{"title":"软标签引导的无监督判别稀疏子空间特征选择","authors":"Keding Chen, Yong Peng, Feiping Nie, Wanzeng Kong","doi":"10.1007/s00357-024-09462-6","DOIUrl":null,"url":null,"abstract":"<p>Feature selection and subspace learning are two primary methods to achieve data dimensionality reduction and discriminability enhancement. However, data label information is unavailable in unsupervised learning to guide the dimensionality reduction process. To this end, we propose a soft label guided unsupervised discriminative sparse subspace feature selection (UDS<span>\\(^2\\)</span>FS) model in this paper, which consists of two superiorities in comparison with the existing studies. On the one hand, UDS<span>\\(^2\\)</span>FS aims to find a discriminative subspace to simultaneously maximize the between-class data scatter and minimize the within-class scatter. On the other hand, UDS<span>\\(^2\\)</span>FS estimates the data label information in the learned subspace, which further serves as the soft labels to guide the discriminative subspace learning process. Moreover, the <span>\\(\\ell _{2,0}\\)</span>-norm is imposed to achieve row sparsity of the subspace projection matrix, which is parameter-free and more stable compared to the <span>\\(\\ell _{2,1}\\)</span>-norm. Experimental studies to evaluate the performance of UDS<span>\\(^2\\)</span>FS are performed from three aspects, i.e., a synthetic data set to check its iterative optimization process, several toy data sets to visualize the feature selection effect, and some benchmark data sets to examine the clustering performance of UDS<span>\\(^2\\)</span>FS. From the obtained results, UDS<span>\\(^2\\)</span>FS exhibits competitive performance in joint subspace learning and feature selection in comparison with some related models.</p>","PeriodicalId":50241,"journal":{"name":"Journal of Classification","volume":"330 1","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2024-01-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Soft Label Guided Unsupervised Discriminative Sparse Subspace Feature Selection\",\"authors\":\"Keding Chen, Yong Peng, Feiping Nie, Wanzeng Kong\",\"doi\":\"10.1007/s00357-024-09462-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Feature selection and subspace learning are two primary methods to achieve data dimensionality reduction and discriminability enhancement. However, data label information is unavailable in unsupervised learning to guide the dimensionality reduction process. To this end, we propose a soft label guided unsupervised discriminative sparse subspace feature selection (UDS<span>\\\\(^2\\\\)</span>FS) model in this paper, which consists of two superiorities in comparison with the existing studies. On the one hand, UDS<span>\\\\(^2\\\\)</span>FS aims to find a discriminative subspace to simultaneously maximize the between-class data scatter and minimize the within-class scatter. On the other hand, UDS<span>\\\\(^2\\\\)</span>FS estimates the data label information in the learned subspace, which further serves as the soft labels to guide the discriminative subspace learning process. Moreover, the <span>\\\\(\\\\ell _{2,0}\\\\)</span>-norm is imposed to achieve row sparsity of the subspace projection matrix, which is parameter-free and more stable compared to the <span>\\\\(\\\\ell _{2,1}\\\\)</span>-norm. Experimental studies to evaluate the performance of UDS<span>\\\\(^2\\\\)</span>FS are performed from three aspects, i.e., a synthetic data set to check its iterative optimization process, several toy data sets to visualize the feature selection effect, and some benchmark data sets to examine the clustering performance of UDS<span>\\\\(^2\\\\)</span>FS. From the obtained results, UDS<span>\\\\(^2\\\\)</span>FS exhibits competitive performance in joint subspace learning and feature selection in comparison with some related models.</p>\",\"PeriodicalId\":50241,\"journal\":{\"name\":\"Journal of Classification\",\"volume\":\"330 1\",\"pages\":\"\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2024-01-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Classification\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00357-024-09462-6\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Classification","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00357-024-09462-6","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
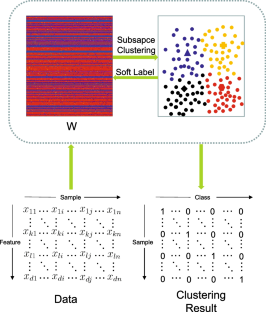
Feature selection and subspace learning are two primary methods to achieve data dimensionality reduction and discriminability enhancement. However, data label information is unavailable in unsupervised learning to guide the dimensionality reduction process. To this end, we propose a soft label guided unsupervised discriminative sparse subspace feature selection (UDS\(^2\)FS) model in this paper, which consists of two superiorities in comparison with the existing studies. On the one hand, UDS\(^2\)FS aims to find a discriminative subspace to simultaneously maximize the between-class data scatter and minimize the within-class scatter. On the other hand, UDS\(^2\)FS estimates the data label information in the learned subspace, which further serves as the soft labels to guide the discriminative subspace learning process. Moreover, the \(\ell _{2,0}\)-norm is imposed to achieve row sparsity of the subspace projection matrix, which is parameter-free and more stable compared to the \(\ell _{2,1}\)-norm. Experimental studies to evaluate the performance of UDS\(^2\)FS are performed from three aspects, i.e., a synthetic data set to check its iterative optimization process, several toy data sets to visualize the feature selection effect, and some benchmark data sets to examine the clustering performance of UDS\(^2\)FS. From the obtained results, UDS\(^2\)FS exhibits competitive performance in joint subspace learning and feature selection in comparison with some related models.
期刊介绍:
To publish original and valuable papers in the field of classification, numerical taxonomy, multidimensional scaling and other ordination techniques, clustering, tree structures and other network models (with somewhat less emphasis on principal components analysis, factor analysis, and discriminant analysis), as well as associated models and algorithms for fitting them. Articles will support advances in methodology while demonstrating compelling substantive applications. Comprehensive review articles are also acceptable. Contributions will represent disciplines such as statistics, psychology, biology, information retrieval, anthropology, archeology, astronomy, business, chemistry, computer science, economics, engineering, geography, geology, linguistics, marketing, mathematics, medicine, political science, psychiatry, sociology, and soil science.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
