Seong-Joon Park, Sunghwan Kim, Jaeho Jeong, Albert No, Jong-Seon No, Hosung Park
{"title":"序列分析辅助变长读软信息解码降低基于dna的数据存储成本。","authors":"Seong-Joon Park, Sunghwan Kim, Jaeho Jeong, Albert No, Jong-Seon No, Hosung Park","doi":"10.1093/bioinformatics/btad548","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>DNA-based data storage is one of the most attractive research areas for future archival storage. However, it faces the problems of high writing and reading costs for practical use. There have been many efforts to resolve this problem, but existing schemes are not fully suitable for DNA-based data storage, and more cost reduction is needed.</p><p><strong>Results: </strong>We propose whole encoding and decoding procedures for DNA storage. The encoding procedure consists of a carefully designed single low-density parity-check code as an inter-oligo code, which corrects errors and dropouts efficiently. We apply new clustering and alignment methods that operate on variable-length reads to aid the decoding performance. We use edit distance and quality scores during the sequence analysis-aided decoding procedure, which can discard abnormal reads and utilize high-quality soft information. We store 548.83 KB of an image file in DNA oligos and achieve a writing cost reduction of 7.46% and a significant reading cost reduction of 26.57% and 19.41% compared with the two previous works.</p><p><strong>Availability and implementation: </strong>Data and codes for all the algorithms proposed in this study are available at: https://github.com/sjpark0905/DNA-LDPC-codes.</p>","PeriodicalId":8903,"journal":{"name":"Bioinformatics","volume":"39 9","pages":""},"PeriodicalIF":5.5000,"publicationDate":"2023-09-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10500082/pdf/","citationCount":"0","resultStr":"{\"title\":\"Reducing cost in DNA-based data storage by sequence analysis-aided soft information decoding of variable-length reads.\",\"authors\":\"Seong-Joon Park, Sunghwan Kim, Jaeho Jeong, Albert No, Jong-Seon No, Hosung Park\",\"doi\":\"10.1093/bioinformatics/btad548\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Motivation: </strong>DNA-based data storage is one of the most attractive research areas for future archival storage. However, it faces the problems of high writing and reading costs for practical use. There have been many efforts to resolve this problem, but existing schemes are not fully suitable for DNA-based data storage, and more cost reduction is needed.</p><p><strong>Results: </strong>We propose whole encoding and decoding procedures for DNA storage. The encoding procedure consists of a carefully designed single low-density parity-check code as an inter-oligo code, which corrects errors and dropouts efficiently. We apply new clustering and alignment methods that operate on variable-length reads to aid the decoding performance. We use edit distance and quality scores during the sequence analysis-aided decoding procedure, which can discard abnormal reads and utilize high-quality soft information. We store 548.83 KB of an image file in DNA oligos and achieve a writing cost reduction of 7.46% and a significant reading cost reduction of 26.57% and 19.41% compared with the two previous works.</p><p><strong>Availability and implementation: </strong>Data and codes for all the algorithms proposed in this study are available at: https://github.com/sjpark0905/DNA-LDPC-codes.</p>\",\"PeriodicalId\":8903,\"journal\":{\"name\":\"Bioinformatics\",\"volume\":\"39 9\",\"pages\":\"\"},\"PeriodicalIF\":5.5000,\"publicationDate\":\"2023-09-02\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10500082/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1093/bioinformatics/btad548\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOCHEMICAL RESEARCH METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bioinformatics/btad548","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
Reducing cost in DNA-based data storage by sequence analysis-aided soft information decoding of variable-length reads.
Motivation: DNA-based data storage is one of the most attractive research areas for future archival storage. However, it faces the problems of high writing and reading costs for practical use. There have been many efforts to resolve this problem, but existing schemes are not fully suitable for DNA-based data storage, and more cost reduction is needed.
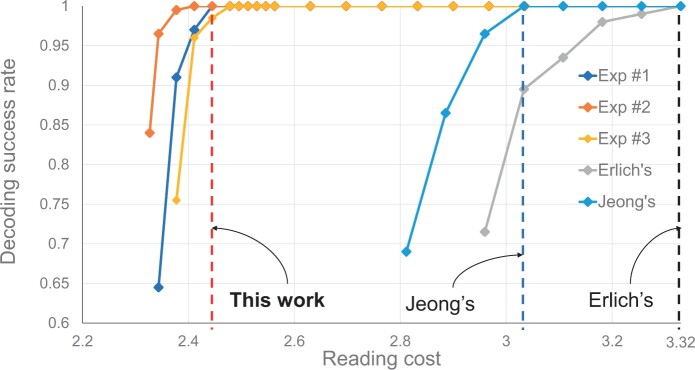
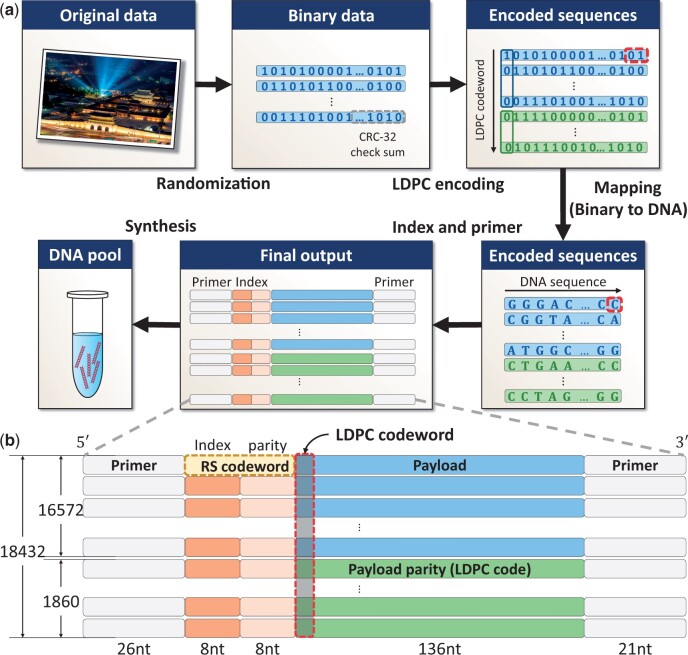
Results: We propose whole encoding and decoding procedures for DNA storage. The encoding procedure consists of a carefully designed single low-density parity-check code as an inter-oligo code, which corrects errors and dropouts efficiently. We apply new clustering and alignment methods that operate on variable-length reads to aid the decoding performance. We use edit distance and quality scores during the sequence analysis-aided decoding procedure, which can discard abnormal reads and utilize high-quality soft information. We store 548.83 KB of an image file in DNA oligos and achieve a writing cost reduction of 7.46% and a significant reading cost reduction of 26.57% and 19.41% compared with the two previous works.
Availability and implementation: Data and codes for all the algorithms proposed in this study are available at: https://github.com/sjpark0905/DNA-LDPC-codes.
期刊介绍:
The leading journal in its field, Bioinformatics publishes the highest quality scientific papers and review articles of interest to academic and industrial researchers. Its main focus is on new developments in genome bioinformatics and computational biology. Two distinct sections within the journal - Discovery Notes and Application Notes- focus on shorter papers; the former reporting biologically interesting discoveries using computational methods, the latter exploring the applications used for experiments.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
