André Fonseca, Mikolaj Spytek, Przemysław Biecek, Clara Cordeiro, Nuno Sepúlveda
{"title":"基于多血清数据的抗体选择策略及其对预测临床疟疾的影响。","authors":"André Fonseca, Mikolaj Spytek, Przemysław Biecek, Clara Cordeiro, Nuno Sepúlveda","doi":"10.1186/s13040-024-00354-4","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Nowadays, the chance of discovering the best antibody candidates for predicting clinical malaria has notably increased due to the availability of multi-sera data. The analysis of these data is typically divided into a feature selection phase followed by a predictive one where several models are constructed for predicting the outcome of interest. A key question in the analysis is to determine which antibodies should be included in the predictive stage and whether they should be included in the original or a transformed scale (i.e. binary/dichotomized).</p><p><strong>Methods: </strong>To answer this question, we developed three approaches for antibody selection in the context of predicting clinical malaria: (i) a basic and simple approach based on selecting antibodies via the nonparametric Mann-Whitney-Wilcoxon test; (ii) an optimal dychotomizationdichotomization approach where each antibody was selected according to the optimal cut-off via maximization of the chi-squared (χ<sup>2</sup>) statistic for two-way tables; (iii) a hybrid parametric/non-parametric approach that integrates Box-Cox transformation followed by a t-test, together with the use of finite mixture models and the Mann-Whitney-Wilcoxon test as a last resort. We illustrated the application of these three approaches with published serological data of 36 Plasmodium falciparum antigens for predicting clinical malaria in 121 Kenyan children. The predictive analysis was based on a Super Learner where predictions from multiple classifiers including the Random Forest were pooled together.</p><p><strong>Results: </strong>Our results led to almost similar areas under the Receiver Operating Characteristic curves of 0.72 (95% CI = [0.62, 0.82]), 0.80 (95% CI = [0.71, 0.89]), 0.79 (95% CI = [0.7, 0.88]) for the simple, dichotomization and hybrid approaches, respectively. These approaches were based on 6, 20, and 16 antibodies, respectively.</p><p><strong>Conclusions: </strong>The three feature selection strategies provided a better predictive performance of the outcome when compared to the previous results relying on Random Forest including all the 36 antibodies (AUC = 0.68, 95% CI = [0.57;0.79]). Given the similar predictive performance, we recommended that the three strategies should be used in conjunction in the same data set and selected according to their complexity.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"17 1","pages":"2"},"PeriodicalIF":6.1000,"publicationDate":"2024-01-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10811867/pdf/","citationCount":"0","resultStr":"{\"title\":\"Antibody selection strategies and their impact in predicting clinical malaria based on multi-sera data.\",\"authors\":\"André Fonseca, Mikolaj Spytek, Przemysław Biecek, Clara Cordeiro, Nuno Sepúlveda\",\"doi\":\"10.1186/s13040-024-00354-4\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Nowadays, the chance of discovering the best antibody candidates for predicting clinical malaria has notably increased due to the availability of multi-sera data. The analysis of these data is typically divided into a feature selection phase followed by a predictive one where several models are constructed for predicting the outcome of interest. A key question in the analysis is to determine which antibodies should be included in the predictive stage and whether they should be included in the original or a transformed scale (i.e. binary/dichotomized).</p><p><strong>Methods: </strong>To answer this question, we developed three approaches for antibody selection in the context of predicting clinical malaria: (i) a basic and simple approach based on selecting antibodies via the nonparametric Mann-Whitney-Wilcoxon test; (ii) an optimal dychotomizationdichotomization approach where each antibody was selected according to the optimal cut-off via maximization of the chi-squared (χ<sup>2</sup>) statistic for two-way tables; (iii) a hybrid parametric/non-parametric approach that integrates Box-Cox transformation followed by a t-test, together with the use of finite mixture models and the Mann-Whitney-Wilcoxon test as a last resort. We illustrated the application of these three approaches with published serological data of 36 Plasmodium falciparum antigens for predicting clinical malaria in 121 Kenyan children. The predictive analysis was based on a Super Learner where predictions from multiple classifiers including the Random Forest were pooled together.</p><p><strong>Results: </strong>Our results led to almost similar areas under the Receiver Operating Characteristic curves of 0.72 (95% CI = [0.62, 0.82]), 0.80 (95% CI = [0.71, 0.89]), 0.79 (95% CI = [0.7, 0.88]) for the simple, dichotomization and hybrid approaches, respectively. These approaches were based on 6, 20, and 16 antibodies, respectively.</p><p><strong>Conclusions: </strong>The three feature selection strategies provided a better predictive performance of the outcome when compared to the previous results relying on Random Forest including all the 36 antibodies (AUC = 0.68, 95% CI = [0.57;0.79]). Given the similar predictive performance, we recommended that the three strategies should be used in conjunction in the same data set and selected according to their complexity.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"17 1\",\"pages\":\"2\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2024-01-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10811867/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-024-00354-4\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-024-00354-4","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
摘要
背景:如今,由于多序列数据的可用性,发现用于预测临床疟疾的最佳候选抗体的机会显著增加。对这些数据的分析通常分为特征选择阶段和预测阶段,在预测阶段,需要构建多个模型来预测相关结果。分析中的一个关键问题是确定哪些抗体应纳入预测阶段,以及这些抗体应纳入原始量表还是转换量表(即二元/二分法):为了回答这个问题,我们开发了三种预测临床疟疾的抗体选择方法:(i) 通过非参数曼-惠特尼-威尔库克森检验(Mann-Whitney-Wilcoxon test)选择抗体的基本而简单的方法;(ii) 最佳二分法(optimal dychotomizationdichotomization),即通过最大化双向表的秩方(χ2)统计量,根据最佳截断值选择每种抗体;(iii) 参数/非参数混合法,即在进行方框-考克斯转换后进行 t 检验,同时使用有限混合物模型和 Mann-Whitney-Wilcoxon 检验作为最后手段。我们用已公布的 36 种恶性疟原虫抗原血清学数据说明了这三种方法在预测 121 名肯尼亚儿童临床疟疾方面的应用。预测分析以超级学习器为基础,将包括随机森林在内的多个分类器的预测结果汇集在一起:我们的结果表明,简单方法、二分法和混合方法的接收者工作特征曲线下的面积几乎相似,分别为 0.72 (95% CI = [0.62, 0.82])、0.80 (95% CI = [0.71, 0.89])、0.79 (95% CI = [0.7, 0.88])。这些方法分别基于 6、20 和 16 种抗体:与之前基于随机森林(包括所有 36 种抗体)的结果相比,这三种特征选择策略提供了更好的结果预测性能(AUC = 0.68,95% CI = [0.57;0.79])。鉴于预测性能相似,我们建议在同一数据集中同时使用这三种策略,并根据其复杂程度进行选择。
Antibody selection strategies and their impact in predicting clinical malaria based on multi-sera data.
Background: Nowadays, the chance of discovering the best antibody candidates for predicting clinical malaria has notably increased due to the availability of multi-sera data. The analysis of these data is typically divided into a feature selection phase followed by a predictive one where several models are constructed for predicting the outcome of interest. A key question in the analysis is to determine which antibodies should be included in the predictive stage and whether they should be included in the original or a transformed scale (i.e. binary/dichotomized).
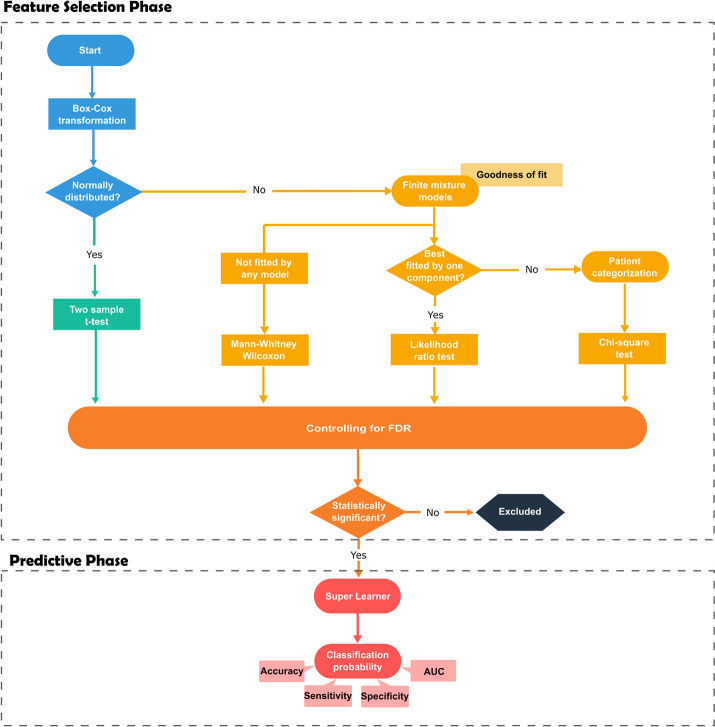
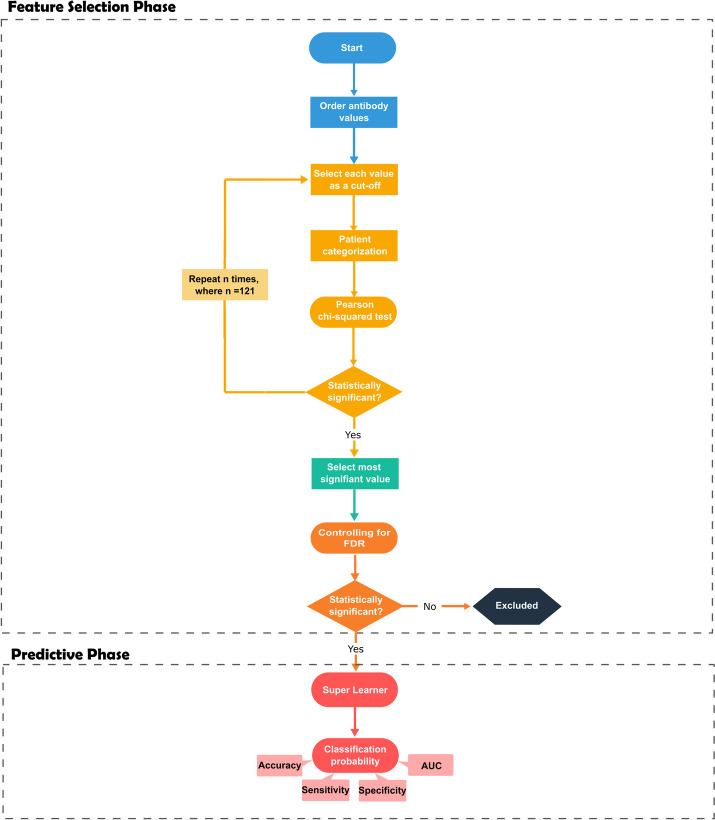
Methods: To answer this question, we developed three approaches for antibody selection in the context of predicting clinical malaria: (i) a basic and simple approach based on selecting antibodies via the nonparametric Mann-Whitney-Wilcoxon test; (ii) an optimal dychotomizationdichotomization approach where each antibody was selected according to the optimal cut-off via maximization of the chi-squared (χ2) statistic for two-way tables; (iii) a hybrid parametric/non-parametric approach that integrates Box-Cox transformation followed by a t-test, together with the use of finite mixture models and the Mann-Whitney-Wilcoxon test as a last resort. We illustrated the application of these three approaches with published serological data of 36 Plasmodium falciparum antigens for predicting clinical malaria in 121 Kenyan children. The predictive analysis was based on a Super Learner where predictions from multiple classifiers including the Random Forest were pooled together.
Results: Our results led to almost similar areas under the Receiver Operating Characteristic curves of 0.72 (95% CI = [0.62, 0.82]), 0.80 (95% CI = [0.71, 0.89]), 0.79 (95% CI = [0.7, 0.88]) for the simple, dichotomization and hybrid approaches, respectively. These approaches were based on 6, 20, and 16 antibodies, respectively.
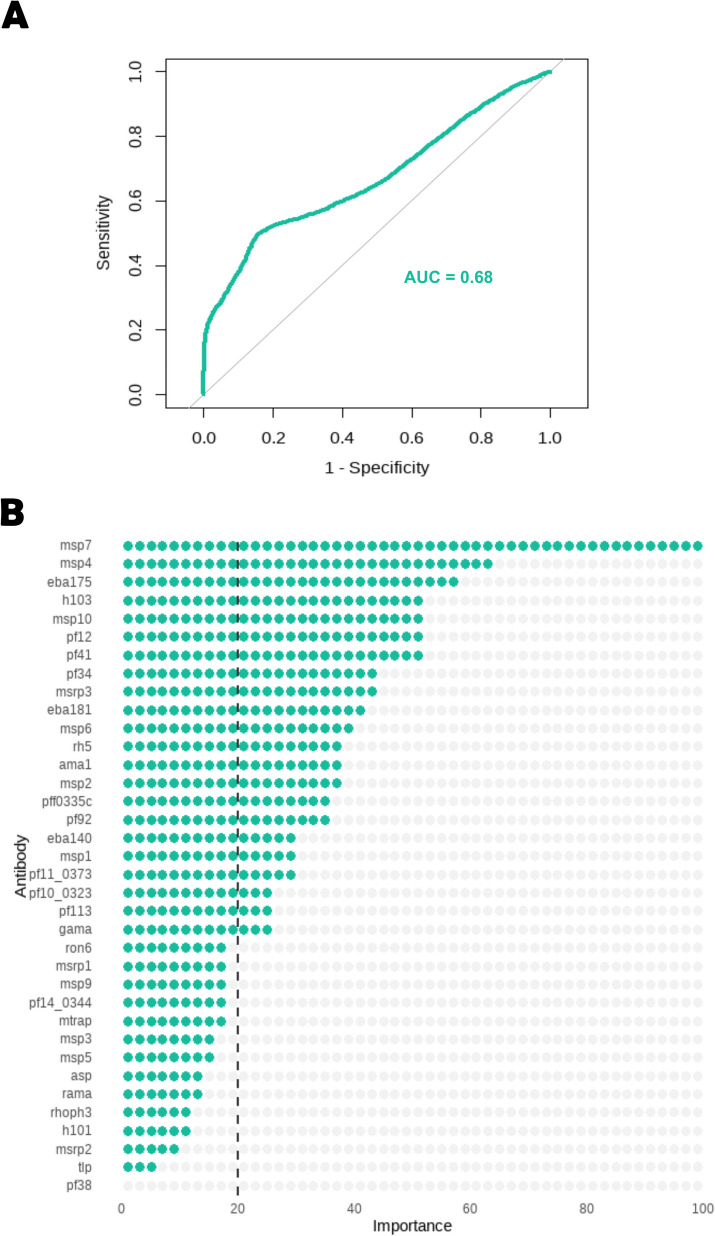
Conclusions: The three feature selection strategies provided a better predictive performance of the outcome when compared to the previous results relying on Random Forest including all the 36 antibodies (AUC = 0.68, 95% CI = [0.57;0.79]). Given the similar predictive performance, we recommended that the three strategies should be used in conjunction in the same data set and selected according to their complexity.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
