Rajarshi Bhattacharjee, Gregory Dexter, Petros Drineas, Cameron Musco, Archan Ray
{"title":"通过随机抽样实现次线性时间特征值逼近","authors":"Rajarshi Bhattacharjee, Gregory Dexter, Petros Drineas, Cameron Musco, Archan Ray","doi":"10.1007/s00453-024-01208-5","DOIUrl":null,"url":null,"abstract":"<div><p>We study the problem of approximating the eigenspectrum of a symmetric matrix <span>\\(\\textbf{A} \\in \\mathbb {R}^{n \\times n}\\)</span> with bounded entries (i.e., <span>\\(\\Vert \\textbf{A}\\Vert _{\\infty } \\le 1\\)</span>). We present a simple sublinear time algorithm that approximates all eigenvalues of <span>\\(\\textbf{A}\\)</span> up to additive error <span>\\(\\pm \\epsilon n\\)</span> using those of a randomly sampled <span>\\({\\tilde{O}}\\left( \\frac{\\log ^3 n}{\\epsilon ^3}\\right) \\times {{\\tilde{O}}}\\left( \\frac{\\log ^3 n}{\\epsilon ^3}\\right) \\)</span> principal submatrix. Our result can be viewed as a concentration bound on the complete eigenspectrum of a random submatrix, significantly extending known bounds on just the singular values (the magnitudes of the eigenvalues). We give improved error bounds of <span>\\(\\pm \\epsilon \\sqrt{\\text {nnz}(\\textbf{A})}\\)</span> and <span>\\(\\pm \\epsilon \\Vert \\textbf{A}\\Vert _F\\)</span> when the rows of <span>\\(\\textbf{A}\\)</span> can be sampled with probabilities proportional to their sparsities or their squared <span>\\(\\ell _2\\)</span> norms respectively. Here <span>\\(\\text {nnz}(\\textbf{A})\\)</span> is the number of non-zero entries in <span>\\(\\textbf{A}\\)</span> and <span>\\(\\Vert \\textbf{A}\\Vert _F\\)</span> is its Frobenius norm. Even for the strictly easier problems of approximating the singular values or testing the existence of large negative eigenvalues (Bakshi, Chepurko, and Jayaram, FOCS ’20), our results are the first that take advantage of non-uniform sampling to give improved error bounds. From a technical perspective, our results require several new eigenvalue concentration and perturbation bounds for matrices with bounded entries. Our non-uniform sampling bounds require a new algorithmic approach, which judiciously zeroes out entries of a randomly sampled submatrix to reduce variance, before computing the eigenvalues of that submatrix as estimates for those of <span>\\(\\textbf{A}\\)</span>. We complement our theoretical results with numerical simulations, which demonstrate the effectiveness of our algorithms in practice.</p></div>","PeriodicalId":50824,"journal":{"name":"Algorithmica","volume":"86 6","pages":"1764 - 1829"},"PeriodicalIF":0.7000,"publicationDate":"2024-02-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Sublinear Time Eigenvalue Approximation via Random Sampling\",\"authors\":\"Rajarshi Bhattacharjee, Gregory Dexter, Petros Drineas, Cameron Musco, Archan Ray\",\"doi\":\"10.1007/s00453-024-01208-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>We study the problem of approximating the eigenspectrum of a symmetric matrix <span>\\\\(\\\\textbf{A} \\\\in \\\\mathbb {R}^{n \\\\times n}\\\\)</span> with bounded entries (i.e., <span>\\\\(\\\\Vert \\\\textbf{A}\\\\Vert _{\\\\infty } \\\\le 1\\\\)</span>). We present a simple sublinear time algorithm that approximates all eigenvalues of <span>\\\\(\\\\textbf{A}\\\\)</span> up to additive error <span>\\\\(\\\\pm \\\\epsilon n\\\\)</span> using those of a randomly sampled <span>\\\\({\\\\tilde{O}}\\\\left( \\\\frac{\\\\log ^3 n}{\\\\epsilon ^3}\\\\right) \\\\times {{\\\\tilde{O}}}\\\\left( \\\\frac{\\\\log ^3 n}{\\\\epsilon ^3}\\\\right) \\\\)</span> principal submatrix. Our result can be viewed as a concentration bound on the complete eigenspectrum of a random submatrix, significantly extending known bounds on just the singular values (the magnitudes of the eigenvalues). We give improved error bounds of <span>\\\\(\\\\pm \\\\epsilon \\\\sqrt{\\\\text {nnz}(\\\\textbf{A})}\\\\)</span> and <span>\\\\(\\\\pm \\\\epsilon \\\\Vert \\\\textbf{A}\\\\Vert _F\\\\)</span> when the rows of <span>\\\\(\\\\textbf{A}\\\\)</span> can be sampled with probabilities proportional to their sparsities or their squared <span>\\\\(\\\\ell _2\\\\)</span> norms respectively. Here <span>\\\\(\\\\text {nnz}(\\\\textbf{A})\\\\)</span> is the number of non-zero entries in <span>\\\\(\\\\textbf{A}\\\\)</span> and <span>\\\\(\\\\Vert \\\\textbf{A}\\\\Vert _F\\\\)</span> is its Frobenius norm. Even for the strictly easier problems of approximating the singular values or testing the existence of large negative eigenvalues (Bakshi, Chepurko, and Jayaram, FOCS ’20), our results are the first that take advantage of non-uniform sampling to give improved error bounds. From a technical perspective, our results require several new eigenvalue concentration and perturbation bounds for matrices with bounded entries. Our non-uniform sampling bounds require a new algorithmic approach, which judiciously zeroes out entries of a randomly sampled submatrix to reduce variance, before computing the eigenvalues of that submatrix as estimates for those of <span>\\\\(\\\\textbf{A}\\\\)</span>. We complement our theoretical results with numerical simulations, which demonstrate the effectiveness of our algorithms in practice.</p></div>\",\"PeriodicalId\":50824,\"journal\":{\"name\":\"Algorithmica\",\"volume\":\"86 6\",\"pages\":\"1764 - 1829\"},\"PeriodicalIF\":0.7000,\"publicationDate\":\"2024-02-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Algorithmica\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s00453-024-01208-5\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Algorithmica","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s00453-024-01208-5","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Sublinear Time Eigenvalue Approximation via Random Sampling
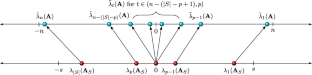
We study the problem of approximating the eigenspectrum of a symmetric matrix \(\textbf{A} \in \mathbb {R}^{n \times n}\) with bounded entries (i.e., \(\Vert \textbf{A}\Vert _{\infty } \le 1\)). We present a simple sublinear time algorithm that approximates all eigenvalues of \(\textbf{A}\) up to additive error \(\pm \epsilon n\) using those of a randomly sampled \({\tilde{O}}\left( \frac{\log ^3 n}{\epsilon ^3}\right) \times {{\tilde{O}}}\left( \frac{\log ^3 n}{\epsilon ^3}\right) \) principal submatrix. Our result can be viewed as a concentration bound on the complete eigenspectrum of a random submatrix, significantly extending known bounds on just the singular values (the magnitudes of the eigenvalues). We give improved error bounds of \(\pm \epsilon \sqrt{\text {nnz}(\textbf{A})}\) and \(\pm \epsilon \Vert \textbf{A}\Vert _F\) when the rows of \(\textbf{A}\) can be sampled with probabilities proportional to their sparsities or their squared \(\ell _2\) norms respectively. Here \(\text {nnz}(\textbf{A})\) is the number of non-zero entries in \(\textbf{A}\) and \(\Vert \textbf{A}\Vert _F\) is its Frobenius norm. Even for the strictly easier problems of approximating the singular values or testing the existence of large negative eigenvalues (Bakshi, Chepurko, and Jayaram, FOCS ’20), our results are the first that take advantage of non-uniform sampling to give improved error bounds. From a technical perspective, our results require several new eigenvalue concentration and perturbation bounds for matrices with bounded entries. Our non-uniform sampling bounds require a new algorithmic approach, which judiciously zeroes out entries of a randomly sampled submatrix to reduce variance, before computing the eigenvalues of that submatrix as estimates for those of \(\textbf{A}\). We complement our theoretical results with numerical simulations, which demonstrate the effectiveness of our algorithms in practice.
期刊介绍:
Algorithmica is an international journal which publishes theoretical papers on algorithms that address problems arising in practical areas, and experimental papers of general appeal for practical importance or techniques. The development of algorithms is an integral part of computer science. The increasing complexity and scope of computer applications makes the design of efficient algorithms essential.
Algorithmica covers algorithms in applied areas such as: VLSI, distributed computing, parallel processing, automated design, robotics, graphics, data base design, software tools, as well as algorithms in fundamental areas such as sorting, searching, data structures, computational geometry, and linear programming.
In addition, the journal features two special sections: Application Experience, presenting findings obtained from applications of theoretical results to practical situations, and Problems, offering short papers presenting problems on selected topics of computer science.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
