David Bonet, May Levin, Daniel Mas Montserrat, Alexander G Ioannidis
{"title":"在代表性不足的人群中改进表型预测的机器学习策略。","authors":"David Bonet, May Levin, Daniel Mas Montserrat, Alexander G Ioannidis","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>Precision medicine models often perform better for populations of European ancestry due to the over-representation of this group in the genomic datasets and large-scale biobanks from which the models are constructed. As a result, prediction models may misrepresent or provide less accurate treatment recommendations for underrepresented populations, contributing to health disparities. This study introduces an adaptable machine learning toolkit that integrates multiple existing methodologies and novel techniques to enhance the prediction accuracy for underrepresented populations in genomic datasets. By leveraging machine learning techniques, including gradient boosting and automated methods, coupled with novel population-conditional re-sampling techniques, our method significantly improves the phenotypic prediction from single nucleotide polymorphism (SNP) data for diverse populations. We evaluate our approach using the UK Biobank, which is composed primarily of British individuals with European ancestry, and a minority representation of groups with Asian and African ancestry. Performance metrics demonstrate substantial improvements in phenotype prediction for underrepresented groups, achieving prediction accuracy comparable to that of the majority group. This approach represents a significant step towards improving prediction accuracy amidst current dataset diversity challenges. By integrating a tailored pipeline, our approach fosters more equitable validity and utility of statistical genetics methods, paving the way for more inclusive models and outcomes.</p>","PeriodicalId":34954,"journal":{"name":"Pacific Symposium on Biocomputing. Pacific Symposium on Biocomputing","volume":"29 ","pages":"404-418"},"PeriodicalIF":0.0000,"publicationDate":"2024-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10799683/pdf/","citationCount":"0","resultStr":"{\"title\":\"Machine Learning Strategies for Improved Phenotype Prediction in Underrepresented Populations.\",\"authors\":\"David Bonet, May Levin, Daniel Mas Montserrat, Alexander G Ioannidis\",\"doi\":\"\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Precision medicine models often perform better for populations of European ancestry due to the over-representation of this group in the genomic datasets and large-scale biobanks from which the models are constructed. As a result, prediction models may misrepresent or provide less accurate treatment recommendations for underrepresented populations, contributing to health disparities. This study introduces an adaptable machine learning toolkit that integrates multiple existing methodologies and novel techniques to enhance the prediction accuracy for underrepresented populations in genomic datasets. By leveraging machine learning techniques, including gradient boosting and automated methods, coupled with novel population-conditional re-sampling techniques, our method significantly improves the phenotypic prediction from single nucleotide polymorphism (SNP) data for diverse populations. We evaluate our approach using the UK Biobank, which is composed primarily of British individuals with European ancestry, and a minority representation of groups with Asian and African ancestry. Performance metrics demonstrate substantial improvements in phenotype prediction for underrepresented groups, achieving prediction accuracy comparable to that of the majority group. This approach represents a significant step towards improving prediction accuracy amidst current dataset diversity challenges. By integrating a tailored pipeline, our approach fosters more equitable validity and utility of statistical genetics methods, paving the way for more inclusive models and outcomes.</p>\",\"PeriodicalId\":34954,\"journal\":{\"name\":\"Pacific Symposium on Biocomputing. Pacific Symposium on Biocomputing\",\"volume\":\"29 \",\"pages\":\"404-418\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10799683/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Pacific Symposium on Biocomputing. Pacific Symposium on Biocomputing\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"Computer Science\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Pacific Symposium on Biocomputing. Pacific Symposium on Biocomputing","FirstCategoryId":"1085","ListUrlMain":"","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Computer Science","Score":null,"Total":0}
Machine Learning Strategies for Improved Phenotype Prediction in Underrepresented Populations.
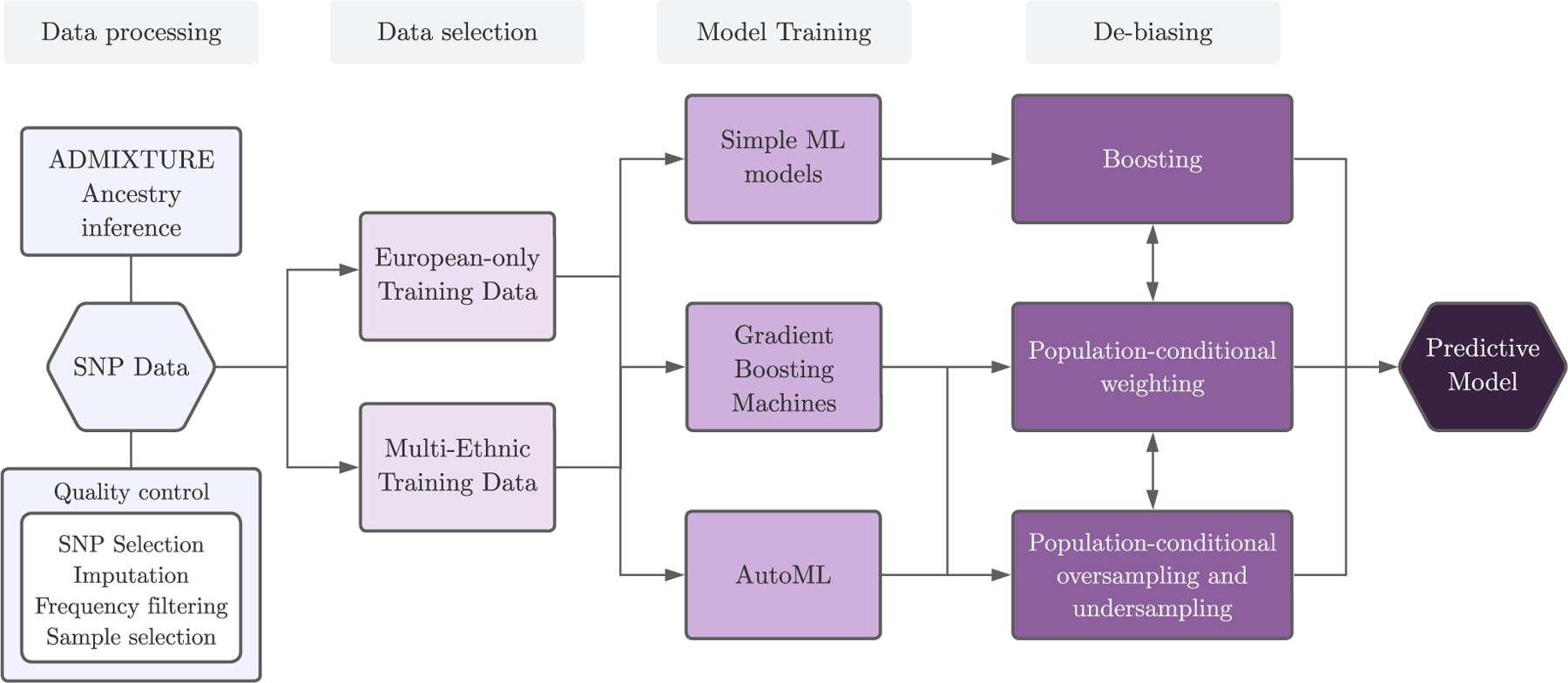
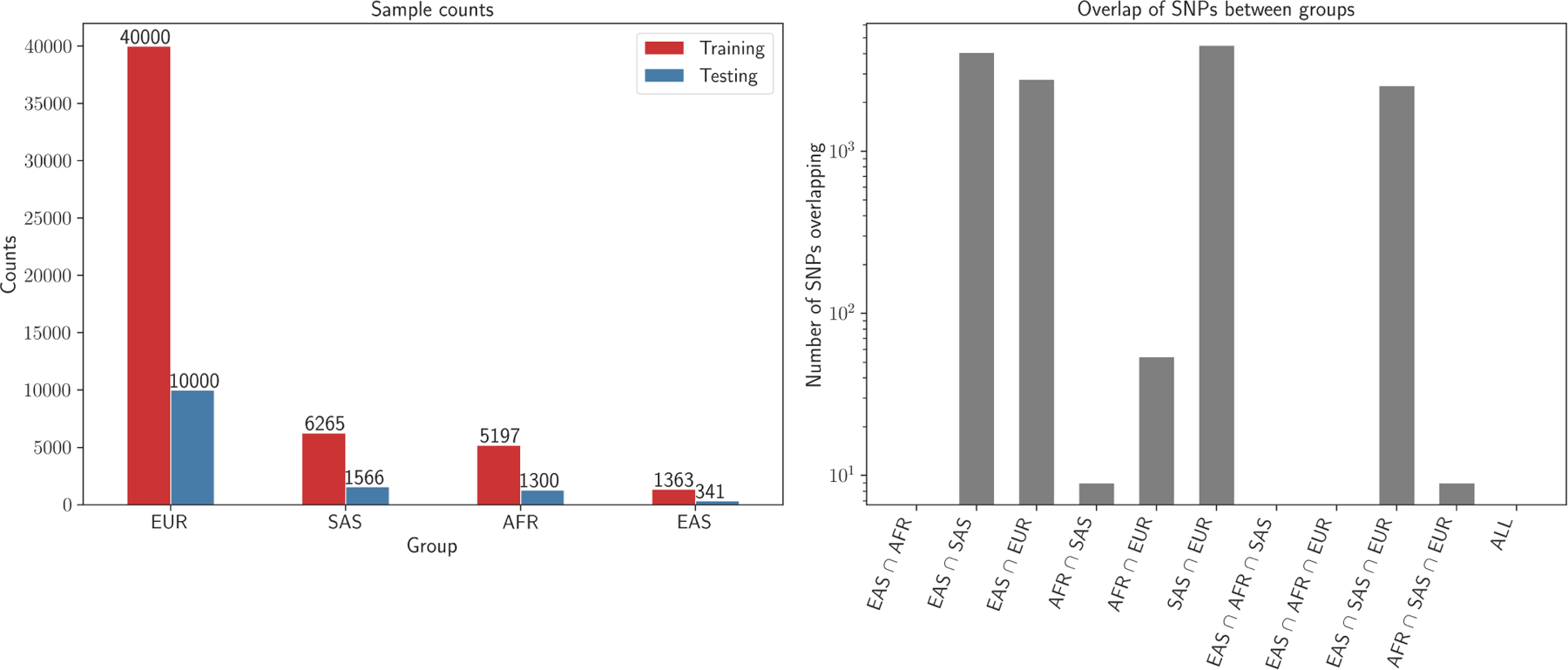
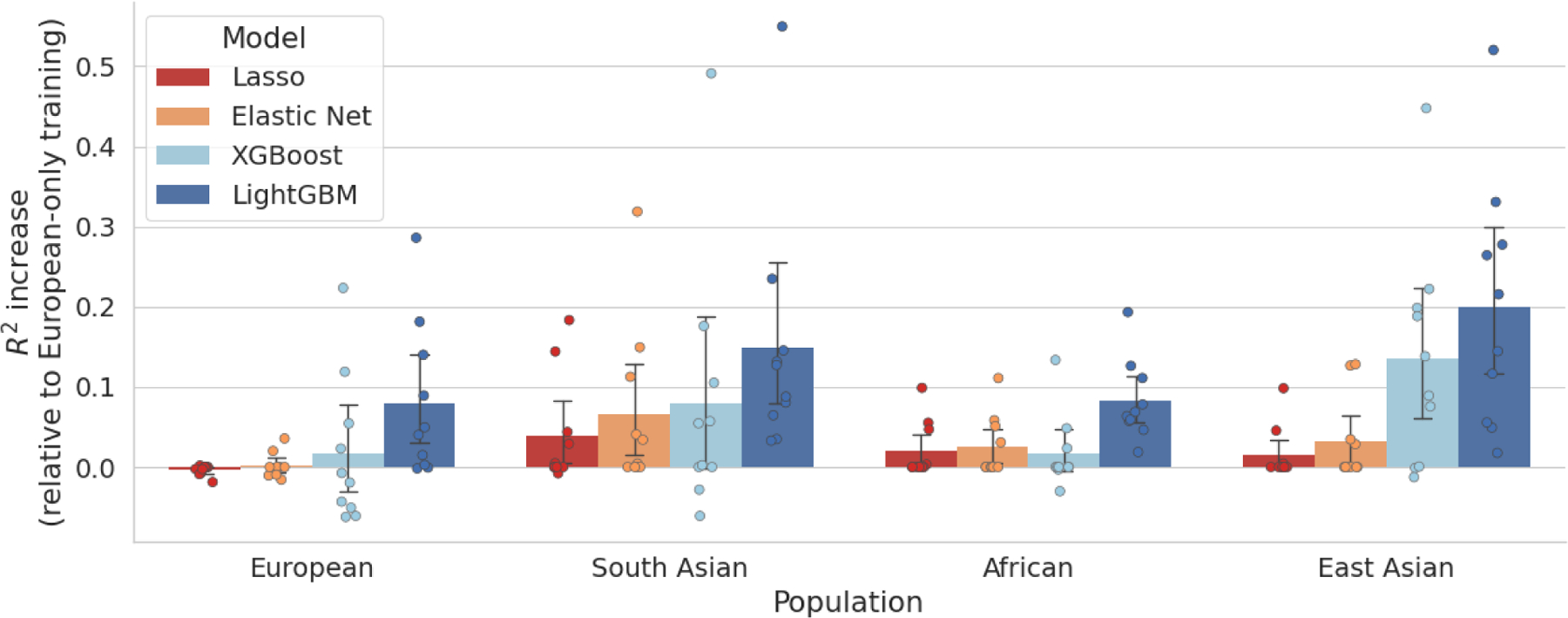
Precision medicine models often perform better for populations of European ancestry due to the over-representation of this group in the genomic datasets and large-scale biobanks from which the models are constructed. As a result, prediction models may misrepresent or provide less accurate treatment recommendations for underrepresented populations, contributing to health disparities. This study introduces an adaptable machine learning toolkit that integrates multiple existing methodologies and novel techniques to enhance the prediction accuracy for underrepresented populations in genomic datasets. By leveraging machine learning techniques, including gradient boosting and automated methods, coupled with novel population-conditional re-sampling techniques, our method significantly improves the phenotypic prediction from single nucleotide polymorphism (SNP) data for diverse populations. We evaluate our approach using the UK Biobank, which is composed primarily of British individuals with European ancestry, and a minority representation of groups with Asian and African ancestry. Performance metrics demonstrate substantial improvements in phenotype prediction for underrepresented groups, achieving prediction accuracy comparable to that of the majority group. This approach represents a significant step towards improving prediction accuracy amidst current dataset diversity challenges. By integrating a tailored pipeline, our approach fosters more equitable validity and utility of statistical genetics methods, paving the way for more inclusive models and outcomes.
 分享
分享




 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
