Nina Zhou, Lu Wang, Simeone Marino, Yi Zhao, Ivo D Dinov
{"title":"DataSifter II:包含时变相关观测值的敏感信息的部分合成数据共享。","authors":"Nina Zhou, Lu Wang, Simeone Marino, Yi Zhao, Ivo D Dinov","doi":"10.1177/17483026211065379","DOIUrl":null,"url":null,"abstract":"<p><p>There is a significant public demand for rapid data-driven scientific investigations using aggregated sensitive information. However, many technical challenges and regulatory policies hinder efficient data sharing. In this study, we describe a partially synthetic data generation technique for creating anonymized data archives whose joint distributions closely resemble those of the original (sensitive) data. Specifically, we introduce the DataSifter technique for time-varying correlated data (DataSifter II), which relies on an iterative model-based imputation using generalized linear mixed model and random effects-expectation maximization tree. DataSifter II can be used to generate synthetic repeated measures data for testing and validating new analytical techniques. Compared to the multiple imputation method, DataSifter II application on simulated and real clinical data demonstrates that the new method provides extensive reduction of re-identification risk (data privacy) while preserving the analytical value (data utility) in the obfuscated data. The performance of the DataSifter II on a simulation involving 20% artificially missingness in the data, shows at least 80% reduction of the disclosure risk, compared to the multiple imputation method, without a substantial impact on the data analytical value. In a separate clinical data (Medical Information Mart for Intensive Care III) validation, a model-based statistical inference drawn from the original data agrees with an analogous analytical inference obtained using the DataSifter II obfuscated (<i>sifted</i>) data. For large time-varying datasets containing sensitive information, the proposed technique provides an automated tool for alleviating the barriers of data sharing and facilitating effective, advanced, and collaborative analytics.</p>","PeriodicalId":45079,"journal":{"name":"Journal of Algorithms & Computational Technology","volume":"16 ","pages":""},"PeriodicalIF":1.7000,"publicationDate":"2022-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/76/65/nihms-1800751.PMC9585991.pdf","citationCount":"0","resultStr":"{\"title\":\"DataSifter II: Partially synthetic data sharing of sensitive information containing time-varying correlated observations.\",\"authors\":\"Nina Zhou, Lu Wang, Simeone Marino, Yi Zhao, Ivo D Dinov\",\"doi\":\"10.1177/17483026211065379\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>There is a significant public demand for rapid data-driven scientific investigations using aggregated sensitive information. However, many technical challenges and regulatory policies hinder efficient data sharing. In this study, we describe a partially synthetic data generation technique for creating anonymized data archives whose joint distributions closely resemble those of the original (sensitive) data. Specifically, we introduce the DataSifter technique for time-varying correlated data (DataSifter II), which relies on an iterative model-based imputation using generalized linear mixed model and random effects-expectation maximization tree. DataSifter II can be used to generate synthetic repeated measures data for testing and validating new analytical techniques. Compared to the multiple imputation method, DataSifter II application on simulated and real clinical data demonstrates that the new method provides extensive reduction of re-identification risk (data privacy) while preserving the analytical value (data utility) in the obfuscated data. The performance of the DataSifter II on a simulation involving 20% artificially missingness in the data, shows at least 80% reduction of the disclosure risk, compared to the multiple imputation method, without a substantial impact on the data analytical value. In a separate clinical data (Medical Information Mart for Intensive Care III) validation, a model-based statistical inference drawn from the original data agrees with an analogous analytical inference obtained using the DataSifter II obfuscated (<i>sifted</i>) data. For large time-varying datasets containing sensitive information, the proposed technique provides an automated tool for alleviating the barriers of data sharing and facilitating effective, advanced, and collaborative analytics.</p>\",\"PeriodicalId\":45079,\"journal\":{\"name\":\"Journal of Algorithms & Computational Technology\",\"volume\":\"16 \",\"pages\":\"\"},\"PeriodicalIF\":1.7000,\"publicationDate\":\"2022-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/76/65/nihms-1800751.PMC9585991.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Algorithms & Computational Technology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1177/17483026211065379\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/1/20 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q4\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Algorithms & Computational Technology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1177/17483026211065379","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/1/20 0:00:00","PubModel":"Epub","JCR":"Q4","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
摘要
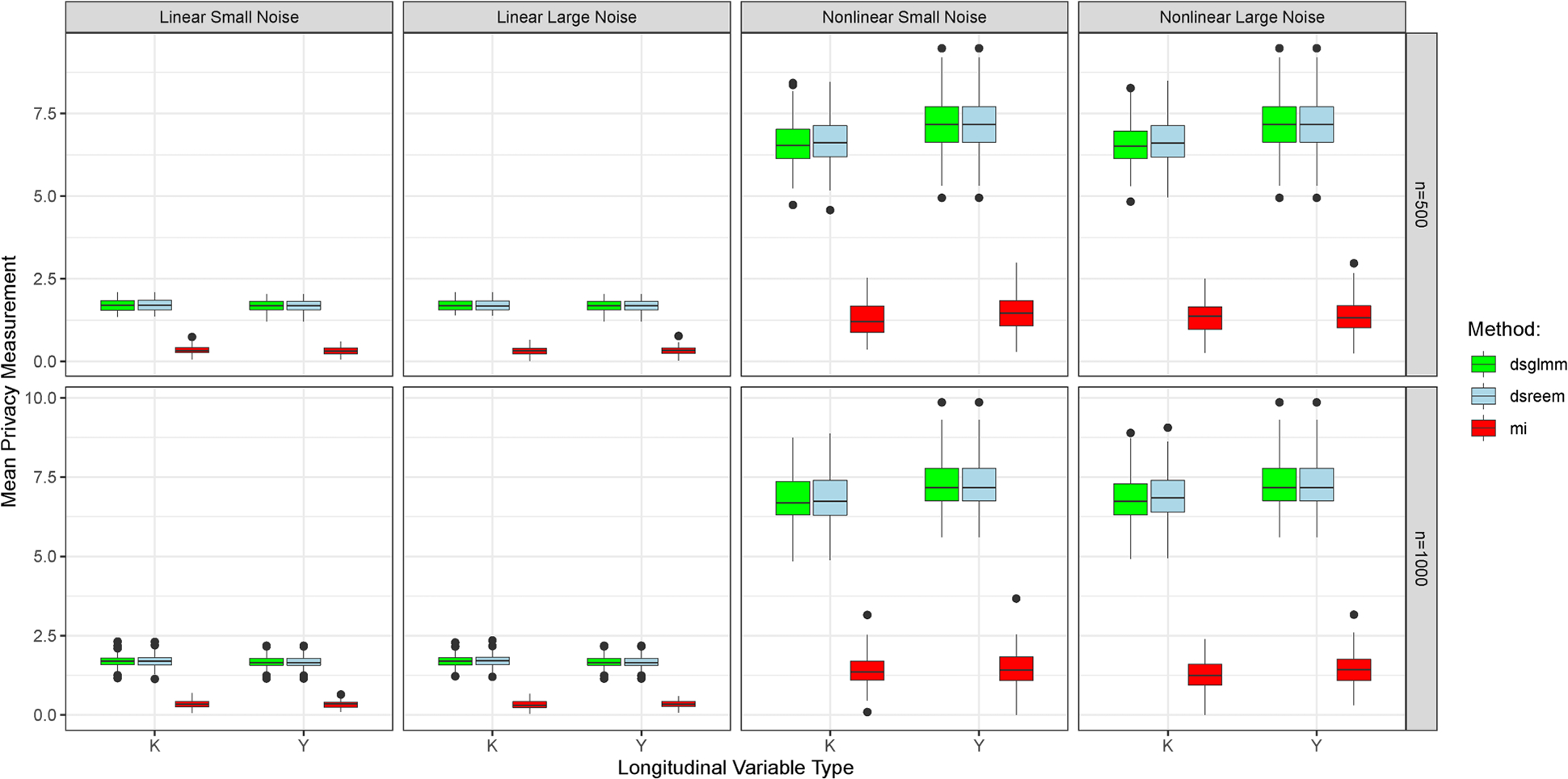
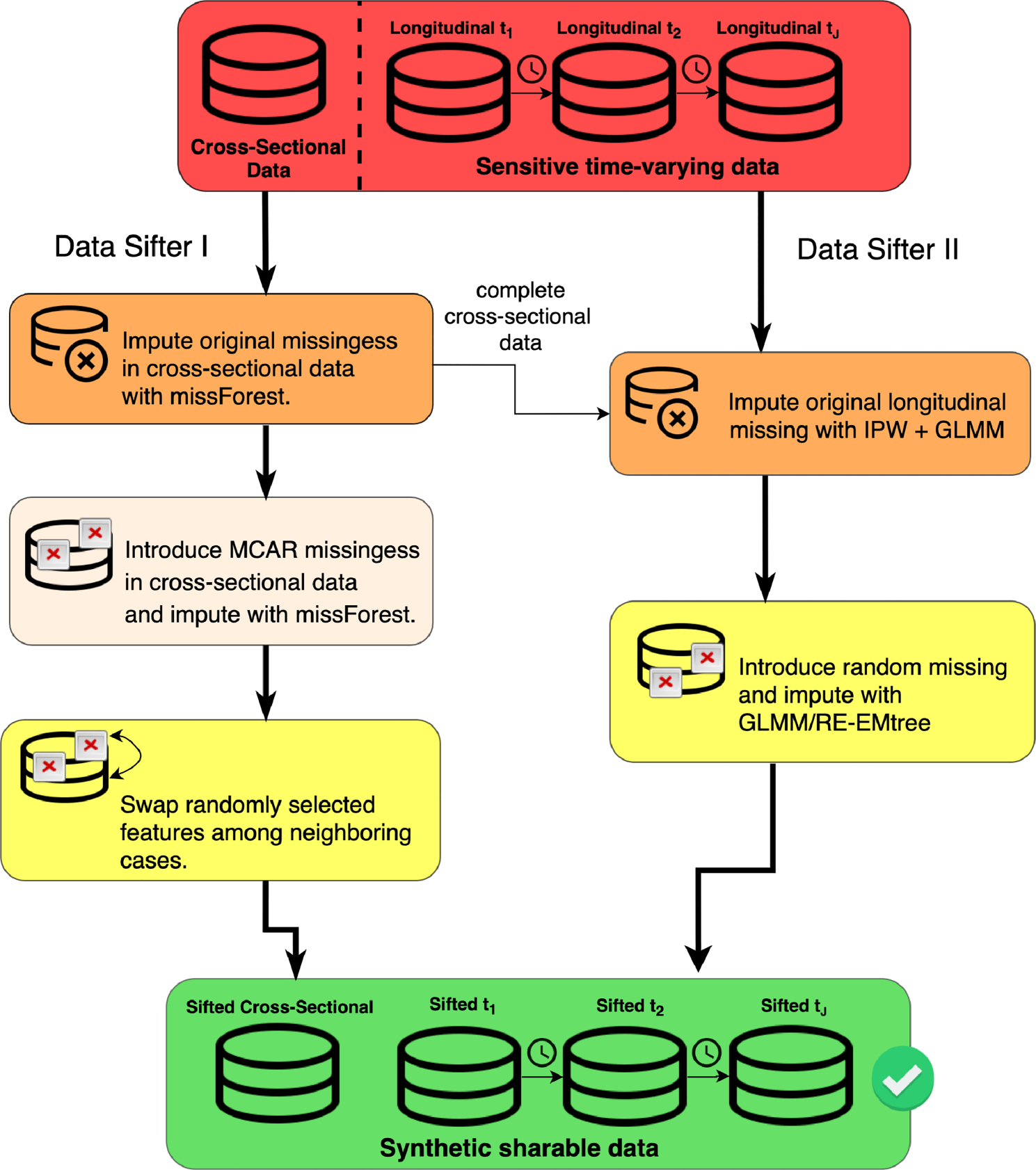
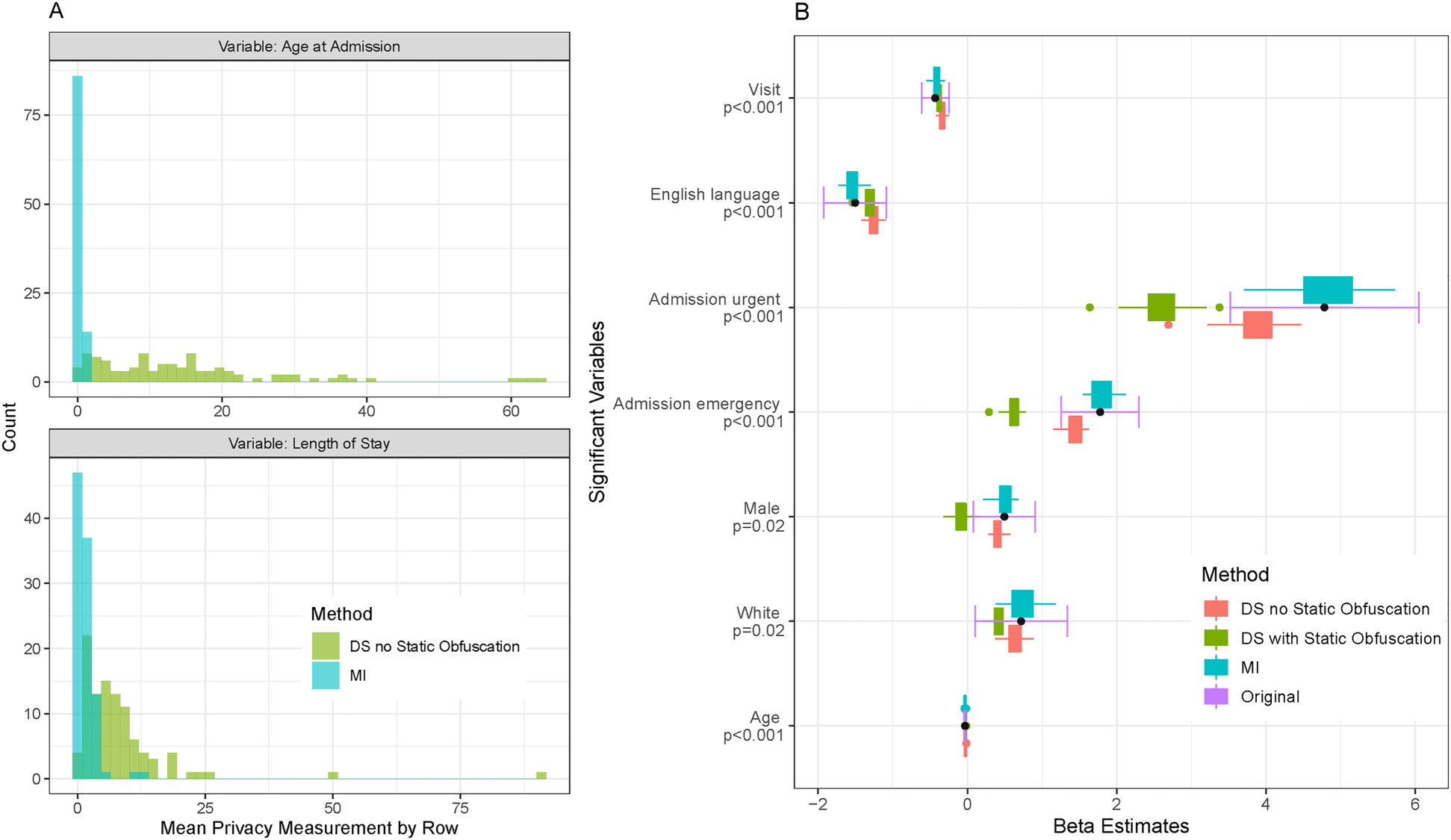
公众对利用汇总的敏感信息进行快速数据驱动科学调查的需求很大。然而,许多技术挑战和监管政策阻碍了高效的数据共享。在本研究中,我们介绍了一种部分合成数据生成技术,用于创建联合分布与原始(敏感)数据非常相似的匿名数据档案。具体来说,我们介绍了针对时变相关数据的 DataSifter 技术(DataSifter II),该技术依赖于使用广义线性混合模型和随机效应期望最大化树的基于模型的迭代估算。DataSifter II 可用于生成合成重复测量数据,以测试和验证新的分析技术。与多重估算方法相比,DataSifter II 在模拟和真实临床数据上的应用表明,新方法在保留混淆数据的分析价值(数据效用)的同时,还大大降低了再识别风险(数据隐私)。与多重估算方法相比,DataSifter II 在模拟数据中 20% 的人为缺失率上的表现至少降低了 80% 的泄露风险,同时对数据分析价值没有实质性影响。在单独的临床数据(重症监护医学信息库 III)验证中,从原始数据中得出的基于模型的统计推断与使用 DataSifter II 混淆(筛选)数据得出的类似分析推断一致。对于包含敏感信息的大型时变数据集,所提出的技术提供了一种自动化工具,可用于减轻数据共享的障碍,促进有效、先进和协作分析。
DataSifter II: Partially synthetic data sharing of sensitive information containing time-varying correlated observations.
There is a significant public demand for rapid data-driven scientific investigations using aggregated sensitive information. However, many technical challenges and regulatory policies hinder efficient data sharing. In this study, we describe a partially synthetic data generation technique for creating anonymized data archives whose joint distributions closely resemble those of the original (sensitive) data. Specifically, we introduce the DataSifter technique for time-varying correlated data (DataSifter II), which relies on an iterative model-based imputation using generalized linear mixed model and random effects-expectation maximization tree. DataSifter II can be used to generate synthetic repeated measures data for testing and validating new analytical techniques. Compared to the multiple imputation method, DataSifter II application on simulated and real clinical data demonstrates that the new method provides extensive reduction of re-identification risk (data privacy) while preserving the analytical value (data utility) in the obfuscated data. The performance of the DataSifter II on a simulation involving 20% artificially missingness in the data, shows at least 80% reduction of the disclosure risk, compared to the multiple imputation method, without a substantial impact on the data analytical value. In a separate clinical data (Medical Information Mart for Intensive Care III) validation, a model-based statistical inference drawn from the original data agrees with an analogous analytical inference obtained using the DataSifter II obfuscated (sifted) data. For large time-varying datasets containing sensitive information, the proposed technique provides an automated tool for alleviating the barriers of data sharing and facilitating effective, advanced, and collaborative analytics.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
