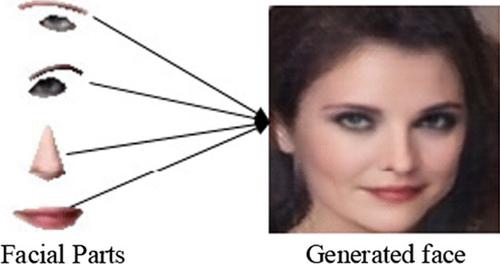
{"title":"从面部部位合成人脸图像","authors":"Qiushi Sun, Jingtao Guo, Yi Liu","doi":"10.1186/s13640-022-00585-7","DOIUrl":null,"url":null,"abstract":"<p>Recently, inspired by the growing power of deep convolutional neural networks (CNNs) and generative adversarial networks (GANs), facial image editing has received increasing attention and has produced a series of wide-ranging applications. In this paper, we propose a new and effective approach to a challenging task: synthesizing face images based on key facial parts. The proposed approach is a novel deep generative network that can automatically align facial parts with the precise positions in a face image and then output an entire facial image conditioned on the well-aligned parts. Specifically, three loss functions are introduced in this approach, which are the key to making the synthesized realistic facial image: a reconstruction loss to generate image content in an unknown region, a perceptual loss to enhance the network's ability to model high-level semantic structures and an adversarial loss to ensure that the synthesized images are visually realistic. In this approach, the three components cooperate well to form an effective framework for parts-based high-quality facial image synthesis. Finally, extensive experiments demonstrate the superior performance of this method to existing solutions.</p>","PeriodicalId":49322,"journal":{"name":"Eurasip Journal on Image and Video Processing","volume":"27 1","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2022-05-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"1","resultStr":"{\"title\":\"Face image synthesis from facial parts\",\"authors\":\"Qiushi Sun, Jingtao Guo, Yi Liu\",\"doi\":\"10.1186/s13640-022-00585-7\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Recently, inspired by the growing power of deep convolutional neural networks (CNNs) and generative adversarial networks (GANs), facial image editing has received increasing attention and has produced a series of wide-ranging applications. In this paper, we propose a new and effective approach to a challenging task: synthesizing face images based on key facial parts. The proposed approach is a novel deep generative network that can automatically align facial parts with the precise positions in a face image and then output an entire facial image conditioned on the well-aligned parts. Specifically, three loss functions are introduced in this approach, which are the key to making the synthesized realistic facial image: a reconstruction loss to generate image content in an unknown region, a perceptual loss to enhance the network's ability to model high-level semantic structures and an adversarial loss to ensure that the synthesized images are visually realistic. In this approach, the three components cooperate well to form an effective framework for parts-based high-quality facial image synthesis. Finally, extensive experiments demonstrate the superior performance of this method to existing solutions.</p>\",\"PeriodicalId\":49322,\"journal\":{\"name\":\"Eurasip Journal on Image and Video Processing\",\"volume\":\"27 1\",\"pages\":\"\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2022-05-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Eurasip Journal on Image and Video Processing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1186/s13640-022-00585-7\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Eurasip Journal on Image and Video Processing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s13640-022-00585-7","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Recently, inspired by the growing power of deep convolutional neural networks (CNNs) and generative adversarial networks (GANs), facial image editing has received increasing attention and has produced a series of wide-ranging applications. In this paper, we propose a new and effective approach to a challenging task: synthesizing face images based on key facial parts. The proposed approach is a novel deep generative network that can automatically align facial parts with the precise positions in a face image and then output an entire facial image conditioned on the well-aligned parts. Specifically, three loss functions are introduced in this approach, which are the key to making the synthesized realistic facial image: a reconstruction loss to generate image content in an unknown region, a perceptual loss to enhance the network's ability to model high-level semantic structures and an adversarial loss to ensure that the synthesized images are visually realistic. In this approach, the three components cooperate well to form an effective framework for parts-based high-quality facial image synthesis. Finally, extensive experiments demonstrate the superior performance of this method to existing solutions.
期刊介绍:
EURASIP Journal on Image and Video Processing is intended for researchers from both academia and industry, who are active in the multidisciplinary field of image and video processing. The scope of the journal covers all theoretical and practical aspects of the domain, from basic research to development of application.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
