Shanshan Xie, Yan Zhang, Danjv Lv, Xu Chen, Jing Lu, Jiang Liu
{"title":"一种改进的基于特征子集的最大相关最小冗余方法。","authors":"Shanshan Xie, Yan Zhang, Danjv Lv, Xu Chen, Jing Lu, Jiang Liu","doi":"10.1007/s11227-022-04763-2","DOIUrl":null,"url":null,"abstract":"<p><p>Feature selection plays a very significant role for the success of pattern recognition and data mining. Based on the maximal relevance and minimal redundancy (mRMR) method, combined with feature subset, this paper proposes an improved maximal relevance and minimal redundancy (ImRMR) feature selection method based on feature subset. In ImRMR, the Pearson correlation coefficient and mutual information are first used to measure the relevance of a single feature to the sample category, and a factor is introduced to adjust the weights of the two measurement criteria. And an equal grouping method is exploited to generate candidate feature subsets according to the ranking features. Then, the relevance and redundancy of candidate feature subsets are calculated and the ordered sequence of these feature subsets is gained by incremental search method. Finally, the final optimal feature subset is obtained from these feature subsets by combining the sequence forward search method and the classification learning algorithm. Experiments are conducted on seven datasets. The results show that ImRMR can effectively remove irrelevant and redundant features, which can not only reduce the dimension of sample features and time of model training and prediction, but also improve the classification performance.</p>","PeriodicalId":50034,"journal":{"name":"Journal of Supercomputing","volume":"79 3","pages":"3157-3180"},"PeriodicalIF":2.7000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9424812/pdf/","citationCount":"4","resultStr":"{\"title\":\"A new improved maximal relevance and minimal redundancy method based on feature subset.\",\"authors\":\"Shanshan Xie, Yan Zhang, Danjv Lv, Xu Chen, Jing Lu, Jiang Liu\",\"doi\":\"10.1007/s11227-022-04763-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Feature selection plays a very significant role for the success of pattern recognition and data mining. Based on the maximal relevance and minimal redundancy (mRMR) method, combined with feature subset, this paper proposes an improved maximal relevance and minimal redundancy (ImRMR) feature selection method based on feature subset. In ImRMR, the Pearson correlation coefficient and mutual information are first used to measure the relevance of a single feature to the sample category, and a factor is introduced to adjust the weights of the two measurement criteria. And an equal grouping method is exploited to generate candidate feature subsets according to the ranking features. Then, the relevance and redundancy of candidate feature subsets are calculated and the ordered sequence of these feature subsets is gained by incremental search method. Finally, the final optimal feature subset is obtained from these feature subsets by combining the sequence forward search method and the classification learning algorithm. Experiments are conducted on seven datasets. The results show that ImRMR can effectively remove irrelevant and redundant features, which can not only reduce the dimension of sample features and time of model training and prediction, but also improve the classification performance.</p>\",\"PeriodicalId\":50034,\"journal\":{\"name\":\"Journal of Supercomputing\",\"volume\":\"79 3\",\"pages\":\"3157-3180\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9424812/pdf/\",\"citationCount\":\"4\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Supercomputing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11227-022-04763-2\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Supercomputing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11227-022-04763-2","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
A new improved maximal relevance and minimal redundancy method based on feature subset.
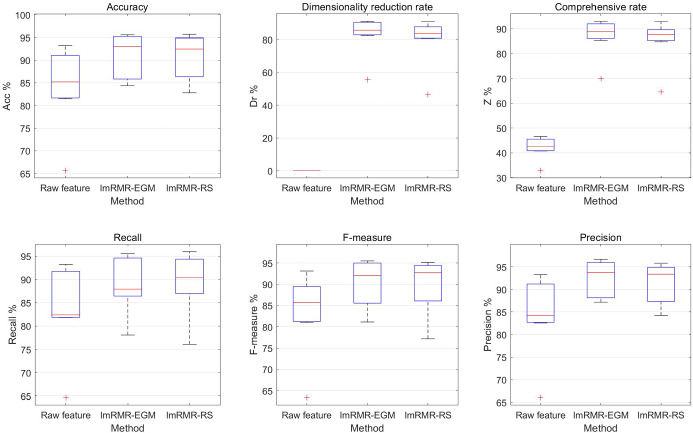
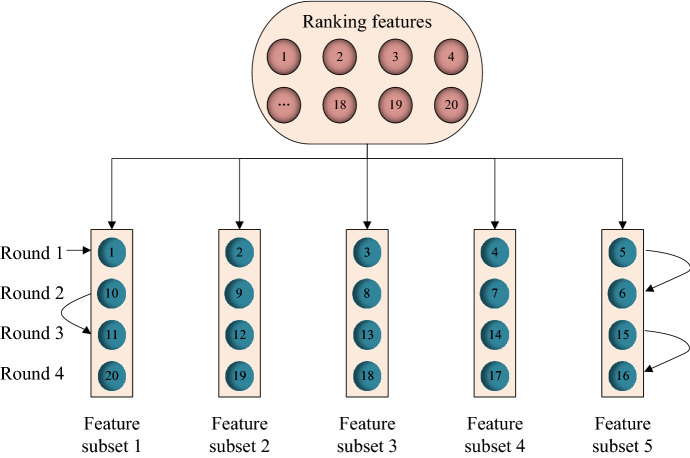
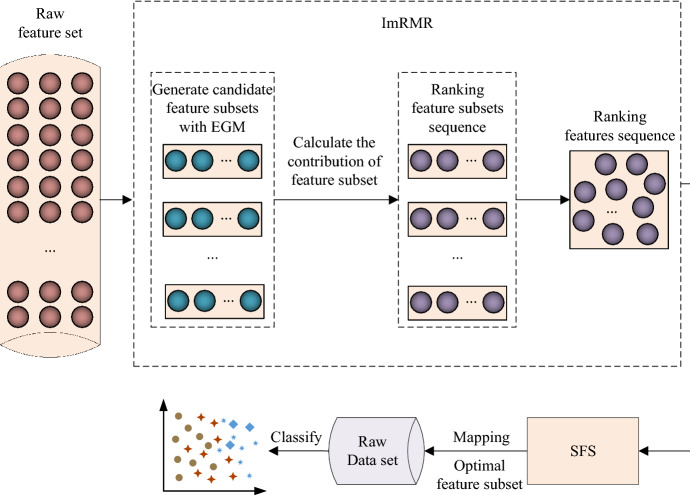
Feature selection plays a very significant role for the success of pattern recognition and data mining. Based on the maximal relevance and minimal redundancy (mRMR) method, combined with feature subset, this paper proposes an improved maximal relevance and minimal redundancy (ImRMR) feature selection method based on feature subset. In ImRMR, the Pearson correlation coefficient and mutual information are first used to measure the relevance of a single feature to the sample category, and a factor is introduced to adjust the weights of the two measurement criteria. And an equal grouping method is exploited to generate candidate feature subsets according to the ranking features. Then, the relevance and redundancy of candidate feature subsets are calculated and the ordered sequence of these feature subsets is gained by incremental search method. Finally, the final optimal feature subset is obtained from these feature subsets by combining the sequence forward search method and the classification learning algorithm. Experiments are conducted on seven datasets. The results show that ImRMR can effectively remove irrelevant and redundant features, which can not only reduce the dimension of sample features and time of model training and prediction, but also improve the classification performance.
期刊介绍:
The Journal of Supercomputing publishes papers on the technology, architecture and systems, algorithms, languages and programs, performance measures and methods, and applications of all aspects of Supercomputing. Tutorial and survey papers are intended for workers and students in the fields associated with and employing advanced computer systems. The journal also publishes letters to the editor, especially in areas relating to policy, succinct statements of paradoxes, intuitively puzzling results, partial results and real needs.
Published theoretical and practical papers are advanced, in-depth treatments describing new developments and new ideas. Each includes an introduction summarizing prior, directly pertinent work that is useful for the reader to understand, in order to appreciate the advances being described.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
