{"title":"基于跨尺度融合注意力机制网络对街景进行语义分割。","authors":"Xin Ye, Lang Gao, Jichen Chen, Mingyue Lei","doi":"10.3389/fnbot.2023.1204418","DOIUrl":null,"url":null,"abstract":"<p><p>Semantic segmentation, which is a fundamental task in computer vision. Every pixel will have a specific semantic class assigned to it through semantic segmentation methods. Embedded systems and mobile devices are difficult to deploy high-accuracy segmentation algorithms. Despite the rapid development of semantic segmentation, the balance between speed and accuracy must be improved. As a solution to the above problems, we created a cross-scale fusion attention mechanism network called CFANet, which fuses feature maps from different scales. We first design a novel efficient residual module (ERM), which applies both dilation convolution and factorized convolution. Our CFANet is mainly constructed from ERM. Subsequently, we designed a new multi-branch channel attention mechanism (MCAM) to refine the feature maps at different levels. Experiment results show that CFANet achieved 70.6% mean intersection over union (mIoU) and 67.7% mIoU on Cityscapes and CamVid datasets, respectively, with inference speeds of 118 FPS and 105 FPS on NVIDIA RTX2080Ti GPU cards with 0.84M parameters.</p>","PeriodicalId":12628,"journal":{"name":"Frontiers in Neurorobotics","volume":"17 ","pages":"1204418"},"PeriodicalIF":2.8000,"publicationDate":"2023-08-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10501793/pdf/","citationCount":"0","resultStr":"{\"title\":\"Based on cross-scale fusion attention mechanism network for semantic segmentation for street scenes.\",\"authors\":\"Xin Ye, Lang Gao, Jichen Chen, Mingyue Lei\",\"doi\":\"10.3389/fnbot.2023.1204418\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Semantic segmentation, which is a fundamental task in computer vision. Every pixel will have a specific semantic class assigned to it through semantic segmentation methods. Embedded systems and mobile devices are difficult to deploy high-accuracy segmentation algorithms. Despite the rapid development of semantic segmentation, the balance between speed and accuracy must be improved. As a solution to the above problems, we created a cross-scale fusion attention mechanism network called CFANet, which fuses feature maps from different scales. We first design a novel efficient residual module (ERM), which applies both dilation convolution and factorized convolution. Our CFANet is mainly constructed from ERM. Subsequently, we designed a new multi-branch channel attention mechanism (MCAM) to refine the feature maps at different levels. Experiment results show that CFANet achieved 70.6% mean intersection over union (mIoU) and 67.7% mIoU on Cityscapes and CamVid datasets, respectively, with inference speeds of 118 FPS and 105 FPS on NVIDIA RTX2080Ti GPU cards with 0.84M parameters.</p>\",\"PeriodicalId\":12628,\"journal\":{\"name\":\"Frontiers in Neurorobotics\",\"volume\":\"17 \",\"pages\":\"1204418\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2023-08-31\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10501793/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in Neurorobotics\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.3389/fnbot.2023.1204418\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Neurorobotics","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.3389/fnbot.2023.1204418","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Based on cross-scale fusion attention mechanism network for semantic segmentation for street scenes.
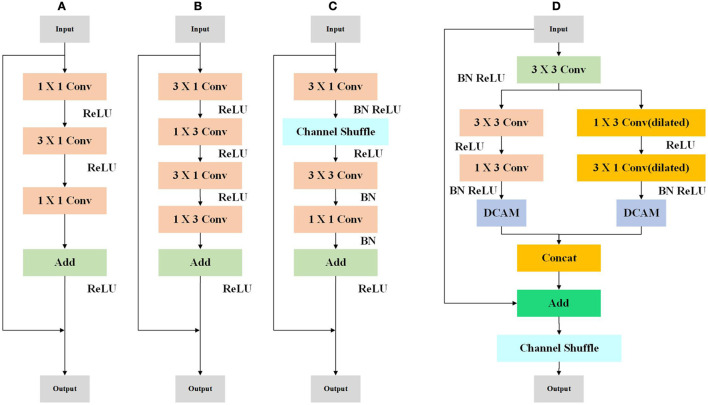
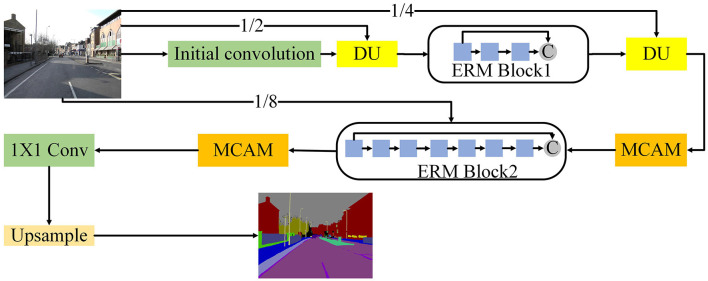
Semantic segmentation, which is a fundamental task in computer vision. Every pixel will have a specific semantic class assigned to it through semantic segmentation methods. Embedded systems and mobile devices are difficult to deploy high-accuracy segmentation algorithms. Despite the rapid development of semantic segmentation, the balance between speed and accuracy must be improved. As a solution to the above problems, we created a cross-scale fusion attention mechanism network called CFANet, which fuses feature maps from different scales. We first design a novel efficient residual module (ERM), which applies both dilation convolution and factorized convolution. Our CFANet is mainly constructed from ERM. Subsequently, we designed a new multi-branch channel attention mechanism (MCAM) to refine the feature maps at different levels. Experiment results show that CFANet achieved 70.6% mean intersection over union (mIoU) and 67.7% mIoU on Cityscapes and CamVid datasets, respectively, with inference speeds of 118 FPS and 105 FPS on NVIDIA RTX2080Ti GPU cards with 0.84M parameters.
期刊介绍:
Frontiers in Neurorobotics publishes rigorously peer-reviewed research in the science and technology of embodied autonomous neural systems. Specialty Chief Editors Alois C. Knoll and Florian Röhrbein at the Technische Universität München are supported by an outstanding Editorial Board of international experts. This multidisciplinary open-access journal is at the forefront of disseminating and communicating scientific knowledge and impactful discoveries to researchers, academics and the public worldwide.
Neural systems include brain-inspired algorithms (e.g. connectionist networks), computational models of biological neural networks (e.g. artificial spiking neural nets, large-scale simulations of neural microcircuits) and actual biological systems (e.g. in vivo and in vitro neural nets). The focus of the journal is the embodiment of such neural systems in artificial software and hardware devices, machines, robots or any other form of physical actuation. This also includes prosthetic devices, brain machine interfaces, wearable systems, micro-machines, furniture, home appliances, as well as systems for managing micro and macro infrastructures. Frontiers in Neurorobotics also aims to publish radically new tools and methods to study plasticity and development of autonomous self-learning systems that are capable of acquiring knowledge in an open-ended manner. Models complemented with experimental studies revealing self-organizing principles of embodied neural systems are welcome. Our journal also publishes on the micro and macro engineering and mechatronics of robotic devices driven by neural systems, as well as studies on the impact that such systems will have on our daily life.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
