Yan Hu, Vipina K Keloth, Kalpana Raja, Yong Chen, Hua Xu
{"title":"使用特定章节学习法从随机对照试验摘要中精确提取 PICO。","authors":"Yan Hu, Vipina K Keloth, Kalpana Raja, Yong Chen, Hua Xu","doi":"10.1093/bioinformatics/btad542","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Automated extraction of participants, intervention, comparison/control, and outcome (PICO) from the randomized controlled trial (RCT) abstracts is important for evidence synthesis. Previous studies have demonstrated the feasibility of applying natural language processing (NLP) for PICO extraction. However, the performance is not optimal due to the complexity of PICO information in RCT abstracts and the challenges involved in their annotation.</p><p><strong>Results: </strong>We propose a two-step NLP pipeline to extract PICO elements from RCT abstracts: (i) sentence classification using a prompt-based learning model and (ii) PICO extraction using a named entity recognition (NER) model. First, the sentences in abstracts were categorized into four sections namely background, methods, results, and conclusions. Next, the NER model was applied to extract the PICO elements from the sentences within the title and methods sections that include >96% of PICO information. We evaluated our proposed NLP pipeline on three datasets, the EBM-NLPmoddataset, a randomly selected and reannotated dataset of 500 RCT abstracts from the EBM-NLP corpus, a dataset of 150 COVID-19 RCT abstracts, and a dataset of 150 Alzheimer's disease (AD) RCT abstracts. The end-to-end evaluation reveals that our proposed approach achieved an overall micro F1 score of 0.833 on the EBM-NLPmod dataset, 0.928 on the COVID-19 dataset, and 0.899 on the AD dataset when measured at the token-level and an overall micro F1 score of 0.712 on EBM-NLPmod dataset, 0.850 on the COVID-19 dataset, and 0.805 on the AD dataset when measured at the entity-level.</p><p><strong>Availability: </strong>Our codes and datasets are publicly available at https://github.com/BIDS-Xu-Lab/section_specific_annotation_of_PICO.</p><p><strong>Supplementary information: </strong>Supplementary data are available at Bioinformatics online.</p>","PeriodicalId":8903,"journal":{"name":"Bioinformatics","volume":" ","pages":""},"PeriodicalIF":5.4000,"publicationDate":"2023-09-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10500081/pdf/","citationCount":"0","resultStr":"{\"title\":\"Towards precise PICO extraction from abstracts of randomized controlled trials using a section-specific learning approach.\",\"authors\":\"Yan Hu, Vipina K Keloth, Kalpana Raja, Yong Chen, Hua Xu\",\"doi\":\"10.1093/bioinformatics/btad542\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Motivation: </strong>Automated extraction of participants, intervention, comparison/control, and outcome (PICO) from the randomized controlled trial (RCT) abstracts is important for evidence synthesis. Previous studies have demonstrated the feasibility of applying natural language processing (NLP) for PICO extraction. However, the performance is not optimal due to the complexity of PICO information in RCT abstracts and the challenges involved in their annotation.</p><p><strong>Results: </strong>We propose a two-step NLP pipeline to extract PICO elements from RCT abstracts: (i) sentence classification using a prompt-based learning model and (ii) PICO extraction using a named entity recognition (NER) model. First, the sentences in abstracts were categorized into four sections namely background, methods, results, and conclusions. Next, the NER model was applied to extract the PICO elements from the sentences within the title and methods sections that include >96% of PICO information. We evaluated our proposed NLP pipeline on three datasets, the EBM-NLPmoddataset, a randomly selected and reannotated dataset of 500 RCT abstracts from the EBM-NLP corpus, a dataset of 150 COVID-19 RCT abstracts, and a dataset of 150 Alzheimer's disease (AD) RCT abstracts. The end-to-end evaluation reveals that our proposed approach achieved an overall micro F1 score of 0.833 on the EBM-NLPmod dataset, 0.928 on the COVID-19 dataset, and 0.899 on the AD dataset when measured at the token-level and an overall micro F1 score of 0.712 on EBM-NLPmod dataset, 0.850 on the COVID-19 dataset, and 0.805 on the AD dataset when measured at the entity-level.</p><p><strong>Availability: </strong>Our codes and datasets are publicly available at https://github.com/BIDS-Xu-Lab/section_specific_annotation_of_PICO.</p><p><strong>Supplementary information: </strong>Supplementary data are available at Bioinformatics online.</p>\",\"PeriodicalId\":8903,\"journal\":{\"name\":\"Bioinformatics\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":5.4000,\"publicationDate\":\"2023-09-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10500081/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1093/bioinformatics/btad542\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOCHEMICAL RESEARCH METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bioinformatics/btad542","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
Towards precise PICO extraction from abstracts of randomized controlled trials using a section-specific learning approach.
Motivation: Automated extraction of participants, intervention, comparison/control, and outcome (PICO) from the randomized controlled trial (RCT) abstracts is important for evidence synthesis. Previous studies have demonstrated the feasibility of applying natural language processing (NLP) for PICO extraction. However, the performance is not optimal due to the complexity of PICO information in RCT abstracts and the challenges involved in their annotation.
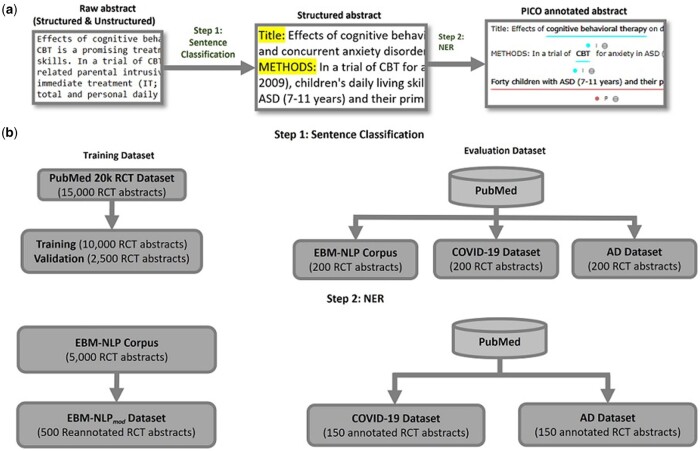
Results: We propose a two-step NLP pipeline to extract PICO elements from RCT abstracts: (i) sentence classification using a prompt-based learning model and (ii) PICO extraction using a named entity recognition (NER) model. First, the sentences in abstracts were categorized into four sections namely background, methods, results, and conclusions. Next, the NER model was applied to extract the PICO elements from the sentences within the title and methods sections that include >96% of PICO information. We evaluated our proposed NLP pipeline on three datasets, the EBM-NLPmoddataset, a randomly selected and reannotated dataset of 500 RCT abstracts from the EBM-NLP corpus, a dataset of 150 COVID-19 RCT abstracts, and a dataset of 150 Alzheimer's disease (AD) RCT abstracts. The end-to-end evaluation reveals that our proposed approach achieved an overall micro F1 score of 0.833 on the EBM-NLPmod dataset, 0.928 on the COVID-19 dataset, and 0.899 on the AD dataset when measured at the token-level and an overall micro F1 score of 0.712 on EBM-NLPmod dataset, 0.850 on the COVID-19 dataset, and 0.805 on the AD dataset when measured at the entity-level.
Availability: Our codes and datasets are publicly available at https://github.com/BIDS-Xu-Lab/section_specific_annotation_of_PICO.
Supplementary information: Supplementary data are available at Bioinformatics online.
期刊介绍:
The leading journal in its field, Bioinformatics publishes the highest quality scientific papers and review articles of interest to academic and industrial researchers. Its main focus is on new developments in genome bioinformatics and computational biology. Two distinct sections within the journal - Discovery Notes and Application Notes- focus on shorter papers; the former reporting biologically interesting discoveries using computational methods, the latter exploring the applications used for experiments.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
