{"title":"多组学利用机器学习方法协助玉米产量的基因组预测。","authors":"Chengxiu Wu, Jingyun Luo, Yingjie Xiao","doi":"10.1007/s11032-024-01454-z","DOIUrl":null,"url":null,"abstract":"<p><p>With the improvement of high-throughput technologies in recent years, large multi-dimensional plant omics data have been produced, and big-data-driven yield prediction research has received increasing attention. Machine learning offers promising computational and analytical solutions to interpret the biological meaning of large amounts of data in crops. In this study, we utilized multi-omics datasets from 156 maize recombinant inbred lines, containing 2496 single nucleotide polymorphisms (SNPs), 46 image traits (i-traits) from 16 developmental stages obtained through an automatic phenotyping platform, and 133 primary metabolites. Based on benchmark tests with different types of prediction models, some machine learning methods, such as Partial Least Squares (PLS), Random Forest (RF), and Gaussian process with Radial basis function kernel (GaussprRadial), achieved better prediction for maize yield, albeit slight difference for method preferences among i-traits, genomic, and metabolic data. We found that better yield prediction may be caused by various capabilities in ranking and filtering data features, which is found to be linked with biological meaning such as photosynthesis-related or kernel development-related regulations. Finally, by integrating multiple omics data with the RF machine learning approach, we can further improve the prediction accuracy of grain yield from 0.32 to 0.43. Our research provides new ideas for the application of plant omics data and artificial intelligence approaches to facilitate crop genetic improvements.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at 10.1007/s11032-024-01454-z.</p>","PeriodicalId":18769,"journal":{"name":"Molecular Breeding","volume":"44 2","pages":"14"},"PeriodicalIF":3.0000,"publicationDate":"2024-02-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10853138/pdf/","citationCount":"0","resultStr":"{\"title\":\"Multi-omics assists genomic prediction of maize yield with machine learning approaches.\",\"authors\":\"Chengxiu Wu, Jingyun Luo, Yingjie Xiao\",\"doi\":\"10.1007/s11032-024-01454-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>With the improvement of high-throughput technologies in recent years, large multi-dimensional plant omics data have been produced, and big-data-driven yield prediction research has received increasing attention. Machine learning offers promising computational and analytical solutions to interpret the biological meaning of large amounts of data in crops. In this study, we utilized multi-omics datasets from 156 maize recombinant inbred lines, containing 2496 single nucleotide polymorphisms (SNPs), 46 image traits (i-traits) from 16 developmental stages obtained through an automatic phenotyping platform, and 133 primary metabolites. Based on benchmark tests with different types of prediction models, some machine learning methods, such as Partial Least Squares (PLS), Random Forest (RF), and Gaussian process with Radial basis function kernel (GaussprRadial), achieved better prediction for maize yield, albeit slight difference for method preferences among i-traits, genomic, and metabolic data. We found that better yield prediction may be caused by various capabilities in ranking and filtering data features, which is found to be linked with biological meaning such as photosynthesis-related or kernel development-related regulations. Finally, by integrating multiple omics data with the RF machine learning approach, we can further improve the prediction accuracy of grain yield from 0.32 to 0.43. Our research provides new ideas for the application of plant omics data and artificial intelligence approaches to facilitate crop genetic improvements.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at 10.1007/s11032-024-01454-z.</p>\",\"PeriodicalId\":18769,\"journal\":{\"name\":\"Molecular Breeding\",\"volume\":\"44 2\",\"pages\":\"14\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2024-02-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10853138/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Molecular Breeding\",\"FirstCategoryId\":\"97\",\"ListUrlMain\":\"https://doi.org/10.1007/s11032-024-01454-z\",\"RegionNum\":3,\"RegionCategory\":\"农林科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/2/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"AGRONOMY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Molecular Breeding","FirstCategoryId":"97","ListUrlMain":"https://doi.org/10.1007/s11032-024-01454-z","RegionNum":3,"RegionCategory":"农林科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/2/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"AGRONOMY","Score":null,"Total":0}
Multi-omics assists genomic prediction of maize yield with machine learning approaches.
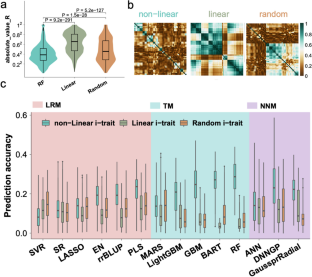
With the improvement of high-throughput technologies in recent years, large multi-dimensional plant omics data have been produced, and big-data-driven yield prediction research has received increasing attention. Machine learning offers promising computational and analytical solutions to interpret the biological meaning of large amounts of data in crops. In this study, we utilized multi-omics datasets from 156 maize recombinant inbred lines, containing 2496 single nucleotide polymorphisms (SNPs), 46 image traits (i-traits) from 16 developmental stages obtained through an automatic phenotyping platform, and 133 primary metabolites. Based on benchmark tests with different types of prediction models, some machine learning methods, such as Partial Least Squares (PLS), Random Forest (RF), and Gaussian process with Radial basis function kernel (GaussprRadial), achieved better prediction for maize yield, albeit slight difference for method preferences among i-traits, genomic, and metabolic data. We found that better yield prediction may be caused by various capabilities in ranking and filtering data features, which is found to be linked with biological meaning such as photosynthesis-related or kernel development-related regulations. Finally, by integrating multiple omics data with the RF machine learning approach, we can further improve the prediction accuracy of grain yield from 0.32 to 0.43. Our research provides new ideas for the application of plant omics data and artificial intelligence approaches to facilitate crop genetic improvements.
Supplementary information: The online version contains supplementary material available at 10.1007/s11032-024-01454-z.
期刊介绍:
Molecular Breeding is an international journal publishing papers on applications of plant molecular biology, i.e., research most likely leading to practical applications. The practical applications might relate to the Developing as well as the industrialised World and have demonstrable benefits for the seed industry, farmers, processing industry, the environment and the consumer.
All papers published should contribute to the understanding and progress of modern plant breeding, encompassing the scientific disciplines of molecular biology, biochemistry, genetics, physiology, pathology, plant breeding, and ecology among others.
Molecular Breeding welcomes the following categories of papers: full papers, short communications, papers describing novel methods and review papers. All submission will be subject to peer review ensuring the highest possible scientific quality standards.
Molecular Breeding core areas:
Molecular Breeding will consider manuscripts describing contemporary methods of molecular genetics and genomic analysis, structural and functional genomics in crops, proteomics and metabolic profiling, abiotic stress and field evaluation of transgenic crops containing particular traits. Manuscripts on marker assisted breeding are also of major interest, in particular novel approaches and new results of marker assisted breeding, QTL cloning, integration of conventional and marker assisted breeding, and QTL studies in crop plants.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
