Robert Guralnick, Raphael LaFrance, Michael Denslow, Samantha Blickhan, Mark Bouslog, Sean Miller, Jenn Yost, Jason Best, Deborah L. Paul, Elizabeth Ellwood, Edward Gilbert, Julie Allen
{"title":"人类在循环中:社区科学与机器学习协同克服标本馆数字化瓶颈","authors":"Robert Guralnick, Raphael LaFrance, Michael Denslow, Samantha Blickhan, Mark Bouslog, Sean Miller, Jenn Yost, Jason Best, Deborah L. Paul, Elizabeth Ellwood, Edward Gilbert, Julie Allen","doi":"10.1002/aps3.11560","DOIUrl":null,"url":null,"abstract":"<div>\n \n \n <section>\n \n <h3> Premise</h3>\n \n <p>Among the slowest steps in the digitization of natural history collections is converting imaged labels into digital text. We present here a working solution to overcome this long-recognized efficiency bottleneck that leverages synergies between community science efforts and machine learning approaches.</p>\n </section>\n \n <section>\n \n <h3> Methods</h3>\n \n <p>We present two new semi-automated services. The first detects and classifies typewritten, handwritten, or mixed labels from herbarium sheets. The second uses a workflow tuned for specimen labels to label text using optical character recognition (OCR). The label finder and classifier was built via humans-in-the-loop processes that utilize the community science Notes from Nature platform to develop training and validation data sets to feed into a machine learning pipeline.</p>\n </section>\n \n <section>\n \n <h3> Results</h3>\n \n <p>Our results showcase a >93% success rate for finding and classifying main labels. The OCR pipeline optimizes pre-processing, multiple OCR engines, and post-processing steps, including an alignment approach borrowed from molecular systematics. This pipeline yields >4-fold reductions in errors compared to off-the-shelf open-source solutions. The OCR workflow also allows human validation using a custom Notes from Nature tool.</p>\n </section>\n \n <section>\n \n <h3> Discussion</h3>\n \n <p>Our work showcases a usable set of tools for herbarium digitization including a custom-built web application that is freely accessible. Further work to better integrate these services into existing toolkits can support broad community use.</p>\n </section>\n </div>","PeriodicalId":8022,"journal":{"name":"Applications in Plant Sciences","volume":"12 1","pages":""},"PeriodicalIF":3.5000,"publicationDate":"2024-01-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/aps3.11560","citationCount":"0","resultStr":"{\"title\":\"Humans in the loop: Community science and machine learning synergies for overcoming herbarium digitization bottlenecks\",\"authors\":\"Robert Guralnick, Raphael LaFrance, Michael Denslow, Samantha Blickhan, Mark Bouslog, Sean Miller, Jenn Yost, Jason Best, Deborah L. Paul, Elizabeth Ellwood, Edward Gilbert, Julie Allen\",\"doi\":\"10.1002/aps3.11560\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div>\\n \\n \\n <section>\\n \\n <h3> Premise</h3>\\n \\n <p>Among the slowest steps in the digitization of natural history collections is converting imaged labels into digital text. We present here a working solution to overcome this long-recognized efficiency bottleneck that leverages synergies between community science efforts and machine learning approaches.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Methods</h3>\\n \\n <p>We present two new semi-automated services. The first detects and classifies typewritten, handwritten, or mixed labels from herbarium sheets. The second uses a workflow tuned for specimen labels to label text using optical character recognition (OCR). The label finder and classifier was built via humans-in-the-loop processes that utilize the community science Notes from Nature platform to develop training and validation data sets to feed into a machine learning pipeline.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Results</h3>\\n \\n <p>Our results showcase a >93% success rate for finding and classifying main labels. The OCR pipeline optimizes pre-processing, multiple OCR engines, and post-processing steps, including an alignment approach borrowed from molecular systematics. This pipeline yields >4-fold reductions in errors compared to off-the-shelf open-source solutions. The OCR workflow also allows human validation using a custom Notes from Nature tool.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Discussion</h3>\\n \\n <p>Our work showcases a usable set of tools for herbarium digitization including a custom-built web application that is freely accessible. Further work to better integrate these services into existing toolkits can support broad community use.</p>\\n </section>\\n </div>\",\"PeriodicalId\":8022,\"journal\":{\"name\":\"Applications in Plant Sciences\",\"volume\":\"12 1\",\"pages\":\"\"},\"PeriodicalIF\":3.5000,\"publicationDate\":\"2024-01-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/aps3.11560\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Applications in Plant Sciences\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://bsapubs.onlinelibrary.wiley.com/doi/10.1002/aps3.11560\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"PLANT SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Applications in Plant Sciences","FirstCategoryId":"99","ListUrlMain":"https://bsapubs.onlinelibrary.wiley.com/doi/10.1002/aps3.11560","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PLANT SCIENCES","Score":null,"Total":0}
Humans in the loop: Community science and machine learning synergies for overcoming herbarium digitization bottlenecks
Premise
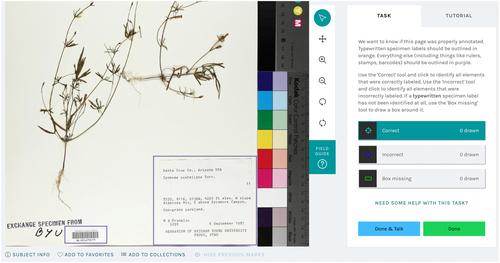
Among the slowest steps in the digitization of natural history collections is converting imaged labels into digital text. We present here a working solution to overcome this long-recognized efficiency bottleneck that leverages synergies between community science efforts and machine learning approaches.
Methods
We present two new semi-automated services. The first detects and classifies typewritten, handwritten, or mixed labels from herbarium sheets. The second uses a workflow tuned for specimen labels to label text using optical character recognition (OCR). The label finder and classifier was built via humans-in-the-loop processes that utilize the community science Notes from Nature platform to develop training and validation data sets to feed into a machine learning pipeline.
Results
Our results showcase a >93% success rate for finding and classifying main labels. The OCR pipeline optimizes pre-processing, multiple OCR engines, and post-processing steps, including an alignment approach borrowed from molecular systematics. This pipeline yields >4-fold reductions in errors compared to off-the-shelf open-source solutions. The OCR workflow also allows human validation using a custom Notes from Nature tool.
Discussion
Our work showcases a usable set of tools for herbarium digitization including a custom-built web application that is freely accessible. Further work to better integrate these services into existing toolkits can support broad community use.
期刊介绍:
Applications in Plant Sciences (APPS) is a monthly, peer-reviewed, open access journal promoting the rapid dissemination of newly developed, innovative tools and protocols in all areas of the plant sciences, including genetics, structure, function, development, evolution, systematics, and ecology. Given the rapid progress today in technology and its application in the plant sciences, the goal of APPS is to foster communication within the plant science community to advance scientific research. APPS is a publication of the Botanical Society of America, originating in 2009 as the American Journal of Botany''s online-only section, AJB Primer Notes & Protocols in the Plant Sciences.
APPS publishes the following types of articles: (1) Protocol Notes describe new methods and technological advancements; (2) Genomic Resources Articles characterize the development and demonstrate the usefulness of newly developed genomic resources, including transcriptomes; (3) Software Notes detail new software applications; (4) Application Articles illustrate the application of a new protocol, method, or software application within the context of a larger study; (5) Review Articles evaluate available techniques, methods, or protocols; (6) Primer Notes report novel genetic markers with evidence of wide applicability.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
