{"title":"对有缺失响应的线性回归模型进行积刀模型平均化","authors":"Jie Zeng, Weihu Cheng, Guozhi Hu","doi":"10.1007/s42952-024-00259-2","DOIUrl":null,"url":null,"abstract":"<p>We consider model averaging estimation problem in the linear regression model with missing response data, that allows for model misspecification. Based on the ‘complete’ data set for the response variable after inverse propensity score weighted imputation, we construct a leave-one-out cross-validation criterion for allocating model weights, where the propensity score model is estimated by the covariate balancing propensity score method. We derive some theoretical results to justify the proposed strategy. Firstly, when all candidate outcome regression models are misspecified, our procedures are proved to achieve optimality in terms of asymptotically minimizing the squared loss. Secondly, when the true outcome regression model is among the set of candidate models, the resulting model averaging estimators of the regression parameters are shown to be root-<i>n</i> consistent. Simulation studies provide evidence of the superiority of our methods over other existing model averaging methods, even when the propensity score model is misspecified. As an illustration, the approach is further applied to study the CD4 data.</p>","PeriodicalId":49992,"journal":{"name":"Journal of the Korean Statistical Society","volume":"35 1","pages":""},"PeriodicalIF":0.8000,"publicationDate":"2024-02-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Jackknife model averaging for linear regression models with missing responses\",\"authors\":\"Jie Zeng, Weihu Cheng, Guozhi Hu\",\"doi\":\"10.1007/s42952-024-00259-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>We consider model averaging estimation problem in the linear regression model with missing response data, that allows for model misspecification. Based on the ‘complete’ data set for the response variable after inverse propensity score weighted imputation, we construct a leave-one-out cross-validation criterion for allocating model weights, where the propensity score model is estimated by the covariate balancing propensity score method. We derive some theoretical results to justify the proposed strategy. Firstly, when all candidate outcome regression models are misspecified, our procedures are proved to achieve optimality in terms of asymptotically minimizing the squared loss. Secondly, when the true outcome regression model is among the set of candidate models, the resulting model averaging estimators of the regression parameters are shown to be root-<i>n</i> consistent. Simulation studies provide evidence of the superiority of our methods over other existing model averaging methods, even when the propensity score model is misspecified. As an illustration, the approach is further applied to study the CD4 data.</p>\",\"PeriodicalId\":49992,\"journal\":{\"name\":\"Journal of the Korean Statistical Society\",\"volume\":\"35 1\",\"pages\":\"\"},\"PeriodicalIF\":0.8000,\"publicationDate\":\"2024-02-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of the Korean Statistical Society\",\"FirstCategoryId\":\"100\",\"ListUrlMain\":\"https://doi.org/10.1007/s42952-024-00259-2\",\"RegionNum\":4,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"STATISTICS & PROBABILITY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of the Korean Statistical Society","FirstCategoryId":"100","ListUrlMain":"https://doi.org/10.1007/s42952-024-00259-2","RegionNum":4,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
Jackknife model averaging for linear regression models with missing responses
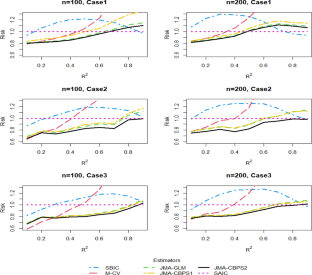
We consider model averaging estimation problem in the linear regression model with missing response data, that allows for model misspecification. Based on the ‘complete’ data set for the response variable after inverse propensity score weighted imputation, we construct a leave-one-out cross-validation criterion for allocating model weights, where the propensity score model is estimated by the covariate balancing propensity score method. We derive some theoretical results to justify the proposed strategy. Firstly, when all candidate outcome regression models are misspecified, our procedures are proved to achieve optimality in terms of asymptotically minimizing the squared loss. Secondly, when the true outcome regression model is among the set of candidate models, the resulting model averaging estimators of the regression parameters are shown to be root-n consistent. Simulation studies provide evidence of the superiority of our methods over other existing model averaging methods, even when the propensity score model is misspecified. As an illustration, the approach is further applied to study the CD4 data.
期刊介绍:
The Journal of the Korean Statistical Society publishes research articles that make original contributions to the theory and methodology of statistics and probability. It also welcomes papers on innovative applications of statistical methodology, as well as papers that give an overview of current topic of statistical research with judgements about promising directions for future work. The journal welcomes contributions from all countries.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
