Di Yang, Yaohui Wang, Antitza Dantcheva, Lorenzo Garattoni, Gianpiero Francesca, François Brémond
{"title":"通过运动重定位学习视图不变骨架动作表征","authors":"Di Yang, Yaohui Wang, Antitza Dantcheva, Lorenzo Garattoni, Gianpiero Francesca, François Brémond","doi":"10.1007/s11263-023-01967-8","DOIUrl":null,"url":null,"abstract":"<p>Current self-supervised approaches for skeleton action representation learning often focus on constrained scenarios, where videos and skeleton data are recorded in laboratory settings. When dealing with estimated skeleton data in <i>real-world videos</i>, such methods perform poorly due to the large variations across subjects and camera viewpoints. To address this issue, we introduce ViA, a novel View-Invariant Autoencoder for self-supervised skeleton action representation learning. ViA leverages motion retargeting between different human performers as a pretext task, in order to disentangle the latent action-specific ‘Motion’ features on top of the visual representation of a 2D or 3D skeleton sequence. Such ‘Motion’ features are invariant to skeleton geometry and camera view and allow ViA to facilitate both, cross-subject and cross-view action classification tasks. We conduct a study focusing on transfer-learning for skeleton-based action recognition with self-supervised pre-training on real-world data (<i>e.g.</i>, Posetics). Our results showcase that skeleton representations learned from ViA are generic enough to improve upon state-of-the-art action classification accuracy, not only on 3D laboratory datasets such as NTU-RGB+D 60 and NTU-RGB+D 120, but also on real-world datasets where only 2D data are accurately estimated, <i>e.g.</i>, Toyota Smarthome, UAV-Human and Penn Action. Code and models will be publicly available at https://walker-a11y.github.io/ViA-project.</p>","PeriodicalId":13752,"journal":{"name":"International Journal of Computer Vision","volume":"9 1","pages":""},"PeriodicalIF":10.3000,"publicationDate":"2024-01-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"View-Invariant Skeleton Action Representation Learning via Motion Retargeting\",\"authors\":\"Di Yang, Yaohui Wang, Antitza Dantcheva, Lorenzo Garattoni, Gianpiero Francesca, François Brémond\",\"doi\":\"10.1007/s11263-023-01967-8\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Current self-supervised approaches for skeleton action representation learning often focus on constrained scenarios, where videos and skeleton data are recorded in laboratory settings. When dealing with estimated skeleton data in <i>real-world videos</i>, such methods perform poorly due to the large variations across subjects and camera viewpoints. To address this issue, we introduce ViA, a novel View-Invariant Autoencoder for self-supervised skeleton action representation learning. ViA leverages motion retargeting between different human performers as a pretext task, in order to disentangle the latent action-specific ‘Motion’ features on top of the visual representation of a 2D or 3D skeleton sequence. Such ‘Motion’ features are invariant to skeleton geometry and camera view and allow ViA to facilitate both, cross-subject and cross-view action classification tasks. We conduct a study focusing on transfer-learning for skeleton-based action recognition with self-supervised pre-training on real-world data (<i>e.g.</i>, Posetics). Our results showcase that skeleton representations learned from ViA are generic enough to improve upon state-of-the-art action classification accuracy, not only on 3D laboratory datasets such as NTU-RGB+D 60 and NTU-RGB+D 120, but also on real-world datasets where only 2D data are accurately estimated, <i>e.g.</i>, Toyota Smarthome, UAV-Human and Penn Action. Code and models will be publicly available at https://walker-a11y.github.io/ViA-project.</p>\",\"PeriodicalId\":13752,\"journal\":{\"name\":\"International Journal of Computer Vision\",\"volume\":\"9 1\",\"pages\":\"\"},\"PeriodicalIF\":10.3000,\"publicationDate\":\"2024-01-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"International Journal of Computer Vision\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11263-023-01967-8\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11263-023-01967-8","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
摘要
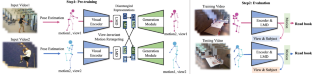
目前用于骨架动作表示学习的自监督方法通常侧重于受限场景,即在实验室环境中记录视频和骨架数据。在处理真实世界视频中的估计骨架数据时,由于不同被试和摄像机视点之间存在巨大差异,这些方法的效果很差。为了解决这个问题,我们引入了 ViA,一种用于自我监督骨架动作表示学习的新型视图不变自动编码器。ViA 利用不同人类表演者之间的运动重定向作为前置任务,以便在二维或三维骨架序列的视觉表示之上分离出潜在的特定动作 "运动 "特征。这些 "运动 "特征不受骨架几何形状和摄像机视角的影响,因此 ViA 可以帮助完成跨主体和跨视角的动作分类任务。我们在真实世界数据(如 Posetics)上进行了一项研究,重点研究了基于骨架的动作识别的迁移学习,并进行了自我监督预训练。我们的研究结果表明,从 ViA 中学习到的骨架表征不仅在 NTU-RGB+D 60 和 NTU-RGB+D 120 等三维实验室数据集上,而且在仅能准确估计二维数据的真实世界数据集(如丰田智能家居、UAV-Human 和 Penn Action)上,都足以提高最先进的动作分类准确性。代码和模型将在 https://walker-a11y.github.io/ViA-project 上公开。
View-Invariant Skeleton Action Representation Learning via Motion Retargeting
Current self-supervised approaches for skeleton action representation learning often focus on constrained scenarios, where videos and skeleton data are recorded in laboratory settings. When dealing with estimated skeleton data in real-world videos, such methods perform poorly due to the large variations across subjects and camera viewpoints. To address this issue, we introduce ViA, a novel View-Invariant Autoencoder for self-supervised skeleton action representation learning. ViA leverages motion retargeting between different human performers as a pretext task, in order to disentangle the latent action-specific ‘Motion’ features on top of the visual representation of a 2D or 3D skeleton sequence. Such ‘Motion’ features are invariant to skeleton geometry and camera view and allow ViA to facilitate both, cross-subject and cross-view action classification tasks. We conduct a study focusing on transfer-learning for skeleton-based action recognition with self-supervised pre-training on real-world data (e.g., Posetics). Our results showcase that skeleton representations learned from ViA are generic enough to improve upon state-of-the-art action classification accuracy, not only on 3D laboratory datasets such as NTU-RGB+D 60 and NTU-RGB+D 120, but also on real-world datasets where only 2D data are accurately estimated, e.g., Toyota Smarthome, UAV-Human and Penn Action. Code and models will be publicly available at https://walker-a11y.github.io/ViA-project.
期刊介绍:
The International Journal of Computer Vision (IJCV) serves as a platform for sharing new research findings in the rapidly growing field of computer vision. It publishes 12 issues annually and presents high-quality, original contributions to the science and engineering of computer vision. The journal encompasses various types of articles to cater to different research outputs.
Regular articles, which span up to 25 journal pages, focus on significant technical advancements that are of broad interest to the field. These articles showcase substantial progress in computer vision.
Short articles, limited to 10 pages, offer a swift publication path for novel research outcomes. They provide a quicker means for sharing new findings with the computer vision community.
Survey articles, comprising up to 30 pages, offer critical evaluations of the current state of the art in computer vision or offer tutorial presentations of relevant topics. These articles provide comprehensive and insightful overviews of specific subject areas.
In addition to technical articles, the journal also includes book reviews, position papers, and editorials by prominent scientific figures. These contributions serve to complement the technical content and provide valuable perspectives.
The journal encourages authors to include supplementary material online, such as images, video sequences, data sets, and software. This additional material enhances the understanding and reproducibility of the published research.
Overall, the International Journal of Computer Vision is a comprehensive publication that caters to researchers in this rapidly growing field. It covers a range of article types, offers additional online resources, and facilitates the dissemination of impactful research.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
