{"title":"用于语音情感识别的深度时空聚类特征","authors":"Wei-Cheng Lin, Carlos Busso","doi":"10.1016/j.specom.2023.103027","DOIUrl":null,"url":null,"abstract":"<div><p>Deep clustering is a popular unsupervised technique for feature representation learning. We recently proposed the chunk-based DeepEmoCluster framework for <em>speech emotion recognition</em> (SER) to adopt the concept of deep clustering as a novel <em>semi-supervised learning</em> (SSL) framework, which achieved improved recognition performances over conventional reconstruction-based approaches. However, the vanilla DeepEmoCluster lacks critical sentence-level temporal information that is useful for SER tasks. This study builds upon the DeepEmoCluster framework, creating a powerful SSL approach that leverages temporal information within a sentence. We propose two sentence-level temporal modeling alternatives using either the <em>temporal-net</em> or the <em>triplet loss</em> function, resulting in a novel temporal-enhanced DeepEmoCluster framework to capture essential temporal information. The key contribution to achieving this goal is the proposed sentence-level uniform sampling strategy, which preserves the original temporal order of the data for the clustering process. An extra network module (e.g., gated recurrent unit) is utilized for the temporal-net option to encode temporal information across the data chunks. Alternatively, we can impose additional temporal constraints by using the triplet loss function while training the DeepEmoCluster framework, which does not increase model complexity. Our experimental results based on the MSP-Podcast corpus demonstrate that the proposed temporal-enhanced framework significantly outperforms the vanilla DeepEmoCluster framework and other existing SSL approaches in regression tasks for the emotional attributes arousal, dominance, and valence. The improvements are observed in fully-supervised learning or SSL implementations. Further analyses validate the effectiveness of the proposed temporal modeling, showing (1) high temporal consistency in the cluster assignment, and (2) well-separated <em>emotional patterns</em> in the generated clusters.</p></div>","PeriodicalId":49485,"journal":{"name":"Speech Communication","volume":"157 ","pages":"Article 103027"},"PeriodicalIF":3.0000,"publicationDate":"2024-02-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S0167639323001619/pdfft?md5=8a58455c8fa8b02caee36f8fcfccf479&pid=1-s2.0-S0167639323001619-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Deep temporal clustering features for speech emotion recognition\",\"authors\":\"Wei-Cheng Lin, Carlos Busso\",\"doi\":\"10.1016/j.specom.2023.103027\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Deep clustering is a popular unsupervised technique for feature representation learning. We recently proposed the chunk-based DeepEmoCluster framework for <em>speech emotion recognition</em> (SER) to adopt the concept of deep clustering as a novel <em>semi-supervised learning</em> (SSL) framework, which achieved improved recognition performances over conventional reconstruction-based approaches. However, the vanilla DeepEmoCluster lacks critical sentence-level temporal information that is useful for SER tasks. This study builds upon the DeepEmoCluster framework, creating a powerful SSL approach that leverages temporal information within a sentence. We propose two sentence-level temporal modeling alternatives using either the <em>temporal-net</em> or the <em>triplet loss</em> function, resulting in a novel temporal-enhanced DeepEmoCluster framework to capture essential temporal information. The key contribution to achieving this goal is the proposed sentence-level uniform sampling strategy, which preserves the original temporal order of the data for the clustering process. An extra network module (e.g., gated recurrent unit) is utilized for the temporal-net option to encode temporal information across the data chunks. Alternatively, we can impose additional temporal constraints by using the triplet loss function while training the DeepEmoCluster framework, which does not increase model complexity. Our experimental results based on the MSP-Podcast corpus demonstrate that the proposed temporal-enhanced framework significantly outperforms the vanilla DeepEmoCluster framework and other existing SSL approaches in regression tasks for the emotional attributes arousal, dominance, and valence. The improvements are observed in fully-supervised learning or SSL implementations. Further analyses validate the effectiveness of the proposed temporal modeling, showing (1) high temporal consistency in the cluster assignment, and (2) well-separated <em>emotional patterns</em> in the generated clusters.</p></div>\",\"PeriodicalId\":49485,\"journal\":{\"name\":\"Speech Communication\",\"volume\":\"157 \",\"pages\":\"Article 103027\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2024-02-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S0167639323001619/pdfft?md5=8a58455c8fa8b02caee36f8fcfccf479&pid=1-s2.0-S0167639323001619-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Speech Communication\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0167639323001619\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/2 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"ACOUSTICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Speech Communication","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0167639323001619","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/2 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ACOUSTICS","Score":null,"Total":0}
Deep temporal clustering features for speech emotion recognition
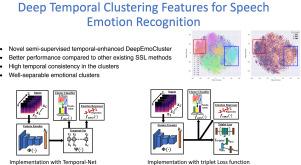
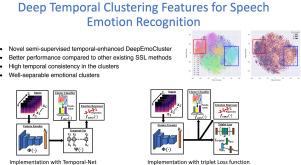
Deep clustering is a popular unsupervised technique for feature representation learning. We recently proposed the chunk-based DeepEmoCluster framework for speech emotion recognition (SER) to adopt the concept of deep clustering as a novel semi-supervised learning (SSL) framework, which achieved improved recognition performances over conventional reconstruction-based approaches. However, the vanilla DeepEmoCluster lacks critical sentence-level temporal information that is useful for SER tasks. This study builds upon the DeepEmoCluster framework, creating a powerful SSL approach that leverages temporal information within a sentence. We propose two sentence-level temporal modeling alternatives using either the temporal-net or the triplet loss function, resulting in a novel temporal-enhanced DeepEmoCluster framework to capture essential temporal information. The key contribution to achieving this goal is the proposed sentence-level uniform sampling strategy, which preserves the original temporal order of the data for the clustering process. An extra network module (e.g., gated recurrent unit) is utilized for the temporal-net option to encode temporal information across the data chunks. Alternatively, we can impose additional temporal constraints by using the triplet loss function while training the DeepEmoCluster framework, which does not increase model complexity. Our experimental results based on the MSP-Podcast corpus demonstrate that the proposed temporal-enhanced framework significantly outperforms the vanilla DeepEmoCluster framework and other existing SSL approaches in regression tasks for the emotional attributes arousal, dominance, and valence. The improvements are observed in fully-supervised learning or SSL implementations. Further analyses validate the effectiveness of the proposed temporal modeling, showing (1) high temporal consistency in the cluster assignment, and (2) well-separated emotional patterns in the generated clusters.
期刊介绍:
Speech Communication is an interdisciplinary journal whose primary objective is to fulfil the need for the rapid dissemination and thorough discussion of basic and applied research results.
The journal''s primary objectives are:
• to present a forum for the advancement of human and human-machine speech communication science;
• to stimulate cross-fertilization between different fields of this domain;
• to contribute towards the rapid and wide diffusion of scientifically sound contributions in this domain.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
