{"title":"持续集成测试中机器学习测试用例优先级的比较研究","authors":"Dusica Marijan","doi":"10.1007/s11219-023-09646-0","DOIUrl":null,"url":null,"abstract":"There is a growing body of research indicating the potential of machine learning to tackle complex software testing challenges. One such challenge pertains to continuous integration testing, which is highly time-constrained, and generates a large amount of data coming from iterative code commits and test runs. In such a setting, we can use plentiful test data for training machine learning predictors to identify test cases able to speed up the detection of regression bugs introduced during code integration. However, different machine learning models can have different fault prediction performance depending on the context and the parameters of continuous integration testing, for example, variable time budget available for continuous integration cycles, or the size of test execution history used for learning to prioritize failing test cases. Existing studies on test case prioritization rarely study both of these factors, which are essential for the continuous integration practice. In this study, we perform a comprehensive comparison of the fault prediction performance of machine learning approaches that have shown the best performance on test case prioritization tasks in the literature. We evaluate the accuracy of the classifiers in predicting fault-detecting tests for different values of the continuous integration time budget and with different lengths of test history used for training the classifiers. In evaluation, we use real-world and augmented industrial datasets from a continuous integration practice. The results show that different machine learning models have different performance for different size of test history used for model training and for different time budgets available for test case execution. Our results imply that machine learning approaches for test prioritization in continuous integration testing should be carefully configured to achieve optimal performance.","PeriodicalId":21827,"journal":{"name":"Software Quality Journal","volume":"10 1","pages":"0"},"PeriodicalIF":2.3000,"publicationDate":"2023-07-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"2","resultStr":"{\"title\":\"Comparative study of machine learning test case prioritization for continuous integration testing\",\"authors\":\"Dusica Marijan\",\"doi\":\"10.1007/s11219-023-09646-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"There is a growing body of research indicating the potential of machine learning to tackle complex software testing challenges. One such challenge pertains to continuous integration testing, which is highly time-constrained, and generates a large amount of data coming from iterative code commits and test runs. In such a setting, we can use plentiful test data for training machine learning predictors to identify test cases able to speed up the detection of regression bugs introduced during code integration. However, different machine learning models can have different fault prediction performance depending on the context and the parameters of continuous integration testing, for example, variable time budget available for continuous integration cycles, or the size of test execution history used for learning to prioritize failing test cases. Existing studies on test case prioritization rarely study both of these factors, which are essential for the continuous integration practice. In this study, we perform a comprehensive comparison of the fault prediction performance of machine learning approaches that have shown the best performance on test case prioritization tasks in the literature. We evaluate the accuracy of the classifiers in predicting fault-detecting tests for different values of the continuous integration time budget and with different lengths of test history used for training the classifiers. In evaluation, we use real-world and augmented industrial datasets from a continuous integration practice. The results show that different machine learning models have different performance for different size of test history used for model training and for different time budgets available for test case execution. Our results imply that machine learning approaches for test prioritization in continuous integration testing should be carefully configured to achieve optimal performance.\",\"PeriodicalId\":21827,\"journal\":{\"name\":\"Software Quality Journal\",\"volume\":\"10 1\",\"pages\":\"0\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2023-07-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Software Quality Journal\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s11219-023-09646-0\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Software Quality Journal","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s11219-023-09646-0","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Comparative study of machine learning test case prioritization for continuous integration testing
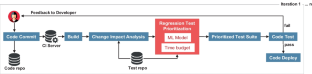
There is a growing body of research indicating the potential of machine learning to tackle complex software testing challenges. One such challenge pertains to continuous integration testing, which is highly time-constrained, and generates a large amount of data coming from iterative code commits and test runs. In such a setting, we can use plentiful test data for training machine learning predictors to identify test cases able to speed up the detection of regression bugs introduced during code integration. However, different machine learning models can have different fault prediction performance depending on the context and the parameters of continuous integration testing, for example, variable time budget available for continuous integration cycles, or the size of test execution history used for learning to prioritize failing test cases. Existing studies on test case prioritization rarely study both of these factors, which are essential for the continuous integration practice. In this study, we perform a comprehensive comparison of the fault prediction performance of machine learning approaches that have shown the best performance on test case prioritization tasks in the literature. We evaluate the accuracy of the classifiers in predicting fault-detecting tests for different values of the continuous integration time budget and with different lengths of test history used for training the classifiers. In evaluation, we use real-world and augmented industrial datasets from a continuous integration practice. The results show that different machine learning models have different performance for different size of test history used for model training and for different time budgets available for test case execution. Our results imply that machine learning approaches for test prioritization in continuous integration testing should be carefully configured to achieve optimal performance.
期刊介绍:
The aims of the Software Quality Journal are:
(1) To promote awareness of the crucial role of quality management in the effective construction of the software systems developed, used, and/or maintained by organizations in pursuit of their business objectives.
(2) To provide a forum of the exchange of experiences and information on software quality management and the methods, tools and products used to measure and achieve it.
(3) To provide a vehicle for the publication of academic papers related to all aspects of software quality.
The Journal addresses all aspects of software quality from both a practical and an academic viewpoint. It invites contributions from practitioners and academics, as well as national and international policy and standard making bodies, and sets out to be the definitive international reference source for such information.
The Journal will accept research, technique, case study, survey and tutorial submissions that address quality-related issues including, but not limited to: internal and external quality standards, management of quality within organizations, technical aspects of quality, quality aspects for product vendors, software measurement and metrics, software testing and other quality assurance techniques, total quality management and cultural aspects. Other technical issues with regard to software quality, including: data management, formal methods, safety critical applications, and CASE.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
