{"title":"基于骨骼动作识别的多时标聚合细化图卷积网络","authors":"Xuanfeng Li, Jian Lu, Jian Zhou, Wei Liu, Kaibing Zhang","doi":"10.1002/cav.2221","DOIUrl":null,"url":null,"abstract":"<p>Skeleton-based human action recognition is gaining significant attention and finding widespread application in various fields, such as virtual reality and human-computer interaction systems. Recent studies have highlighted the effectiveness of graph convolutional network (GCN) based methods in this task, leading to a remarkable improvement in prediction accuracy. However, most GCN-based methods overlook the varying contributions of self, centripetal and centrifugal subsets. Besides, only a single-scale temporal feature is adopted, and the multi-temporal scale information is ignored. To this end, firstly, in order to differentiate the importance of different skeleton subsets, we develop a refinement graph convolution, which can adaptively learn a weight for each subset feature. Secondly, a multi-temporal scale aggregation module is proposed to extract more discriminative temporal dynamic information. Furthermore, a multi-temporal scale aggregation refinement graph convolutional network (MTSA-RGCN) is proposed, and four-stream structure is also adopted in this paper, which can comprehensively model complementary features and eventually achieves a significant performance boost. In the empirical experiments, the performance of our approach has been greatly improved on both NTU-RGB+D 60 and NTU-RGB+D 120 datasets, compared to other state-of-the-art methods.</p>","PeriodicalId":50645,"journal":{"name":"Computer Animation and Virtual Worlds","volume":"35 1","pages":""},"PeriodicalIF":3.4000,"publicationDate":"2023-09-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Multi-temporal scale aggregation refinement graph convolutional network for skeleton-based action recognition\",\"authors\":\"Xuanfeng Li, Jian Lu, Jian Zhou, Wei Liu, Kaibing Zhang\",\"doi\":\"10.1002/cav.2221\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Skeleton-based human action recognition is gaining significant attention and finding widespread application in various fields, such as virtual reality and human-computer interaction systems. Recent studies have highlighted the effectiveness of graph convolutional network (GCN) based methods in this task, leading to a remarkable improvement in prediction accuracy. However, most GCN-based methods overlook the varying contributions of self, centripetal and centrifugal subsets. Besides, only a single-scale temporal feature is adopted, and the multi-temporal scale information is ignored. To this end, firstly, in order to differentiate the importance of different skeleton subsets, we develop a refinement graph convolution, which can adaptively learn a weight for each subset feature. Secondly, a multi-temporal scale aggregation module is proposed to extract more discriminative temporal dynamic information. Furthermore, a multi-temporal scale aggregation refinement graph convolutional network (MTSA-RGCN) is proposed, and four-stream structure is also adopted in this paper, which can comprehensively model complementary features and eventually achieves a significant performance boost. In the empirical experiments, the performance of our approach has been greatly improved on both NTU-RGB+D 60 and NTU-RGB+D 120 datasets, compared to other state-of-the-art methods.</p>\",\"PeriodicalId\":50645,\"journal\":{\"name\":\"Computer Animation and Virtual Worlds\",\"volume\":\"35 1\",\"pages\":\"\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2023-09-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computer Animation and Virtual Worlds\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/cav.2221\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Animation and Virtual Worlds","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/cav.2221","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
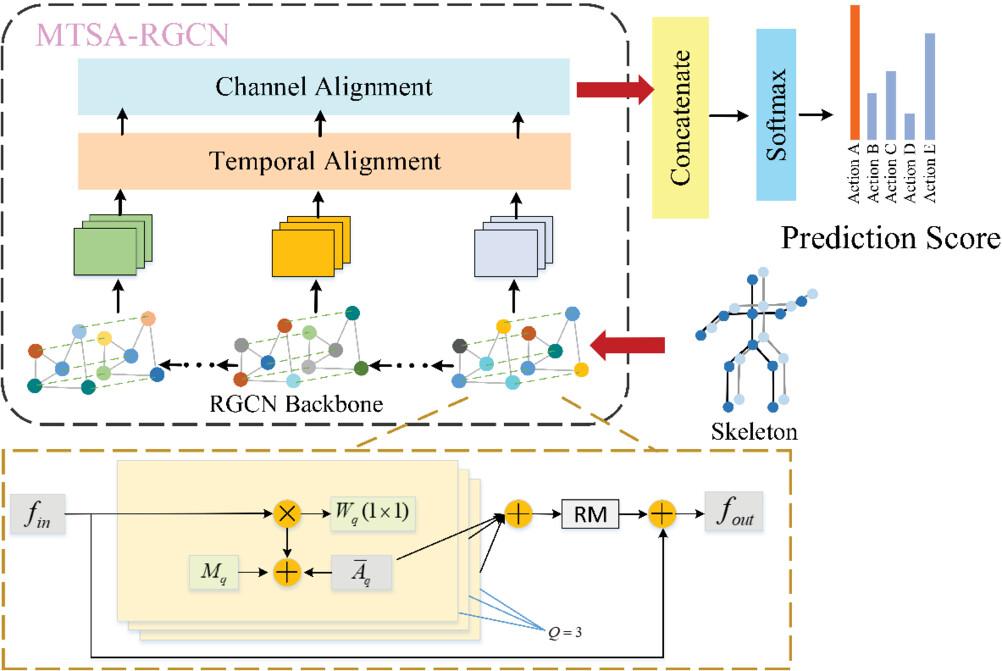
Skeleton-based human action recognition is gaining significant attention and finding widespread application in various fields, such as virtual reality and human-computer interaction systems. Recent studies have highlighted the effectiveness of graph convolutional network (GCN) based methods in this task, leading to a remarkable improvement in prediction accuracy. However, most GCN-based methods overlook the varying contributions of self, centripetal and centrifugal subsets. Besides, only a single-scale temporal feature is adopted, and the multi-temporal scale information is ignored. To this end, firstly, in order to differentiate the importance of different skeleton subsets, we develop a refinement graph convolution, which can adaptively learn a weight for each subset feature. Secondly, a multi-temporal scale aggregation module is proposed to extract more discriminative temporal dynamic information. Furthermore, a multi-temporal scale aggregation refinement graph convolutional network (MTSA-RGCN) is proposed, and four-stream structure is also adopted in this paper, which can comprehensively model complementary features and eventually achieves a significant performance boost. In the empirical experiments, the performance of our approach has been greatly improved on both NTU-RGB+D 60 and NTU-RGB+D 120 datasets, compared to other state-of-the-art methods.
期刊介绍:
With the advent of very powerful PCs and high-end graphics cards, there has been an incredible development in Virtual Worlds, real-time computer animation and simulation, games. But at the same time, new and cheaper Virtual Reality devices have appeared allowing an interaction with these real-time Virtual Worlds and even with real worlds through Augmented Reality. Three-dimensional characters, especially Virtual Humans are now of an exceptional quality, which allows to use them in the movie industry. But this is only a beginning, as with the development of Artificial Intelligence and Agent technology, these characters will become more and more autonomous and even intelligent. They will inhabit the Virtual Worlds in a Virtual Life together with animals and plants.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
