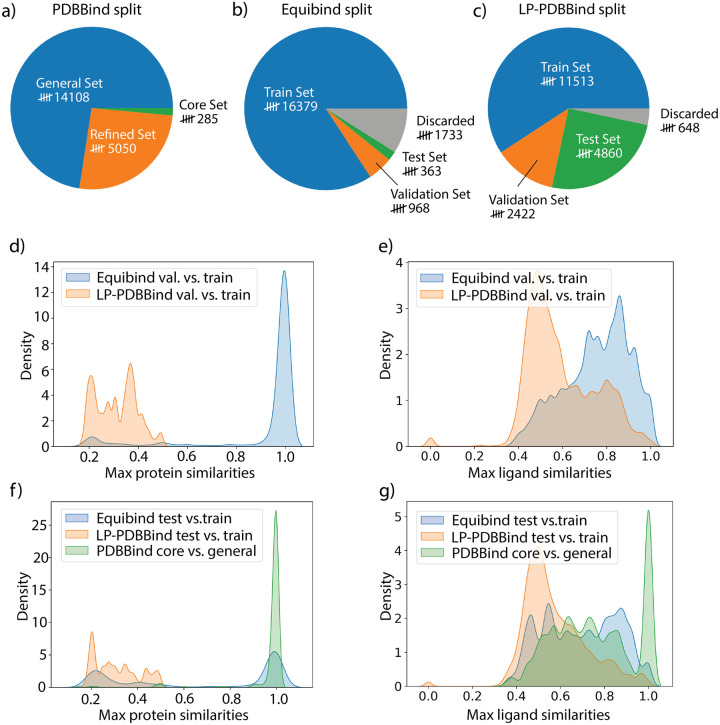
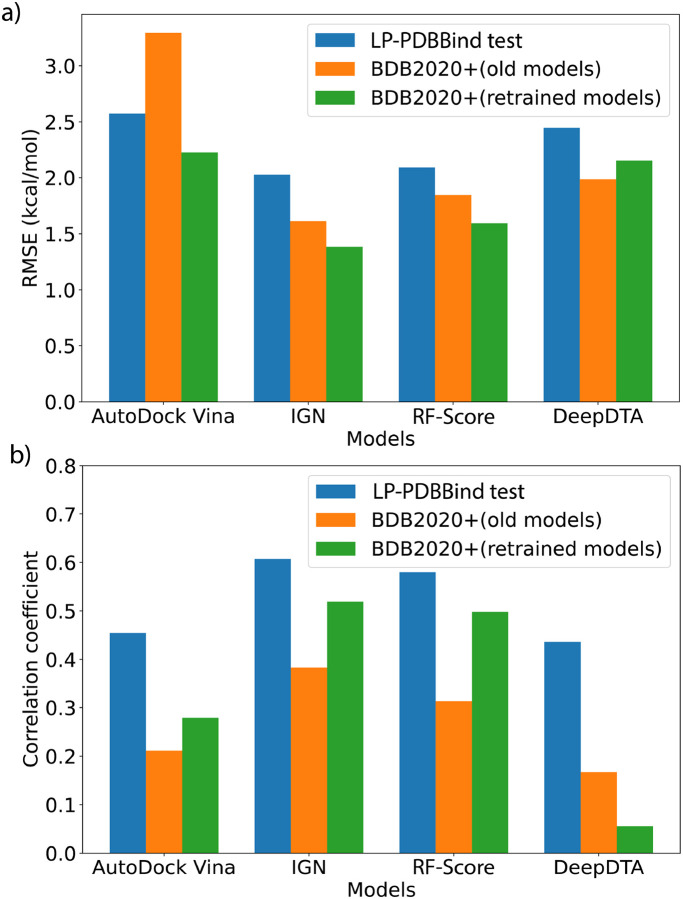
Many physics-based and machine-learned scoring functions (SFs) used to predict protein-ligand binding free energies have been trained on the PDBBind dataset. However, it is controversial as to whether new SFs are actually improving since the general, refined, and core datasets of PDBBind are cross-contaminated with proteins and ligands with high similarity, and hence they may not perform comparably well in binding prediction of new protein-ligand complexes. In this work we have carefully prepared a cleaned PDBBind data set of non-covalent binders that are split into training, validation, and test datasets to control for data leakage, defined as proteins and ligands with high sequence and structural similarity. The resulting leak-proof (LP)-PDBBind data is used to retrain four popular SFs: AutoDock Vina, Random Forest (RF)-Score, InteractionGraphNet (IGN), and DeepDTA, to better test their capabilities when applied to new protein-ligand complexes. In particular we have formulated a new independent data set, BDB2020+, by matching high quality binding free energies from BindingDB with co-crystalized ligand-protein complexes from the PDB that have been deposited since 2020. Based on all the benchmark results, the retrained models using LP-PDBBind consistently perform better, with IGN especially being recommended for scoring and ranking applications for new protein-ligand systems.
 分享
分享



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
