{"title":"LCMS:用于脂质组学自动半靶向分析的 R 软件包","authors":"Caroline Peltier, Glenda Vasku, Marine Crépin, Stephanie Cabaret, Olivier Berdeaux","doi":"10.1002/ejlt.202300077","DOIUrl":null,"url":null,"abstract":"<p>While nontargeted analysis aims to profile and report the relative distributions of a wide range of molecules from different lipid classes/subclasses, its major challenge is the annotation and identification of the molecules. Semitargeted analysis circumvents the problem by establishing a (potentially large) list of molecules to be targeted in the samples that are identified before the analysis. This approach is particularly adapted for lipid analysis to help with the automation of lipid annotation and identification. However, the manual extraction of peaks for many molecules and many samples is time consuming. Consequently, an automation of these extractions is deeply required. This paper presents a free R package for the automation of semitargeted analysis for lipid analysis. From raw files collected with LC-MS device and a list of molecules to target (containing their class), it automatically returns Excel files containing the intensities for each targeted molecule and each sample. This package allows a fast computation of the intensities. Furthermore, it guarantees the reproducibility of the results and is freely available and user-friendly.</p><p><i>Practical Applications</i>: With the help of the R package presented in this paper, the use of semitargeted lipidomics as an alternative to untargeted analysis should be investigated by more labs. Work on the comparisons between the approaches could be conducted. While untargeted methods are mostly used, they require long pretreatments and identification of molecules of interest. On the contrary, in semitargeted analysis, once the integration table and retention time are obtained, the results are fast and directly interpretable. An idea for lipidomics would be to use untargeted lipidomics to compute the integration table and retention table, then use semitargeted analysis for a fast computation of well identified molecules.</p>","PeriodicalId":11988,"journal":{"name":"European Journal of Lipid Science and Technology","volume":"126 3","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2024-01-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/ejlt.202300077","citationCount":"0","resultStr":"{\"title\":\"LCMS: An R package for automated semitargeted analysis in lipidomics\",\"authors\":\"Caroline Peltier, Glenda Vasku, Marine Crépin, Stephanie Cabaret, Olivier Berdeaux\",\"doi\":\"10.1002/ejlt.202300077\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>While nontargeted analysis aims to profile and report the relative distributions of a wide range of molecules from different lipid classes/subclasses, its major challenge is the annotation and identification of the molecules. Semitargeted analysis circumvents the problem by establishing a (potentially large) list of molecules to be targeted in the samples that are identified before the analysis. This approach is particularly adapted for lipid analysis to help with the automation of lipid annotation and identification. However, the manual extraction of peaks for many molecules and many samples is time consuming. Consequently, an automation of these extractions is deeply required. This paper presents a free R package for the automation of semitargeted analysis for lipid analysis. From raw files collected with LC-MS device and a list of molecules to target (containing their class), it automatically returns Excel files containing the intensities for each targeted molecule and each sample. This package allows a fast computation of the intensities. Furthermore, it guarantees the reproducibility of the results and is freely available and user-friendly.</p><p><i>Practical Applications</i>: With the help of the R package presented in this paper, the use of semitargeted lipidomics as an alternative to untargeted analysis should be investigated by more labs. Work on the comparisons between the approaches could be conducted. While untargeted methods are mostly used, they require long pretreatments and identification of molecules of interest. On the contrary, in semitargeted analysis, once the integration table and retention time are obtained, the results are fast and directly interpretable. An idea for lipidomics would be to use untargeted lipidomics to compute the integration table and retention table, then use semitargeted analysis for a fast computation of well identified molecules.</p>\",\"PeriodicalId\":11988,\"journal\":{\"name\":\"European Journal of Lipid Science and Technology\",\"volume\":\"126 3\",\"pages\":\"\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2024-01-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/ejlt.202300077\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"European Journal of Lipid Science and Technology\",\"FirstCategoryId\":\"97\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/ejlt.202300077\",\"RegionNum\":3,\"RegionCategory\":\"农林科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"FOOD SCIENCE & TECHNOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"European Journal of Lipid Science and Technology","FirstCategoryId":"97","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/ejlt.202300077","RegionNum":3,"RegionCategory":"农林科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"FOOD SCIENCE & TECHNOLOGY","Score":null,"Total":0}
引用次数: 0
摘要
非靶向分析的目的是分析和报告不同脂质类别/亚类中各种分子的相对分布情况,其主要挑战在于分子的注释和识别。半靶向分析法通过建立一个(可能很大的)靶向分子列表来规避这一问题,该列表在分析前就已在样品中确定。这种方法尤其适用于脂质分析,有助于实现脂质注释和鉴定的自动化。然而,手动提取许多分子和许多样品的峰值非常耗时。因此,这些提取工作亟需自动化。本文介绍了一个免费的 R 软件包,用于脂质分析的半目标分析自动化。从 LC-MS 设备收集的原始文件和目标分子列表(包含分子类别)中,它能自动返回包含每个目标分子和每个样本强度的 Excel 文件。该软件包可快速计算强度。此外,它还能保证结果的可重复性,并且免费提供,用户使用方便。
LCMS: An R package for automated semitargeted analysis in lipidomics
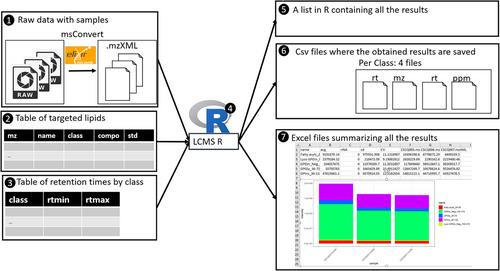
While nontargeted analysis aims to profile and report the relative distributions of a wide range of molecules from different lipid classes/subclasses, its major challenge is the annotation and identification of the molecules. Semitargeted analysis circumvents the problem by establishing a (potentially large) list of molecules to be targeted in the samples that are identified before the analysis. This approach is particularly adapted for lipid analysis to help with the automation of lipid annotation and identification. However, the manual extraction of peaks for many molecules and many samples is time consuming. Consequently, an automation of these extractions is deeply required. This paper presents a free R package for the automation of semitargeted analysis for lipid analysis. From raw files collected with LC-MS device and a list of molecules to target (containing their class), it automatically returns Excel files containing the intensities for each targeted molecule and each sample. This package allows a fast computation of the intensities. Furthermore, it guarantees the reproducibility of the results and is freely available and user-friendly.
Practical Applications: With the help of the R package presented in this paper, the use of semitargeted lipidomics as an alternative to untargeted analysis should be investigated by more labs. Work on the comparisons between the approaches could be conducted. While untargeted methods are mostly used, they require long pretreatments and identification of molecules of interest. On the contrary, in semitargeted analysis, once the integration table and retention time are obtained, the results are fast and directly interpretable. An idea for lipidomics would be to use untargeted lipidomics to compute the integration table and retention table, then use semitargeted analysis for a fast computation of well identified molecules.
期刊介绍:
The European Journal of Lipid Science and Technology is a peer-reviewed journal publishing original research articles, reviews, and other contributions on lipid related topics in food science and technology, biomedical science including clinical and pre-clinical research, nutrition, animal science, plant and microbial lipids, (bio)chemistry, oleochemistry, biotechnology, processing, physical chemistry, and analytics including lipidomics. A major focus of the journal is the synthesis of health related topics with applied aspects.
Following is a selection of subject areas which are of special interest to EJLST:
Animal and plant products for healthier foods including strategic feeding and transgenic crops
Authentication and analysis of foods for ensuring food quality and safety
Bioavailability of PUFA and other nutrients
Dietary lipids and minor compounds, their specific roles in food products and in nutrition
Food technology and processing for safer and healthier products
Functional foods and nutraceuticals
Lipidomics
Lipid structuring and formulations
Oleochemistry, lipid-derived polymers and biomaterials
Processes using lipid-modifying enzymes
The scope is not restricted to these areas. Submissions on topics at the interface of basic research and applications are strongly encouraged. The journal is the official organ the European Federation for the Science and Technology of Lipids (Euro Fed Lipid).




 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
