Chunyan Zeng , Shixiong Feng , Zhifeng Wang , Yuhao Zhao , Kun Li , Xiangkui Wan
{"title":"基于序列高斯均值矩阵表示学习的音源记录设备识别","authors":"Chunyan Zeng , Shixiong Feng , Zhifeng Wang , Yuhao Zhao , Kun Li , Xiangkui Wan","doi":"10.1016/j.fsidi.2023.301676","DOIUrl":null,"url":null,"abstract":"<div><p>Audio source recording device recognition is a critical digital forensic task that involves identifying the source device based on intrinsic audio characteristics. This technology finds widespread application in various digital audio forensic scenarios, including audio source forensics, tamper detection forensics, and copyright protection forensics. However, existing methods often suffer from low accuracy due to limited information utilization. In this study, we propose a novel method for source recording device recognition, grounded in feature representation learning. Our approach aims to overcome the limitations of current methods. We introduce a temporal audio feature called the “Sequential Gaussian Mean Matrix (SGMM),” which is derived from temporal segmented acoustic features. We then design a structured representation learning model that combines Convolutional Neural Networks (CNN) and Bidirectional Long Short-Term Memory Networks (BiLSTM). This model leverages temporal Gaussian representation and convolutional bottleneck representation to effectively condense spatial information and achieve accurate recognition through temporal modeling. Our experimental results demonstrate an impressive recognition accuracy of 98.78%, showcasing the effectiveness of our method in identifying multiple classes of recording devices. Importantly, our approach outperforms state-of-the-art methods in terms of recognition performance. Our implementing code is publicly available at <span>https://github.com/CCNUZFW/SGMM</span><svg><path></path></svg>.</p></div>","PeriodicalId":48481,"journal":{"name":"Forensic Science International-Digital Investigation","volume":"48 ","pages":"Article 301676"},"PeriodicalIF":2.2000,"publicationDate":"2024-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2666281723001956/pdfft?md5=c1cfb493d8976bb73053a81857e80514&pid=1-s2.0-S2666281723001956-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Audio source recording device recognition based on representation learning of sequential Gaussian mean matrix\",\"authors\":\"Chunyan Zeng , Shixiong Feng , Zhifeng Wang , Yuhao Zhao , Kun Li , Xiangkui Wan\",\"doi\":\"10.1016/j.fsidi.2023.301676\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Audio source recording device recognition is a critical digital forensic task that involves identifying the source device based on intrinsic audio characteristics. This technology finds widespread application in various digital audio forensic scenarios, including audio source forensics, tamper detection forensics, and copyright protection forensics. However, existing methods often suffer from low accuracy due to limited information utilization. In this study, we propose a novel method for source recording device recognition, grounded in feature representation learning. Our approach aims to overcome the limitations of current methods. We introduce a temporal audio feature called the “Sequential Gaussian Mean Matrix (SGMM),” which is derived from temporal segmented acoustic features. We then design a structured representation learning model that combines Convolutional Neural Networks (CNN) and Bidirectional Long Short-Term Memory Networks (BiLSTM). This model leverages temporal Gaussian representation and convolutional bottleneck representation to effectively condense spatial information and achieve accurate recognition through temporal modeling. Our experimental results demonstrate an impressive recognition accuracy of 98.78%, showcasing the effectiveness of our method in identifying multiple classes of recording devices. Importantly, our approach outperforms state-of-the-art methods in terms of recognition performance. Our implementing code is publicly available at <span>https://github.com/CCNUZFW/SGMM</span><svg><path></path></svg>.</p></div>\",\"PeriodicalId\":48481,\"journal\":{\"name\":\"Forensic Science International-Digital Investigation\",\"volume\":\"48 \",\"pages\":\"Article 301676\"},\"PeriodicalIF\":2.2000,\"publicationDate\":\"2024-03-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S2666281723001956/pdfft?md5=c1cfb493d8976bb73053a81857e80514&pid=1-s2.0-S2666281723001956-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Forensic Science International-Digital Investigation\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2666281723001956\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/8 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Forensic Science International-Digital Investigation","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2666281723001956","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/8 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
Audio source recording device recognition based on representation learning of sequential Gaussian mean matrix
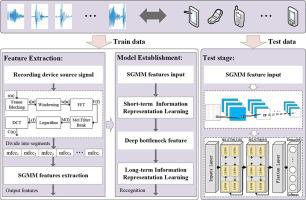
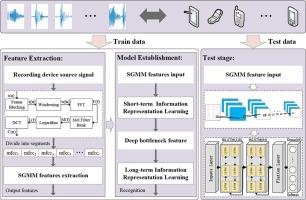
Audio source recording device recognition is a critical digital forensic task that involves identifying the source device based on intrinsic audio characteristics. This technology finds widespread application in various digital audio forensic scenarios, including audio source forensics, tamper detection forensics, and copyright protection forensics. However, existing methods often suffer from low accuracy due to limited information utilization. In this study, we propose a novel method for source recording device recognition, grounded in feature representation learning. Our approach aims to overcome the limitations of current methods. We introduce a temporal audio feature called the “Sequential Gaussian Mean Matrix (SGMM),” which is derived from temporal segmented acoustic features. We then design a structured representation learning model that combines Convolutional Neural Networks (CNN) and Bidirectional Long Short-Term Memory Networks (BiLSTM). This model leverages temporal Gaussian representation and convolutional bottleneck representation to effectively condense spatial information and achieve accurate recognition through temporal modeling. Our experimental results demonstrate an impressive recognition accuracy of 98.78%, showcasing the effectiveness of our method in identifying multiple classes of recording devices. Importantly, our approach outperforms state-of-the-art methods in terms of recognition performance. Our implementing code is publicly available at https://github.com/CCNUZFW/SGMM.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
