{"title":"利用ChatGPT对生物医学文本生成和挖掘进行了广泛的基准研究。","authors":"Qijie Chen, Haotong Sun, Haoyang Liu, Yinghui Jiang, Ting Ran, Xurui Jin, Xianglu Xiao, Zhimin Lin, Hongming Chen, Zhangmin Niu","doi":"10.1093/bioinformatics/btad557","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>In recent years, the development of natural language process (NLP) technologies and deep learning hardware has led to significant improvement in large language models (LLMs). The ChatGPT, the state-of-the-art LLM built on GPT-3.5 and GPT-4, shows excellent capabilities in general language understanding and reasoning. Researchers also tested the GPTs on a variety of NLP-related tasks and benchmarks and got excellent results. With exciting performance on daily chat, researchers began to explore the capacity of ChatGPT on expertise that requires professional education for human and we are interested in the biomedical domain.</p><p><strong>Results: </strong>To evaluate the performance of ChatGPT on biomedical-related tasks, this article presents a comprehensive benchmark study on the use of ChatGPT for biomedical corpus, including article abstracts, clinical trials description, biomedical questions, and so on. Typical NLP tasks like named entity recognization, relation extraction, sentence similarity, question and answering, and document classification are included. Overall, ChatGPT got a BLURB score of 58.50 while the state-of-the-art model had a score of 84.30. Through a series of experiments, we demonstrated the effectiveness and versatility of ChatGPT in biomedical text understanding, reasoning and generation, and the limitation of ChatGPT build on GPT-3.5.</p><p><strong>Availability and implementation: </strong>All the datasets are available from BLURB benchmark https://microsoft.github.io/BLURB/index.html. The prompts are described in the article.</p>","PeriodicalId":8903,"journal":{"name":"Bioinformatics","volume":" ","pages":""},"PeriodicalIF":5.4000,"publicationDate":"2023-09-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10562950/pdf/","citationCount":"0","resultStr":"{\"title\":\"An extensive benchmark study on biomedical text generation and mining with ChatGPT.\",\"authors\":\"Qijie Chen, Haotong Sun, Haoyang Liu, Yinghui Jiang, Ting Ran, Xurui Jin, Xianglu Xiao, Zhimin Lin, Hongming Chen, Zhangmin Niu\",\"doi\":\"10.1093/bioinformatics/btad557\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Motivation: </strong>In recent years, the development of natural language process (NLP) technologies and deep learning hardware has led to significant improvement in large language models (LLMs). The ChatGPT, the state-of-the-art LLM built on GPT-3.5 and GPT-4, shows excellent capabilities in general language understanding and reasoning. Researchers also tested the GPTs on a variety of NLP-related tasks and benchmarks and got excellent results. With exciting performance on daily chat, researchers began to explore the capacity of ChatGPT on expertise that requires professional education for human and we are interested in the biomedical domain.</p><p><strong>Results: </strong>To evaluate the performance of ChatGPT on biomedical-related tasks, this article presents a comprehensive benchmark study on the use of ChatGPT for biomedical corpus, including article abstracts, clinical trials description, biomedical questions, and so on. Typical NLP tasks like named entity recognization, relation extraction, sentence similarity, question and answering, and document classification are included. Overall, ChatGPT got a BLURB score of 58.50 while the state-of-the-art model had a score of 84.30. Through a series of experiments, we demonstrated the effectiveness and versatility of ChatGPT in biomedical text understanding, reasoning and generation, and the limitation of ChatGPT build on GPT-3.5.</p><p><strong>Availability and implementation: </strong>All the datasets are available from BLURB benchmark https://microsoft.github.io/BLURB/index.html. The prompts are described in the article.</p>\",\"PeriodicalId\":8903,\"journal\":{\"name\":\"Bioinformatics\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":5.4000,\"publicationDate\":\"2023-09-02\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10562950/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1093/bioinformatics/btad557\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOCHEMICAL RESEARCH METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bioinformatics/btad557","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
An extensive benchmark study on biomedical text generation and mining with ChatGPT.
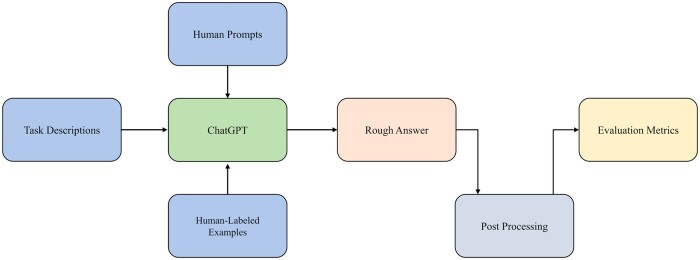
Motivation: In recent years, the development of natural language process (NLP) technologies and deep learning hardware has led to significant improvement in large language models (LLMs). The ChatGPT, the state-of-the-art LLM built on GPT-3.5 and GPT-4, shows excellent capabilities in general language understanding and reasoning. Researchers also tested the GPTs on a variety of NLP-related tasks and benchmarks and got excellent results. With exciting performance on daily chat, researchers began to explore the capacity of ChatGPT on expertise that requires professional education for human and we are interested in the biomedical domain.
Results: To evaluate the performance of ChatGPT on biomedical-related tasks, this article presents a comprehensive benchmark study on the use of ChatGPT for biomedical corpus, including article abstracts, clinical trials description, biomedical questions, and so on. Typical NLP tasks like named entity recognization, relation extraction, sentence similarity, question and answering, and document classification are included. Overall, ChatGPT got a BLURB score of 58.50 while the state-of-the-art model had a score of 84.30. Through a series of experiments, we demonstrated the effectiveness and versatility of ChatGPT in biomedical text understanding, reasoning and generation, and the limitation of ChatGPT build on GPT-3.5.
Availability and implementation: All the datasets are available from BLURB benchmark https://microsoft.github.io/BLURB/index.html. The prompts are described in the article.
期刊介绍:
The leading journal in its field, Bioinformatics publishes the highest quality scientific papers and review articles of interest to academic and industrial researchers. Its main focus is on new developments in genome bioinformatics and computational biology. Two distinct sections within the journal - Discovery Notes and Application Notes- focus on shorter papers; the former reporting biologically interesting discoveries using computational methods, the latter exploring the applications used for experiments.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
