{"title":"面向特征优化的可扩展解耦图神经网络","authors":"Ningyi Liao, Dingheng Mo, Siqiang Luo, Xiang Li, Pengcheng Yin","doi":"10.1007/s00778-023-00829-6","DOIUrl":null,"url":null,"abstract":"<p>Recent advances in data processing have stimulated the demand for learning graphs of very large scales. Graph neural networks (GNNs), being an emerging and powerful approach in solving graph learning tasks, are known to be difficult to scale up. Most scalable models apply node-based techniques in simplifying the expensive graph message-passing propagation procedure of GNNs. However, we find such acceleration insufficient when applied to million- or even billion-scale graphs. In this work, we propose <span>SCARA</span>, a scalable GNN with feature-oriented optimization for graph computation. <span>SCARA</span> efficiently computes graph embedding from the dimension of node features, and further selects and reuses feature computation results to reduce overhead. Theoretical analysis indicates that our model achieves sub-linear time complexity with a guaranteed precision in propagation process as well as GNN training and inference. We conduct extensive experiments on various datasets to evaluate the efficacy and efficiency of <span>SCARA</span>. Performance comparison with baselines shows that <span>SCARA</span> can reach up to <span>\\(800\\times \\)</span> graph propagation acceleration than current state-of-the-art methods with fast convergence and comparable accuracy. Most notably, it is efficient to process precomputation on the largest available billion-scale GNN dataset Papers100M (111 M nodes, 1.6 B edges) in 13 s.</p>","PeriodicalId":501532,"journal":{"name":"The VLDB Journal","volume":"4 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2023-12-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Scalable decoupling graph neural network with feature-oriented optimization\",\"authors\":\"Ningyi Liao, Dingheng Mo, Siqiang Luo, Xiang Li, Pengcheng Yin\",\"doi\":\"10.1007/s00778-023-00829-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Recent advances in data processing have stimulated the demand for learning graphs of very large scales. Graph neural networks (GNNs), being an emerging and powerful approach in solving graph learning tasks, are known to be difficult to scale up. Most scalable models apply node-based techniques in simplifying the expensive graph message-passing propagation procedure of GNNs. However, we find such acceleration insufficient when applied to million- or even billion-scale graphs. In this work, we propose <span>SCARA</span>, a scalable GNN with feature-oriented optimization for graph computation. <span>SCARA</span> efficiently computes graph embedding from the dimension of node features, and further selects and reuses feature computation results to reduce overhead. Theoretical analysis indicates that our model achieves sub-linear time complexity with a guaranteed precision in propagation process as well as GNN training and inference. We conduct extensive experiments on various datasets to evaluate the efficacy and efficiency of <span>SCARA</span>. Performance comparison with baselines shows that <span>SCARA</span> can reach up to <span>\\\\(800\\\\times \\\\)</span> graph propagation acceleration than current state-of-the-art methods with fast convergence and comparable accuracy. Most notably, it is efficient to process precomputation on the largest available billion-scale GNN dataset Papers100M (111 M nodes, 1.6 B edges) in 13 s.</p>\",\"PeriodicalId\":501532,\"journal\":{\"name\":\"The VLDB Journal\",\"volume\":\"4 1\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-12-27\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"The VLDB Journal\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s00778-023-00829-6\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"The VLDB Journal","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s00778-023-00829-6","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
数据处理领域的最新进展刺激了对超大规模图形学习的需求。图神经网络(GNN)是解决图学习任务的一种新兴而强大的方法,但众所周知难以扩展。大多数可扩展模型都采用了基于节点的技术,以简化图神经网络昂贵的图消息传递传播过程。然而,我们发现这种加速在应用于百万甚至十亿规模的图时并不充分。在这项工作中,我们提出了 SCARA,这是一种可扩展的 GNN,具有面向特征的图计算优化功能。SCARA 从节点特征维度高效计算图嵌入,并进一步选择和重用特征计算结果,以减少开销。理论分析表明,我们的模型实现了亚线性时间复杂度,并保证了传播过程以及 GNN 训练和推理的精度。我们在各种数据集上进行了大量实验,以评估 SCARA 的功效和效率。与基线方法的性能比较表明,与当前最先进的方法相比,SCARA 的图传播加速度可达 800 倍,而且收敛速度快,精度相当。最值得注意的是,它能在 13 秒内高效处理现有最大的十亿规模 GNN 数据集 Papers100M(111 M 节点,1.6 B 边)的预计算。
Scalable decoupling graph neural network with feature-oriented optimization
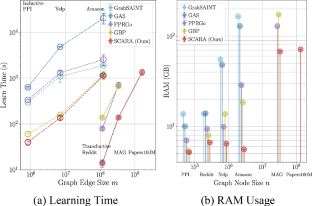
Recent advances in data processing have stimulated the demand for learning graphs of very large scales. Graph neural networks (GNNs), being an emerging and powerful approach in solving graph learning tasks, are known to be difficult to scale up. Most scalable models apply node-based techniques in simplifying the expensive graph message-passing propagation procedure of GNNs. However, we find such acceleration insufficient when applied to million- or even billion-scale graphs. In this work, we propose SCARA, a scalable GNN with feature-oriented optimization for graph computation. SCARA efficiently computes graph embedding from the dimension of node features, and further selects and reuses feature computation results to reduce overhead. Theoretical analysis indicates that our model achieves sub-linear time complexity with a guaranteed precision in propagation process as well as GNN training and inference. We conduct extensive experiments on various datasets to evaluate the efficacy and efficiency of SCARA. Performance comparison with baselines shows that SCARA can reach up to \(800\times \) graph propagation acceleration than current state-of-the-art methods with fast convergence and comparable accuracy. Most notably, it is efficient to process precomputation on the largest available billion-scale GNN dataset Papers100M (111 M nodes, 1.6 B edges) in 13 s.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
